We just released our preprint "CyberPal. AI: Empowering LLMs with Expert-Driven Cybersecurity Instructions." by @IBMResearch.
Check out how our approach improves cybersecurity AI performance by up to 24% across a variety of tasks: https://t.co/TPGMo7zLIe
#IBM#LLMs
🧵 >>
As a long-time fan of Claude code, I just switched to @OpenAI's Codex, and GPT-5.5 is spectacular.
One caveat of leaving Anthropic's ecosystem (skills, plugins, sessions) is the manual switch process.
@sama it would be a game-changer if you guys can add a one-click move feature
"But here is what we found when we tested: We took the specific vulnerabilities Anthropic showcases in their announcement, isolated the relevant code, and ran them through small, cheap, open-weights models. Those models recovered much of the same analysis. Eight out of eight models detected Mythos's flagship FreeBSD exploit, including one with only 3.6 billion active parameters costing $0.11 per million tokens. A 5.1B-active open model recovered the core chain of the 27-year-old OpenBSD bug." https://t.co/yBTiiMq1Xy
אחד הסרטונים האהובים עליי של ביל אקמן.
הקרן שלו ירדה ביותר מ30%
הוא נתבע על ידי משקיעים
היה באמצע גירושין
וקרן אקטיביסטית ניסתה להשתלט על פרשינג
מה השיטה שלו לצאת ממצבים כאלו. ריבית דריבית עובדת בכל אספקט בחיים שלנו
I tested how vulnerable my ClawdBot (by @openclaw) is to indirect prompt injection (via email).
It’s powerful — but if you connect it to inbox/WhatsApp/Telegram, you must harden it.
Self-check your setup before someone else does.
https://t.co/GBOrDBA8eJ
#Clawdbot#MOLTBOT
@Cyburgerim אני מניח שזה שילוב של מספר אינטרסים.
אגב, לא מופרך שהם הריצו את אותה התקפה גם עם המודלים הפנימיים שלהם, ואז הם רצו לעשות benchmarking מול ה frontier models כמו קלוד כדי להבין איפה המודלים שלהם עומדים מבחינת יכולות.
New IBM paper builds small security expert language models that beat bigger ones on key threat tasks.
The authors build SecKnowledge 2.0, a dataset with expert formats and grounded evidence.
They fine tune CyberPal 2.0 models from 4B to 20B on that data.
The models learn to answer fast for simple prompts and show steps for harder ones.
Tests cover core threat knowledge and mapping bugs to the right weakness category.
The 20B model ranks 1st on root cause mapping, and the 4B model is close behind.
Average gains over their baselines are 7-14% across security benchmarks.
Most gains come from stronger formats and evidence grounding rather than more compute.
8-bit and 4-bit versions keep most quality, which helps on prem deployments.
The idea is that step-by-step, evidence-backed workflows let small models make reliable calls.
----
Paper – arxiv. org/abs/2510.14113
Paper Title: "Toward Cybersecurity-Expert Small Language Models"
I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input.
Maybe it makes more sense that all inputs to LLMs should only ever be images. Even if you happen to have pure text input, maybe you'd prefer to render it and then feed that in:
- more information compression (see paper) => shorter context windows, more efficiency
- significantly more general information stream => not just text, but e.g. bold text, colored text, arbitrary images.
- input can now be processed with bidirectional attention easily and as default, not autoregressive attention - a lot more powerful.
- delete the tokenizer (at the input)!! I already ranted about how much I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It "imports" all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an... actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go.
OCR is just one of many useful vision -> text tasks. And text -> text tasks can be made to be vision ->text tasks. Not vice versa.
So many the User message is images, but the decoder (the Assistant response) remains text. It's a lot less obvious how to output pixels realistically... or if you'd want to.
Now I have to also fight the urge to side quest an image-input-only version of nanochat...
BOOOOOOOM!
CHINA DEEPSEEK DOES IT AGAIN!
An entire encyclopedia compressed into a single, high-resolution image!
—
A mind-blowing breakthrough. DeepSeek-OCR, unleashed an electrifying 3-billion-parameter vision-language model that obliterates the boundaries between text and vision with jaw-dropping optical compression!
This isn’t just an OCR upgrade—it’s a seismic paradigm shift, on how machines perceive and conquer data.
DeepSeek-OCR crushes long documents into vision tokens with a staggering 97% decoding precision at a 10x compression ratio!
That’s thousands of textual tokens distilled into a mere 100 vision tokens per page, outmuscling GOT-OCR2.0 (256 tokens) and MinerU2.0 (6,000 tokens) by up to 60x fewer tokens on the OmniDocBench.
It’s like compressing an entire encyclopedia into a single, high-definition snapshot—mind-boggling efficiency at its peak!
At the core of this insanity is the DeepEncoder, a turbocharged fusion of the SAM (Segment Anything Model) and CLIP (Contrastive Language–Image Pretraining) backbones, supercharged by a 16x convolutional compressor.
This maintains high-resolution perception while slashing activation memory, transforming thousands of image patches into a lean 100-200 vision tokens.
Get ready for the multi-resolution "Gundam" mode—scaling from 512x512 to a monstrous 1280x1280 pixels!
It blends local tiles with a global view, tackling invoices, blueprints, and newspapers with zero retraining. It’s a shape-shifting computational marvel, mirroring the human eye’s dynamic focus with pixel-perfect precision!
The training data?
Supplied by the Chinese government for free and not available to any US company.
You understand now why I have said the US needs a Manhattan Project for AI training data? Do you hear me now? Oh still no? I’ll continue.
Over 30 million PDF pages across 100 languages, spiked with 10 million natural scene OCR samples, 10 million charts, 5 million chemical formulas, and 1 million geometry problems!.
This model doesn’t just read—it devours scientific diagrams and equations, turning raw data into a multidimensional knowledge.
Throughput? Prepare to be floored—over 200,000 pages per day on a single NVIDIA A100 GPU! This scalability is a game-changer, turning LLM data generation into a firehose of innovation, democratizing access to terabytes of insight for every AI pioneer out there.
This optical compression is the holy grail for LLM long-context woes. Imagine a million-token document shrunk into a 100,000-token visual map—DeepSeek-OCR reimagines context as a perceptual playground, paving the way for a GPT-5 that processes documents like a supercharged visual cortex!
The two-stage architecture is pure engineering poetry: DeepEncoder generates tokens, while a Mixture-of-Experts decoder spits out structured Markdown with multilingual flair. It’s a universal translator for the visual-textual multiverse, optimized for global domination!
Benchmarks? DeepSeek-OCR obliterates GOT-OCR2.0 and MinerU2.0, holding 60% accuracy at 20x compression! This opens a portal to applications once thought impossible—pushing the boundaries of computational physics into uncharted territory!
Live document analysis, streaming OCR for accessibility, and real-time translation with visual context are now economically viable, thanks to this compression breakthrough. It’s a real-time revolution, ready to transform our digital ecosystem!
This paper is a blueprint for the future—proving text can be visually compressed 10x for long-term memory and reasoning. It’s a clarion call for a new AI era where perception trumps text, and models like GPT-5 see documents in a single, glorious glance.
I am experimenting with this now on 1870-1970 offline data that I have digitalized.
But be ready for a revolution!
More soon.
[1] https://t.co/wItN5iRQ91
🚨Reasoning LLMs are e̵f̵f̵e̵c̵t̵i̵v̵e̵ ̵y̵e̵t̵ inefficient!
Large language models (LLMs) now solve multi-step problems by emitting extended chains of thought. During the process, they often re-derive the same intermediate steps across problems, inflating token usage and latency.
Metacognitive Reuse: turn recurring LLM reasoning into concise, reusable “behaviors”. The model learns named skills from its own chains-of-thought and reuses them to think faster & cheaper.
Arxiv 🔗 - https://t.co/zA1gB4eYTG
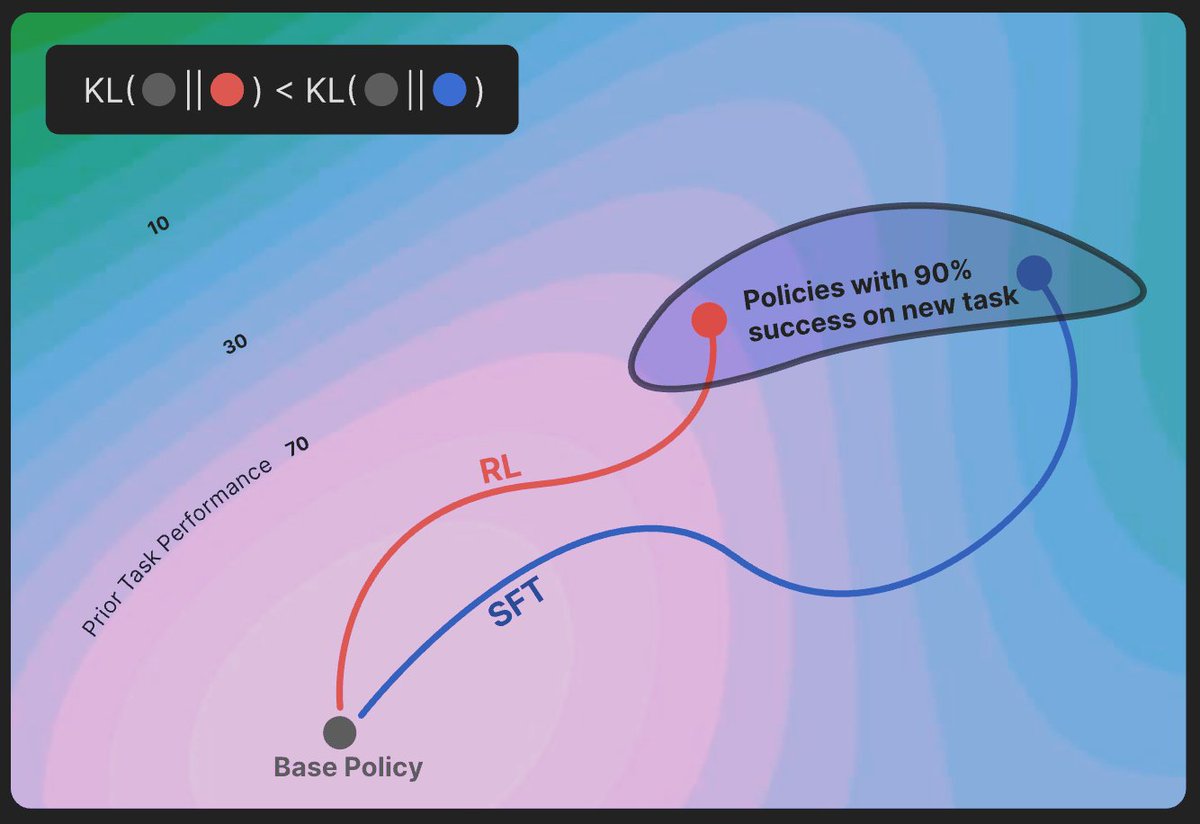
RL’s Razor: On-policy RL forgets less than SFT.
Even at matched accuracy, RL shows less catastrophic forgetting
Key factor: RL’s on-policy updates bias toward KL-minimal solutions
Theory + LLM & toy experiments confirm RL stays closer to base model
1/11 You don’t need a million-dollar budget to dent guardrails. Below I show how a single A100-80GB and pocket change can break @OpenAI 's #GPT OSS refusals mechanism. Here’s why—and what OpenAI’s risk paper does (and doesn’t) cover 👇
@chrisk99999@OpenAI@Eric_Wallace_ Yes, totally I agree that the anti-refusal is indeed the lower bound for adversaries *with training budget*. I thought it will be interesting to see what will be the lower bound if the adversary does not have a large training budget.
@chrisk99999@OpenAI@Eric_Wallace_ Since these kind of attacks are the most easy and most cost effective to perform, it can serve as some kind of a lower bound (minimum gain) a malicious actor can gain from the open source model, which IMO as interesting as the case of increasing the ceiling.
















![BrianRoemmele's tweet photo. BOOOOOOOM!
CHINA DEEPSEEK DOES IT AGAIN!
An entire encyclopedia compressed into a single, high-resolution image!
—
A mind-blowing breakthrough. DeepSeek-OCR, unleashed an electrifying 3-billion-parameter vision-language model that obliterates the boundaries between text and vision with jaw-dropping optical compression!
This isn’t just an OCR upgrade—it’s a seismic paradigm shift, on how machines perceive and conquer data.
DeepSeek-OCR crushes long documents into vision tokens with a staggering 97% decoding precision at a 10x compression ratio!
That’s thousands of textual tokens distilled into a mere 100 vision tokens per page, outmuscling GOT-OCR2.0 (256 tokens) and MinerU2.0 (6,000 tokens) by up to 60x fewer tokens on the OmniDocBench.
It’s like compressing an entire encyclopedia into a single, high-definition snapshot—mind-boggling efficiency at its peak!
At the core of this insanity is the DeepEncoder, a turbocharged fusion of the SAM (Segment Anything Model) and CLIP (Contrastive Language–Image Pretraining) backbones, supercharged by a 16x convolutional compressor.
This maintains high-resolution perception while slashing activation memory, transforming thousands of image patches into a lean 100-200 vision tokens.
Get ready for the multi-resolution "Gundam" mode—scaling from 512x512 to a monstrous 1280x1280 pixels!
It blends local tiles with a global view, tackling invoices, blueprints, and newspapers with zero retraining. It’s a shape-shifting computational marvel, mirroring the human eye’s dynamic focus with pixel-perfect precision!
The training data?
Supplied by the Chinese government for free and not available to any US company.
You understand now why I have said the US needs a Manhattan Project for AI training data? Do you hear me now? Oh still no? I’ll continue.
Over 30 million PDF pages across 100 languages, spiked with 10 million natural scene OCR samples, 10 million charts, 5 million chemical formulas, and 1 million geometry problems!.
This model doesn’t just read—it devours scientific diagrams and equations, turning raw data into a multidimensional knowledge.
Throughput? Prepare to be floored—over 200,000 pages per day on a single NVIDIA A100 GPU! This scalability is a game-changer, turning LLM data generation into a firehose of innovation, democratizing access to terabytes of insight for every AI pioneer out there.
This optical compression is the holy grail for LLM long-context woes. Imagine a million-token document shrunk into a 100,000-token visual map—DeepSeek-OCR reimagines context as a perceptual playground, paving the way for a GPT-5 that processes documents like a supercharged visual cortex!
The two-stage architecture is pure engineering poetry: DeepEncoder generates tokens, while a Mixture-of-Experts decoder spits out structured Markdown with multilingual flair. It’s a universal translator for the visual-textual multiverse, optimized for global domination!
Benchmarks? DeepSeek-OCR obliterates GOT-OCR2.0 and MinerU2.0, holding 60% accuracy at 20x compression! This opens a portal to applications once thought impossible—pushing the boundaries of computational physics into uncharted territory!
Live document analysis, streaming OCR for accessibility, and real-time translation with visual context are now economically viable, thanks to this compression breakthrough. It’s a real-time revolution, ready to transform our digital ecosystem!
This paper is a blueprint for the future—proving text can be visually compressed 10x for long-term memory and reasoning. It’s a clarion call for a new AI era where perception trumps text, and models like GPT-5 see documents in a single, glorious glance.
I am experimenting with this now on 1870-1970 offline data that I have digitalized.
But be ready for a revolution!
More soon.
[1] https://t.co/wItN5iRQ91](https://pbs.twimg.com/media/G3t3KNVXsAEKmsk.jpg)