Humans excel at estimating their own competence and progress on tasks. But can LLM agents do the same?
With 🧭MAGELLAN, our agent predicts its own learning progress across vast goal spaces, even generalizing to new tasks!
📄Paper: https://t.co/flQADyHsb4
🚀 Introducing 🧭MAGELLAN—our new metacognitive framework for LLM agents! It predicts its own learning progress (LP) in vast natural language goal spaces, enabling efficient exploration of complex domains.🌍✨Learn more: 🔗 https://t.co/uGLBSsOgMn #OpenEndedLearning#LLM#RL
New paper at ICLR 2026! 🎉
"Language and Experience: A Computational Model of Social Learning in Complex Tasks"
We model how humans combine advice from others with direct experience to learn new tasks, and show this enables bidirectional human-AI knowledge transfer.
🧵⤵️
Probably the highest-bang-for-buck direction in RL is developing algorithms that can discover useful temporal abstractions (e.g., Options) entirely from experience, learn models for these temporal abstractions, and plan with them in real time.
That’s why I think curriculum learning matters so much: if you can keep giving the model tasks that teach skills transferable to other tasks, it can climb from easy to hard and push way past its initial capabilities.
3/3
I keep seeing the take that “RL only works if the pretrained model can already solve the task”.
That’s only true in the very narrow case where you’re doing single-task RL with a sparse reward. But that’s not how people actually train LLMs with RL.
1/3
RL only works if the pretrained model can already solve the problem (otherwise there's no reward signal). So RL can't solve any hard problems, and when it appears to it's just thinly disguised brute force.
In practice, they do goal-conditioned RL over many tasks. As long as some tasks produce a reward signal, the model can pick up transferable skills. A reasoning pattern learned on an easy task can suddenly unlock a hard one where the base model had 0% success.
2/3
FLOWERS is offering Master's internships!
@Jeremy__Perez and I are supervising a project combining artificial life and cultural evolution.
We are also offering a position continuing the team's research on discovering sensimotor agency in Lenia.
Check all the topics below!
Come do an internship in the Flowers team!
I’ll supervise two projects: one on curious deep-RL agents that learn a self-representation, and one on modelling real students’ learning with LLMs.
More details soon , and check out the other internships, they’re super cool!
🚀 New internship positions available in the Flowers AI & CogSci lab !!!
Topics: Curiosity-driven deep RL, program synthesis with SWE LLM agents, data science for edTech + other !
Only for students currently enrolled in a master program
Info here: https://t.co/Cv49BOyAj0
🚀 New internship positions available in the Flowers AI & CogSci lab !!!
Topics: Curiosity-driven deep RL, program synthesis with SWE LLM agents, data science for edTech + other !
Only for students currently enrolled in a master program
Info here: https://t.co/Cv49BOyAj0
After four incredible years in the Flowers AI & CogSci Lab, I’m thrilled to share that I’ve officially become a Doctor! 🎓💫
My thesis: “Language as a Cognitive Tool for Open Agents.”
It explores how language helps artificial agents explore, adapt, and learn efficiently.
3 papers from @FlowersINRIA are presented this week at the @ALifeConf , leveraging curiosity-driven AI to explore complex behaviors in #Lenia
All first authors are attending the conference if you want to discuss with them
Link to interactive websites, papers and code below:
Excited to introduce Dreamer 4, an agent that learns to solve complex control tasks entirely inside of its scalable world model! 🌎🤖
Dreamer 4 pushes the frontier of world model accuracy, speed, and learning complex tasks from offline datasets.
co-led with @wilson1yan
We’re excited to introduce ShinkaEvolve: An open-source framework that evolves programs for scientific discovery with unprecedented sample-efficiency.
Blog: https://t.co/zoZlH8jSXc
Code: https://t.co/TlYGSIk2Ek
Like AlphaEvolve and its variants, our framework leverages LLMs to find state-of-the-art solutions to complex problems, but using orders of magnitude fewer resources!
Many evolutionary AI systems are powerful but act like brute-force engines, burning thousands of samples to find good solutions. This makes discovery slow and expensive. We took inspiration from the efficiency of nature. ‘Shinka’ (進化) is Japanese for evolution, and we designed our system to be just as resourceful.
On the classic circle packing optimization problem, ShinkaEvolve discovered a new state-of-the-art solution using only 150 samples. This is a big leap in efficiency compared to previous methods that required thousands of evaluations.
We applied ShinkaEvolve to a diverse set of hard problems with real-world applications:
1/ AIME Math Reasoning: It evolved sophisticated agentic scaffolds that significantly outperform strong baselines, discovering an entire Pareto frontier of solutions trading performance for efficiency.
2/ Competitive Programming: On ALE-Bench (a benchmark for NP-Hard optimization problems), ShinkaEvolve took the best existing agent's solutions and improved them, turning a 5th place solution on one task into a 2nd place leaderboard rank in a competitive programming competition.
3/ LLM Training: We even turned ShinkaEvolve inward to improve LLMs themselves. It tackled the open challenge of designing load balancing losses for Mixture-of-Experts (MoE) models. It discovered a novel loss function that leads to better expert specialization and consistently improves model performance and perplexity.
ShinkaEvolve achieves its remarkable sample-efficiency through three key innovations that work together: (1) an adaptive parent sampling strategy to balance exploration and exploitation, (2) novelty-based rejection filtering to avoid redundant work, and (3) a bandit-based LLM ensemble that dynamically picks the best model for the job.
By making ShinkaEvolve open-source and highly sample-efficient, our goal is to democratize access to advanced, open-ended discovery tools. Our vision for ShinkaEvolve is to be an easy-to-use companion tool to help scientists and engineers with their daily work. We believe that building more efficient, nature-inspired systems is key to unlocking the future of AI-driven scientific research. We are excited to see what the community builds with it!
Learn more in our technical report: https://t.co/yzag3wd4jL
Just setting up my art exhibition for the week in MIT's Stata center (4th floor, 32-G409)
Come play with a visual modular synthesizer built from a physical compositional neural net
Plug cables, twist knobs and shape amazing patterns in real time!!
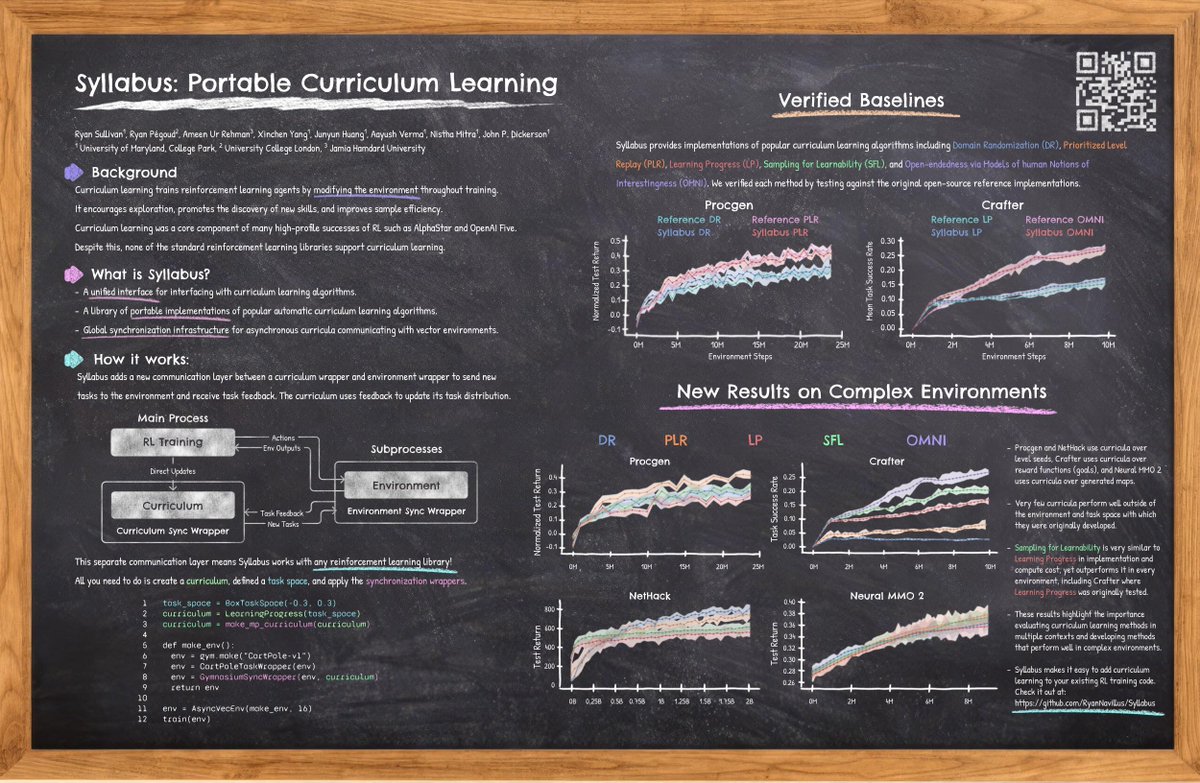
We just released a new version of Syllabus! We have a demo notebook to help you get started, usability improvements, an implementation of Robust PLR, new versions of learning progress, and more!
Check out this thread to learn how to get started with curriculum learning (CL)! 🧵
Harder, Better, Faster, Stronger, Real-time! We are excited to reveal Genie 3, our most capable real-time foundational world model. Fantastic cross-team effort led by @jparkerholder and @shlomifruchter. Below some interactive worlds and capabilities that were highlights for me 🌎👇
✨Introducing SENSEI✨ We bring semantically meaningful exploration to model-based RL using VLMs.
With intrinsic rewards for novel yet useful behaviors, SENSEI showcases strong exploration in MiniHack, Pokémon Red & Robodesk.
Accepted at ICML 2025🎉
Joint work with @cgumbsch
🧵
I’m attending #ICML this week! We’ll be presenting MAGELLAN during the poster session on Thursday with @CartaThomas2 & @ClementRomac
If you’re not in Vancouver, we recorded a talk presenting the paper last week, it’s available on YouTube (link below)
I'm attending ICML 2025 this week in Vancouver where we're presenting our MAGELLAN paper along with @LorisGaven and @CartaThomas2!
📅 Come discuss at our poster session on July 17 at 11 am East Exhibition Hall A-B E-2803
Or reach out for a chat!
https://t.co/Uk8HKmcOHM