Today, we’re excited to introduce Miso One, the most emotive voice model in the world.
Miso One is an 8-billion-parameter text-to-speech model for highly expressive speech generation. It emotes like a human and responds faster than a human, with just 110 milliseconds of latency.
We’ve open-sourced the model weights, with API access coming soon.
Hear how Miso One sounds in the thread below.
Come and visit London’s Home of Trophies. 🏆
Book your Stadium Tour at Stamford Bridge now. ⭐️⭐Come and visit London’s Home of Trophies. 🏆
Book your Stadium Tour at Stamford Bridge now. ⭐️⭐Come and visit London’s Home of Trophies. 🏆
Book your Stadium Tour at Stamford Bridge now. ⭐️⭐Come and visit London’s Home of Trophies. 🏆
Book your Stadium Tour at Stamford Bridge now. ⭐️⭐Come and visit London’s Home of Trophies. 🏆
Book your Stadium Tour at Stamford Bridge now. ⭐️⭐Come and visit London’s Home of Trophies. 🏆
Book your Stadium Tour at Stamford Bridge now. ⭐️⭐️
Still wild that Codex doesn’t seem to run regression checks on the metrics that actually matter:
cache hit ratio
context rot
input/output tokens
avg runtime
tool-call stats/behavior
SWE-bench Pro subset score
Every big PR/release should answer one question:
Did the model get worse?
For a product used by millions, this should be table stakes.
This is crazy. The shai hulud exploit is embedding itself in Claude and VSCode to re-execute itself, even after the original packages have been uninstalled.
I'm never installing anything ever again.
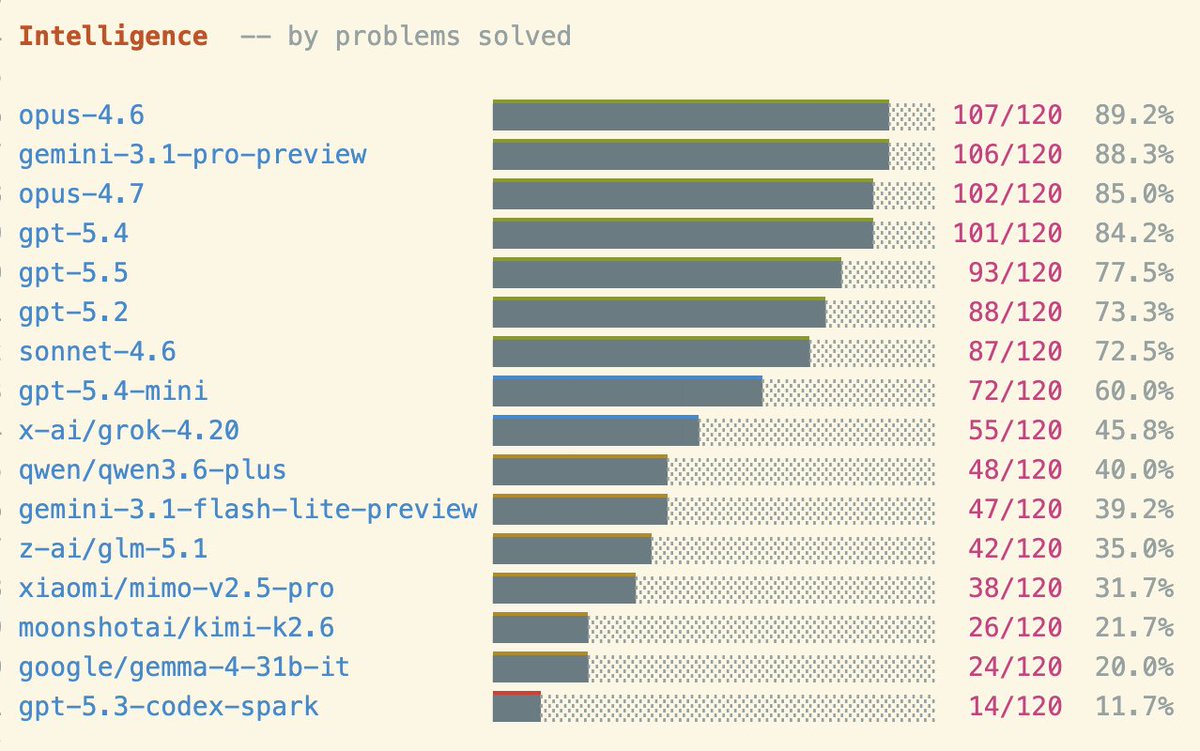
Introducing LamBench . . .
You asked me to make a benchmark, so I made it. It is a simple, old style Q&A consisting of 120 fresh λ-calculus programming questions. Some are easy, like "implement add for λ-encoded nats". Some are harder, like "derive a generic fold for arbitrary λ-encodings".
It measures:
- intelligence (% tasks completed)
- elegance (BLC-length of solutions)
- speed (completion time)
Basically what I care about, other than long context.
I made it today because I was excited about GPT 5.5.
It didn't do too well ):
(My first-day impression is that I can't tell the difference between GPT 5.5 and GPT 5.4. I would be lying if I said otherwise. I'd not be able to distinguish in a blind test. I need more time. It is much faster though.)
This is a new, simple bench, so expect be bugs.
Specially on OpenRouter models. I'll retest soon.
Also, it was born saturated. V2 will be harder...
↓ Link and more charts below ↓
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at https://t.co/GCdiMzk1Dl via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: https://t.co/drlDrxkYtp
🤗 Open Weights: https://t.co/T13Y8i7SDM
1/n
Be Anthropic
> Give people Opus 4.6
> People love it.
> For 2 months you degrade Opus 4.6
> You give back normal Opus 4.6 and call it Opus 4.7.
> People love it.
That's the business model.
HOME.
The Artemis II crew has arrived back on Earth, ending a nearly 10-day journey around the Moon. The trip took them farther into space than humans have ever gone before, and now they're safely home with us.
https://t.co/XmDQwNlCPR
THEY SENT FOUR HUMAN BEINGS 252,756 MILES AWAY, WENT FULLY AROUND THE MOON AND BROUGHT THEM BACK TO LAND IN THE PRECISE LOCATION THEY WANTED
EVERYONE WHO WORKED ON THIS IS THE COOLEST PERSON ON EARTH