MD➡️Fire Dept EMS➡️ General Surgeon ⚡️➡️Market Enforcement Examiner➡️ Data Enthusiast. Author of benford_py. In love with a Dermatology Goddess. Father of 3.
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
Scientists have created one of the most detailed 3D reconstructions of a human cell (eukaryotic cell) ever produced.
This groundbreaking model, often termed a "Cellular Landscape Cross-Section Through a Eukaryotic Cell," combines data from X-ray tomography, nuclear magnetic resonance (NMR), and cryo-electron microscopy to map molecular structures in extreme detail.
Um cara embolsou R$36.900 no Polymarket indo até o sensor meteorológico que a plataforma usava como referência, um termômetro perto de uma pista no aeroporto de Paris, e apontando um secador de cabelo para ele.
Entrou com US$ 2.000 a 5 centavos. Comprou YES nas metas de temperatura. Aqueceu o sensor. Embolsou o lucro e sumiu.
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
This feels like cheating.
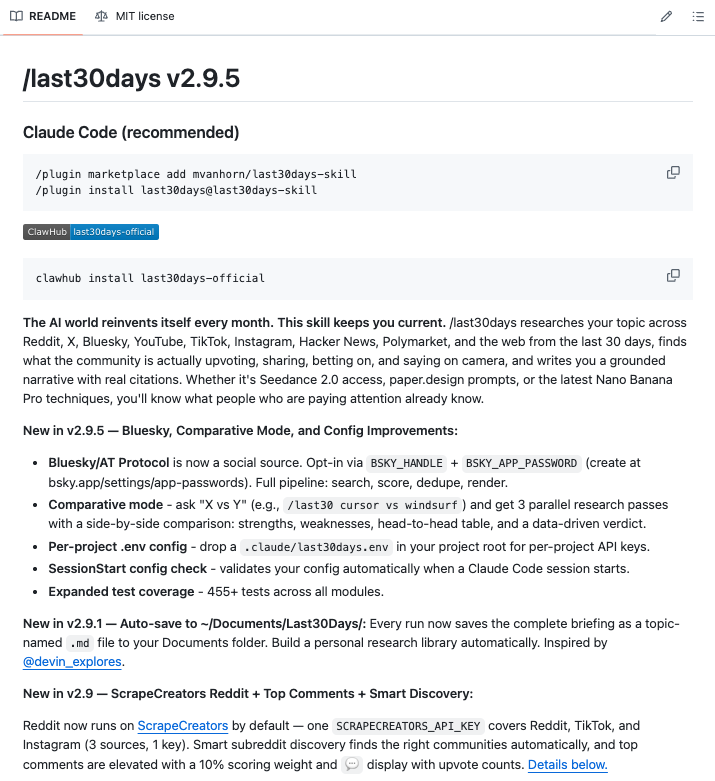
Someone built a Claude Code skill that scans Reddit and X from the last 30 days on any topic you give it, then writes you copy-paste-ready prompts based on what the community has actually figured out not what was working six months ago.
You type /last30days prompting techniques for ChatGPT for legal questions and it comes back with the top patterns real lawyers and power users are using right now, complete with a fully written prompt you can drop in and use immediately.
No more Googling, no more digging through threads, no more prompts that worked last year but got patched out.
It works for anything - Midjourney techniques, Suno music prompts, Cursor rules, trending rap songs, whatever you need to know what people are actually saying about right now.
100% Open Source. MIT License.
Link in the comments.
Andrej Karpathy (@karpathy) — co-founded OpenAI, led AI at Tesla, coined "vibe coding."
In 4 minutes he explains why software is changing - and why Claude Skills, MCP servers, and AI agents aren't hype anymore.
They're the foundation of how software gets built from now on.
Imo, worth every second (i've added subtitles)👇
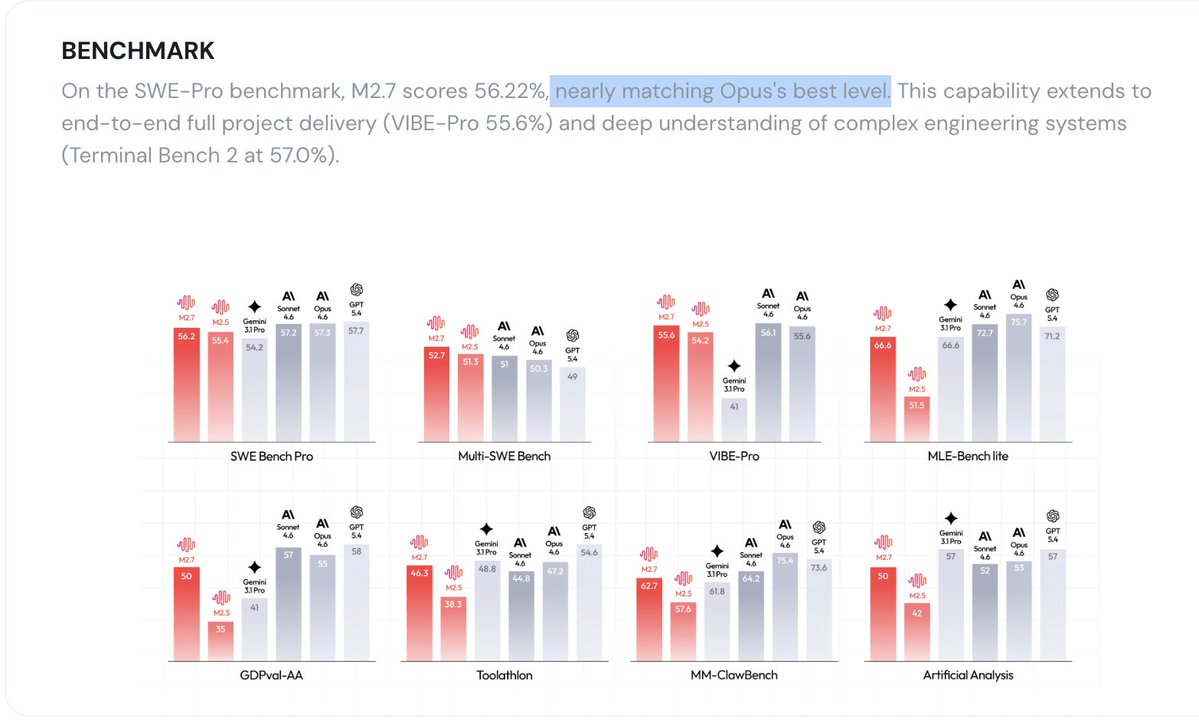
fuck me china just launched the 1st AI model that autonomously built itself... and its as good as claude opus 4.6 and gpt-5.4
- minimax M2.7 trained itself through 100+ rounds of autonomous self-improvement. 30% gain. No humans involved - what the actual f*ck
- model now handles 30-50% of the AI lab's OWN AI research
- beats gemini 3.1 at coding and pretty much matches opus 4.6 + gpt 5.4 😶 (china used to lag now they match
- doesn't require crazy hardware to run (single a30 gpu)
- absolutely CRUSHES tasks: financial modelling, coding, openclaw - one-shotted
the chinese have officially caught up. self-improving ai is a real thing.
all researchers did was set an objective and the model figured the rest out.
i wasn't expecting this from minimax. im now wondering wtf deepseek is going to be like.
New course: Agent Memory: Building Memory-Aware Agents, built in partnership with @Oracle and taught by @richmondalake and Nacho Martínez.
Many agents work well within a single session but their memory resets once the session ends. Consider a research agent working on dozens of papers across multiple days: without memory, it has no way to store and retrieve what it learned across sessions. This short course teaches you to build a memory system that enables agents to persist memory and thereby learn across sessions.
You'll design a Memory Manager that handles different memory types, implement semantic tool retrieval that scales without bloating the context, and build write-back pipelines that let your agent autonomously update and refine what it knows over time.
Skills you'll gain:
- Build persistent memory stores for different agent memory types
- Implement a Memory Manager that orchestrates how your agent reads, writes, and retrieves memory
- Treat tools as procedural memory and retrieve only relevant ones at inference time using semantic search
Join and learn to build agents that remember and improve over time!
https://t.co/nxNSEHGmr9
NVIDIA and Unsloth just dropped one of the best practical guides on building RL environments from scratch, and it fills the gaps that most tutorials skip entirely.
Covers:
- Why RL environments matter + how to build them
- When RL is better than SFT
- GRPO and RL best practices
- How verifiable rewards and RLVR work
I'm excited to announce Context Hub, an open tool that gives your coding agent the up-to-date API documentation it needs. Install it and prompt your agent to use it to fetch curated docs via a simple CLI. (See image.)
Why this matters: Coding agents often use outdated APIs and hallucinate parameters. For example, when I ask Claude Code to call OpenAI's GPT-5.2, it uses the older chat completions API instead of the newer responses API, even though the newer one has been out for a year. Context Hub solves this.
Context Hub is also designed to get smarter over time. Agents can annotate docs with notes — if your agent discovers a workaround, it can save it and doesn't have to rediscover it next session. Longer term, we're building toward agents sharing what they learn with each other, so the whole community benefits.
Thanks Rohit Prsad and Xin Ye for working with me on this!
npm install -g @aisuite/chub
GitHub: https://t.co/OCkyxXQMCq
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
https://t.co/WAz8aIztKT
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.
🚨 BREAKING: Alibaba just open-sourced something the AI agent space has quietly been begging for.
It's called OpenSandbox, a full execution platform that gives any AI agent a secure, isolated environment to run code, browse the web, and train models.
One unified API. Every language. Any infrastructure.
Built on the same internal stack Alibaba runs its own AI workloads on at scale.
The platform spins up four types of sandboxes:
→ Coding Agents — write, test, debug code in stateful sessions
→ GUI Agents — full VNC desktops for agents that need to interact with visual interfaces
→ Code Execution — high-performance runtimes for scripts and computational tasks
→ RL Training — isolated environments for reinforcement learning loops
SDKs ship in Python, TypeScript, and Java/Kotlin today. C# and Go are on the roadmap.
Docker handles your local dev. Kubernetes handles your production-scale distributed runs.
Setup takes three commands:
→ pip install opensandbox-server
→ opensandbox-server init-config
→ opensandbox-server
Server boots, API is live, agents have a sandbox.
100% Open Source. Apache 2.0 license.
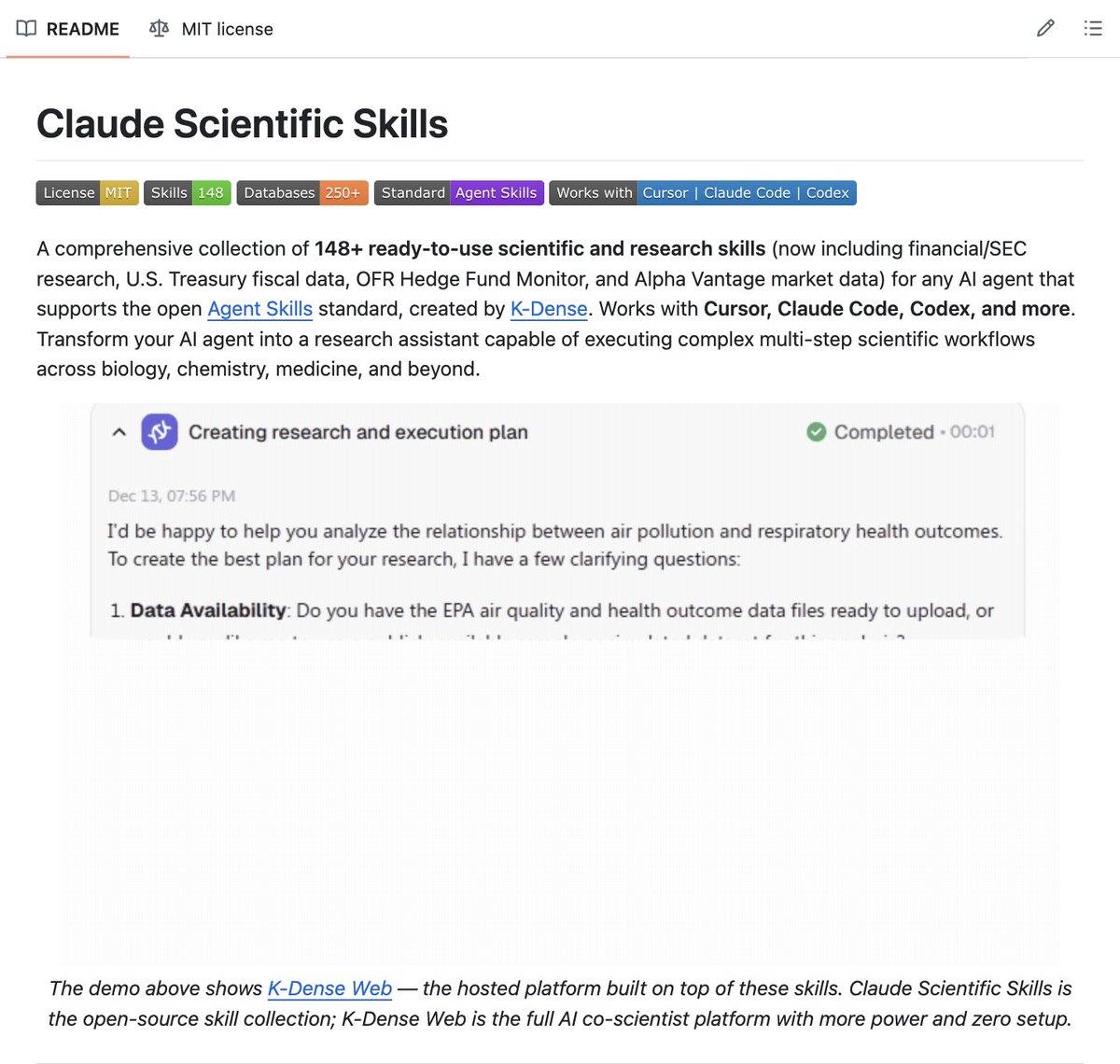
🚨 BREAKING: The most important Claude plugin in existence just dropped on GitHub and nobody is talking about it.
It's called claude-scientific-skills.
140 scientific skills across every major research domain baked into one plugin.
Install it once. Claude becomes a full AI research scientist permanently.
Here's what it can run from a single prompt:
→ Full drug discovery pipelines with real bioactive compound queries
→ Single-cell RNA sequencing analysis with Scanpy
→ Clinical variant annotation with ClinVar and Ensembl
→ Molecular docking against AlphaFold structures via DiffDock
→ Patient to trial matching via live ClinicalTrials. gov data
→ Publication-ready PDF clinical reports generated automatically
Bioinformatics. Cheminformatics. Proteomics. Quantum computing. Medical imaging. Laboratory automation.
All connected to the databases and tools scientists actually use.
One prompt. Real science. Actual results.
This is not a chatbot anymore.
/plugin install scientific-skills@claude-scientific-skills
100% Open Source. MIT License.
Link in the comments.
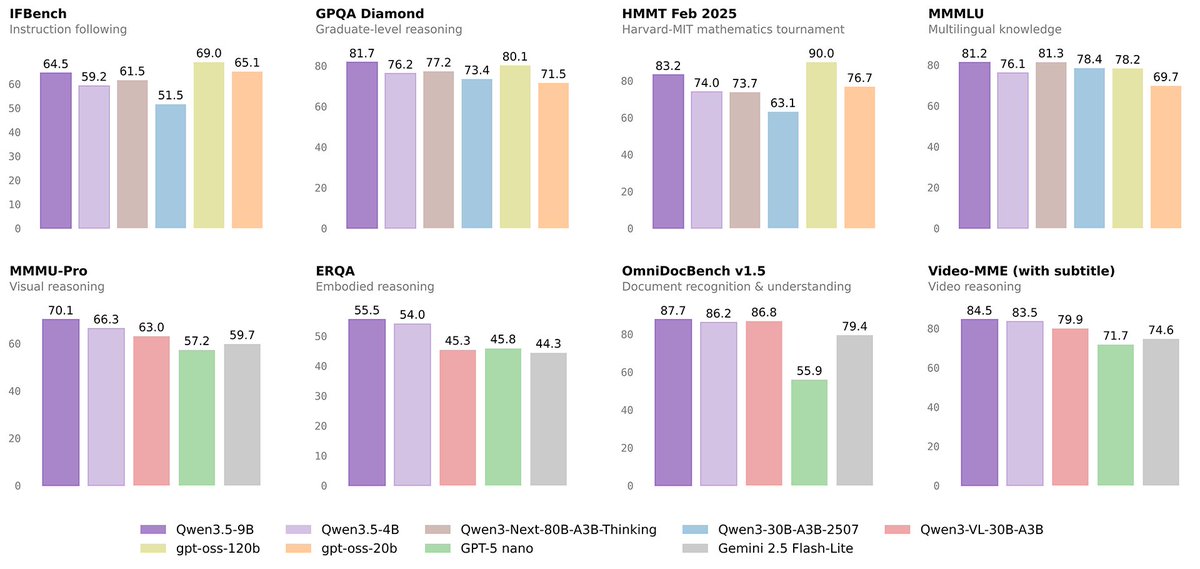
🚀 Introducing the Qwen 3.5 Small Model Series
Qwen3.5-0.8B · Qwen3.5-2B · Qwen3.5-4B · Qwen3.5-9B
✨ More intelligence, less compute.
These small models are built on the same Qwen3.5 foundation — native multimodal, improved architecture, scaled RL:
• 0.8B / 2B → tiny, fast, great for edge device
• 4B → a surprisingly strong multimodal base for lightweight agents
• 9B → compact, but already closing the gap with much larger models
And yes — we’re also releasing the Base models as well.
We hope this better supports research, experimentation, and real-world industrial innovation.
Hugging Face: https://t.co/wFMdX5pDjU
ModelScope: https://t.co/9NGXcIdCWI
I truly hope the (former) Qwen team open their own research lab or join one of the other labs. The value to the community their models have been is immeasurable.
Regardless, thank you all for your service and we're all eagerly awaiting what's next for you all
@StefanoErmon@StefanoErmon, would you be willing to attend a Brazilian podcast on AI and talk about yourself, Inception, Mercury II, DLLMs …? Disclosure: I’m not affiliated, just an enthusiastic follower. But I could put you contact.