@kim_X_artist@FoodProfessor Yes because Galen Weston doesn't currently control what goes into stores already. How does the large corporate cock taste Kim?
@ErosVilleneuve@FoodProfessor@TruthLion100 O no, not the dreaded affordable groceries. O lord Galen please stick your cock further down this man's throat so he can gurgle it harder.
@laprairie@FoodProfessor Things like this and Canada Post aren't supposed to be businesses, governments don't run businesses, they are supposed to run services.
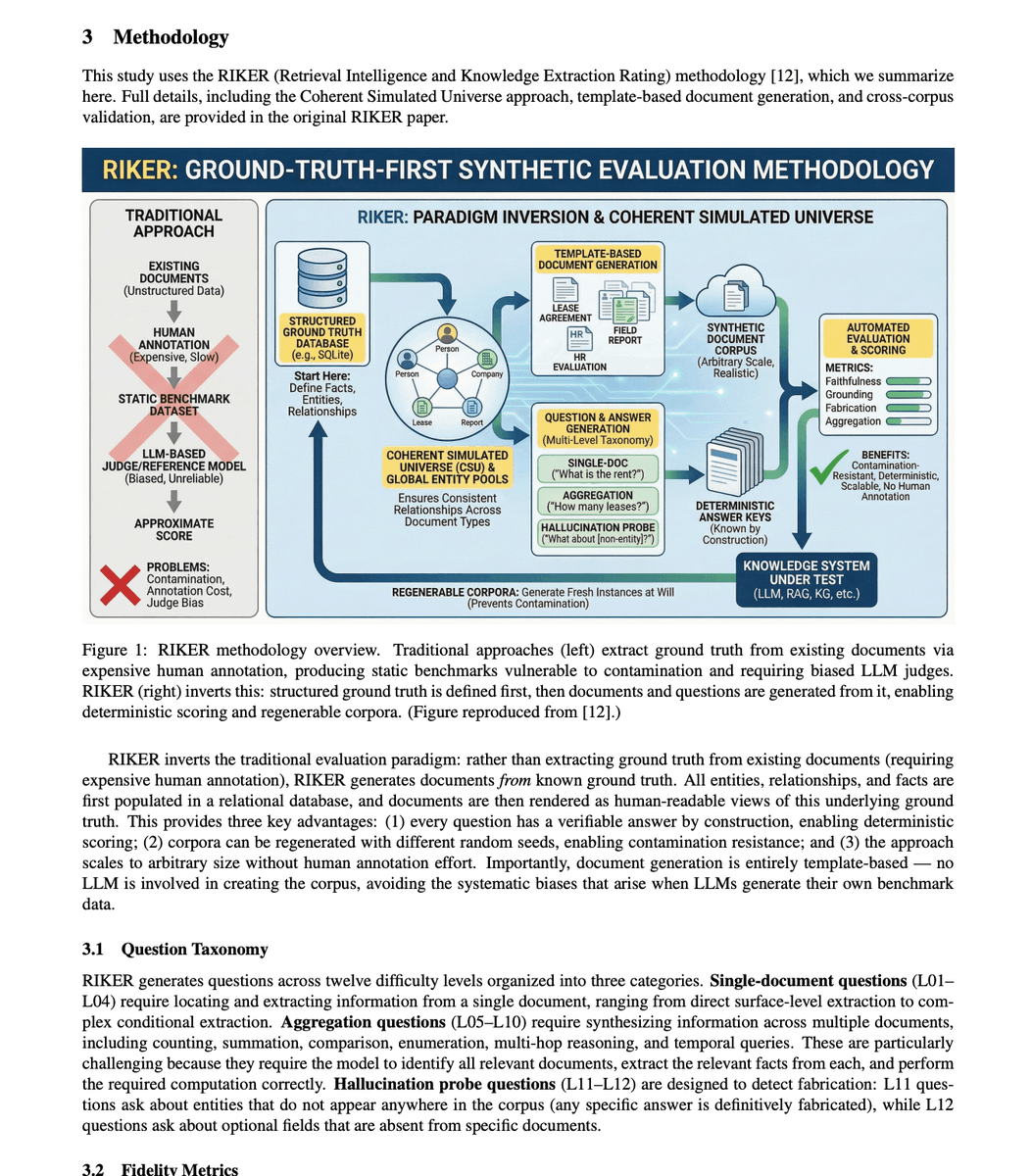
BREAKING: 🚨 Someone just tested 35 AI models across 172 billion tokens of real document questions.
The hallucination numbers should end the "just give it the documents" argument forever.
Here is what the data actually showed.
The best model in the entire study, under perfect conditions, fabricated answers 1.19% of the time. That sounds small until you realize that is the ceiling. The absolute best case. Under optimal settings that almost no real deployment uses.
Typical top models sit at 5 to 7% fabrication on document Q&A. Not on questions from memory. Not on abstract reasoning. On questions where the answer is sitting right there in the document in front of it.
The median across all 35 models tested was around 25%.
One in four answers fabricated, even with the source material provided.
Then they tested what happens when you extend the context window. Every company selling 128K and 200K context as the hallucination solution needs to read this part carefully.
At 200K context length, every single model in the study exceeded 10% hallucination. The rate nearly tripled compared to optimal shorter contexts.
The longer the window people want, the worse the fabrication gets. The exact feature being sold as the fix is making the problem significantly worse.
There is one more finding that does not get talked about enough.
Grounding skill and anti-fabrication skill are completely separate capabilities in these models.
A model that is excellent at finding relevant information in a document is not necessarily good at avoiding making things up. They are measuring two different things that do not reliably correlate. You cannot assume a model that retrieves well also fabricates less.
172 billion tokens. 35 models. The conclusion is the same across all of them.
Handing an LLM the actual document does not solve hallucination. It just changes the shape of it.
An ongoing military investigation has determined that the United States is responsible for a deadly Tomahawk missile strike on an Iranian elementary school, according to US officials and others familiar with the preliminary findings.
https://t.co/C8mmufE6I8
If you are or know a servicemember, including reserves and National Guard, who are concerned about their options in not taking part in a war they feel is illegal or immoral, please contact @CCW4COs or @girights.
Please share.
Tonight, we reached an agreement with the Department of War to deploy our models in their classified network.
In all of our interactions, the DoW displayed a deep respect for safety and a desire to partner to achieve the best possible outcome.
AI safety and wide distribution of benefits are the core of our mission. Two of our most important safety principles are prohibitions on domestic mass surveillance and human responsibility for the use of force, including for autonomous weapon systems. The DoW agrees with these principles, reflects them in law and policy, and we put them into our agreement.
We also will build technical safeguards to ensure our models behave as they should, which the DoW also wanted. We will deploy FDEs to help with our models and to ensure their safety, we will deploy on cloud networks only.
We are asking the DoW to offer these same terms to all AI companies, which in our opinion we think everyone should be willing to accept. We have expressed our strong desire to see things de-escalate away from legal and governmental actions and towards reasonable agreements.
We remain committed to serve all of humanity as best we can. The world is a complicated, messy, and sometimes dangerous place.