We’re a 2-person AI Lab.
Today, we’re releasing our first open-weight text-to-video models trained from scratch (2B params, Apache 2.0, 360p & 720p).
Weights on Hugging Face.
https://t.co/0j7t2oqL4Z
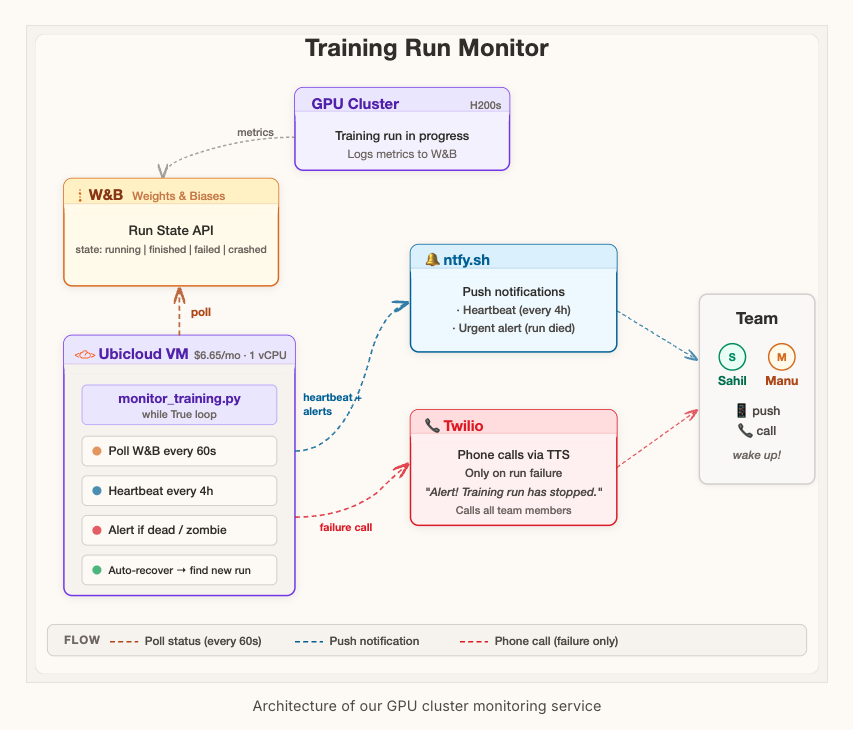
We trained Linum-v2 on a big cluster over the holidays and didn't want to spend the whole time refreshing our Weights & Biases from our phones.
So we built a simple $8/month tool to just call us when something crashed.
Open-sourcing it, in case it can help other foundation model teams. https://t.co/IHSyQ36nMa
Turns out better VAE reconstruction quality can make your diffusion model worse.
We learned this the hard way over 4 months.
Writeup + open-source Image-Video VAE model.
https://t.co/JgX8qpsfKR
We’re a 2-person AI Lab.
Today, we’re releasing our first open-weight text-to-video models trained from scratch (2B params, Apache 2.0, 360p & 720p).
Weights on Hugging Face.
https://t.co/0j7t2oqL4Z
@eigenron all code is open source, so you can dig into the details; but like i said we'll be writing a lot more about the technical specs and how we got here
💪After months of hard work, we're excited to announce our first text-to-video model!
💰Model is free to use.
🤫Discord remains private, as we scale up GPUs.
👉 Waitlist link again in case you missed it -- https://t.co/nK8Sqo77W8
Welcome to YC W23, @schopra909, Manu, and @LinumInc!
Linum is DALL-E for video. With Linum, anyone can create animated videos, starting with just a few prompts.
Check it out at https://t.co/kvElNqaH2m