🤩Excited to share our #AAAI2026 Oral on #EmbodiedAI:
How can robots learn from noisy, unlabeled videos—like those on the internet—without action labels?
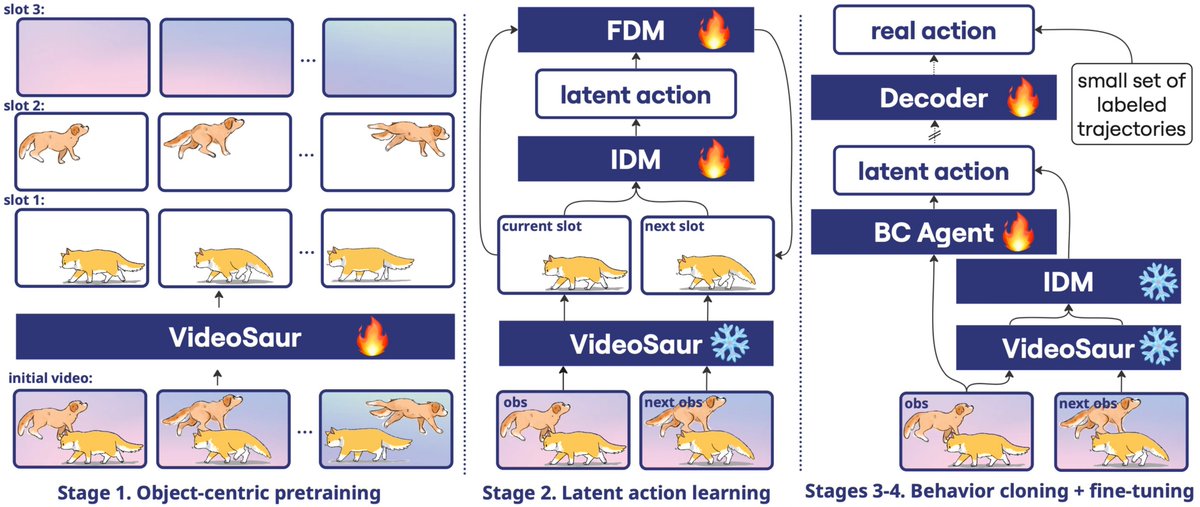
Our new work, Object-Centric Latent Action Learning, tackles exactly this.
Thread ↓
New paper out! 🎉 SHIFT: Steering Hidden Intermediates in Flow Transformers — activation steering, but for DiT diffusion models.
https://t.co/hlRvg6Si3P
🧵 thread:
Is it possible to build a multi-domain action model capable of adapting to unseen dynamics?
Check out our new #ICLR2026 paper! We pushed in-context RL scaling further and released Vintix II.
👇👇👇
🤩Excited to share our #AAAI2026 Oral on #EmbodiedAI:
How can robots learn from noisy, unlabeled videos—like those on the internet—without action labels?
Our new work, Object-Centric Latent Action Learning, tackles exactly this.
Thread ↓
Thanks to @RealAAAI for the conference. So many interesting new connections. Hope that now more people are aware of the beauty of latent actions for robotics 🤖
#AAAI2026#robots#ai#aaai#Singapour
Don't forget to visit my oral or/and poster today on scalable imitation learning via object-centric pretraining.
Oral: Garnet 218 @ 9:50 am
Poster: Hall 4
Also, feel free to reach out if you want to chat about continual, imitation and/or reinforcement learning while at AAAI!
🤩Excited to share our #AAAI2026 Oral on #EmbodiedAI:
How can robots learn from noisy, unlabeled videos—like those on the internet—without action labels?
Our new work, Object-Centric Latent Action Learning, tackles exactly this.
Thread ↓
🤩Excited to share our #AAAI2026 Oral on #EmbodiedAI:
How can robots learn from noisy, unlabeled videos—like those on the internet—without action labels?
Our new work, Object-Centric Latent Action Learning, tackles exactly this.
Thread ↓
9/9 If you're at AAAI or interested in world models, imitation learning, or object-centric RL, check out our paper: https://t.co/A1HJN4coj4
Oral session: Jan 22, 9:30-10:00 Garnet 218
Poster session: Jan 22, Hall 4
Code (coming soon): https://t.co/bKLOS0tV4V
We released 87 hours of @LeRobotHF SO 100/101 datasets.
It is a unified, cleaned, and annotated repackage of 598 open-source community datasets (SO100 and SO101), totaling 22,709 episodes, ~9.4M frames, and 563 tasks.
I’m asking for help. I was meant to start my PhD with @_rockt and @robertarail at UCL, but my UK background check was refused. My appeal seems unlikely to succeed, so I’m urgently searching for any PhD or research positions in academia or industry. Any help is appreciated.
🚀 Introducing cadrille: a new SOTA model for CAD reconstruction from images, point clouds, and text—all in one framework with the use of RLVR.
Multimodal inputs + RLVR = clean, editable 3D models.
🧵👇
LLMs are amazing because they can learn in context — read, adapt, and act.
Can we do the same for reinforcement learning? That’s the promise of In-Context RL (ICRL).
But existing offline ICRL methods don’t even optimize rewards.
Our new paper shows why RL matters
🧵