Our paper on the benefits of actual RL for In-Context RL has been accepted to RLC!
Looking forward to attending @RL_Conference and discussing the work there.
LLMs are amazing because they can learn in context — read, adapt, and act.
Can we do the same for reinforcement learning? That’s the promise of In-Context RL (ICRL).
But existing offline ICRL methods don’t even optimize rewards.
Our new paper shows why RL matters
🧵
Happy to share that I’m officially starting my PhD in Reinforcement Learning and Robotics at ETH Zurich under the supervision of Prof. Robert Katzschmann @katzschmann.
It’s been quite a journey to get to this point, and I’m excited for what’s ahead!
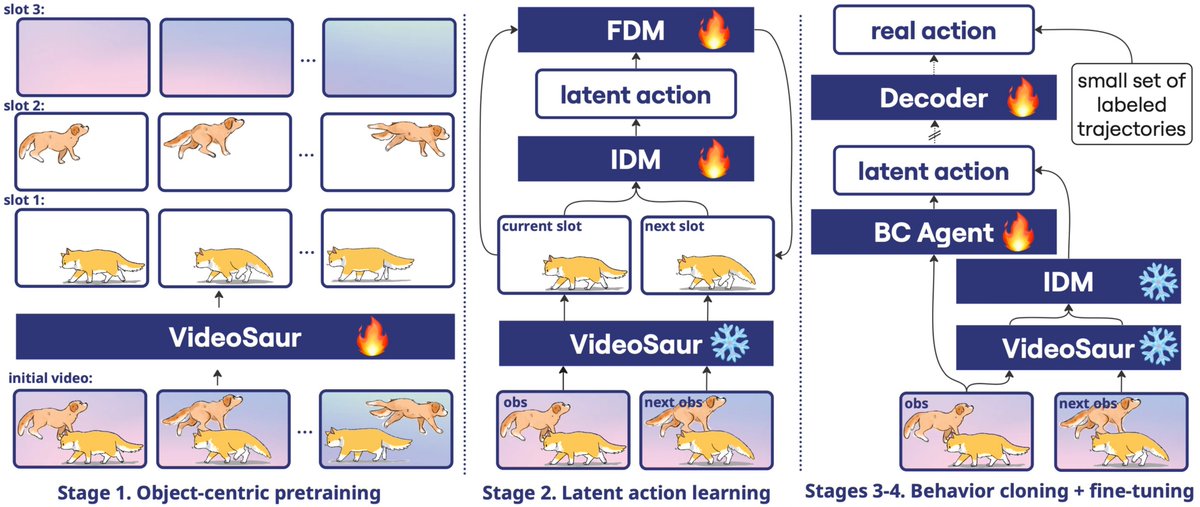
🤩Excited to share our #AAAI2026 Oral on #EmbodiedAI:
How can robots learn from noisy, unlabeled videos—like those on the internet—without action labels?
Our new work, Object-Centric Latent Action Learning, tackles exactly this.
Thread ↓
Don’t want to spam your feeds, but I’m incredibly thankful to the AI community for all the feedback and support on my last tweet. I didn’t expect so many responses -- really happy to be part of such a brilliant community. Thank you so, so much!
@amirhkarimi_@hllo_wrld@_rockt@robertarail Thank you very much for your suggestion. I'm afraid Canada is not an option for me as well as US (and UK now) due to the visa difficulties:(
I’m asking for help. I was meant to start my PhD with @_rockt and @robertarail at UCL, but my UK background check was refused. My appeal seems unlikely to succeed, so I’m urgently searching for any PhD or research positions in academia or industry. Any help is appreciated.
@sarsanaee@_rockt@robertarail Yes, that's ATAS. They do not provide any reasons but most likely it is due to the combination of my research area and nationality (I know other people with the same issue who didn't get ATAS). I can't reapply for 3 months. Was waiting for their decision 6 months
🚀 Introducing cadrille: a new SOTA model for CAD reconstruction from images, point clouds, and text—all in one framework with the use of RLVR.
Multimodal inputs + RLVR = clean, editable 3D models.
🧵👇
LLMs are amazing because they can learn in context — read, adapt, and act.
Can we do the same for reinforcement learning? That’s the promise of In-Context RL (ICRL).
But existing offline ICRL methods don’t even optimize rewards.
Our new paper shows why RL matters
🧵
🧠 We believe offline ICRL should actually do RL.
Our results show that reward-aware training improves many crucial aspects of ICRL.
Check out the paper here: https://t.co/DRDYbtj3Cb