🚀 Serve and fine-tune #Qwen3 — in your cloud or ours with blazing fast #inference speeds! No need to share your data. 🚀
Qwen 3 is the latest #opensource LLM dominating the leaderboards. Don't get left behind!
Now you can serve and customize the latest Qwen models instantly on our shared serverless endpoints or deploy securely in your own #VPC!
➡️ Try Qwen 3 with $25 in free Predibase credits: https://t.co/P7s8UZSxvs
➡️ Get access to high-end GPUs to deploy Qwen 3 in your cloud: https://t.co/ujZvGSyA10
🐳 AI teams are testing DeepSeek—but nobody agrees on when to use it
In our recent survey of 500+ AI professionals, DeepSeek-R1 is getting serious attention—but it's far from mainstream. Here’s what we uncovered:
📊 57% of teams have experimented with DeepSeek-R1
⚠️ Only 3% have deployed it in production
🤷♂️ Nearly half are unsure how it stacks up to other models
And the demand for customization is clear:
🔧 46% want fine-tuning or distillation options
🧪 The takeaway? DeepSeek-R1 has potential—but teams are still figuring out how to unlock it.
👉 Ready to see if it fits your use case? Start experimenting on Predibase—free trial available.
#AI #LLM #DeepSeek #MLOps #Predibase #GenAI #MachineLearning #opensourcellms
Today we're thrilled to announce the first end-to-end platform for Reinforcement Fine-Tuning.
With just a dozen labeled data points, you can outperform #OpenAI o1 and #DeepSeekR1 on complex tasks. Built on the #GRPO methodology that DeepSeek-R1 popularized, our platform delivers exceptional results.
In our real-world PyTorch to Triton transpilation case study, we achieved 3x higher accuracy than OpenAI o1 and DeepSeek-R1 when writing GPU code.
Check out the thread below to learn how you can adapt an #opensource #LLM to your use cases with unmatched efficiency. #rft
#Reasoning models are 🔥
But #inference can be sooo slow due to massive token generation 🛑
Unless you know how to #turbo charge your LLMs 🚀
Last chance: Save your spot for our interactive 30 minute #AMA style demo on how to accelerate reasoning models like #DeepSeek-R1 by 2-3x.
➡️ Sign-up: https://t.co/Ou9TQMmiA8
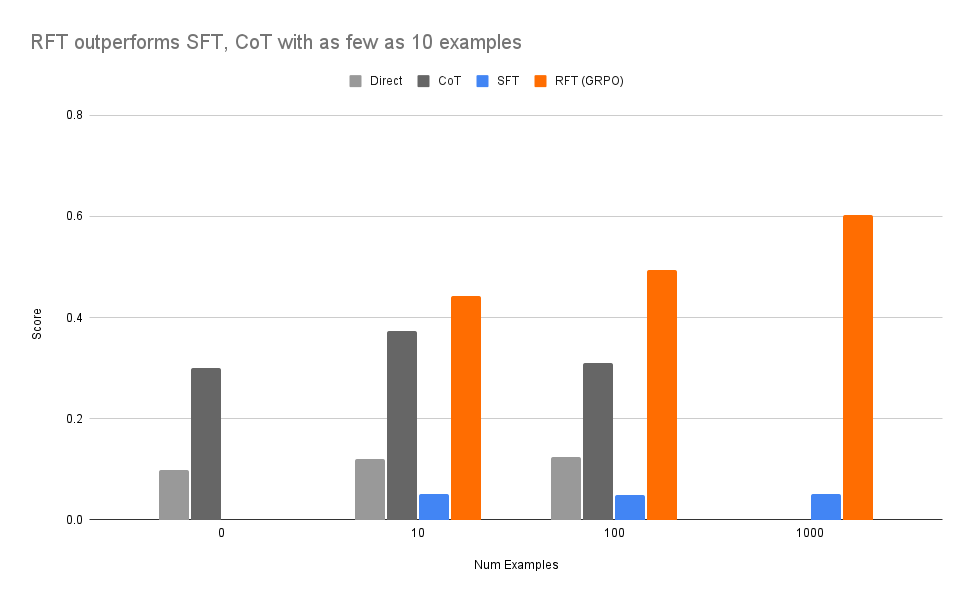
🚀 #RFT vs. #SFT: When to Use Each for Maximum Impact
#DeepSeek -R1 made #Reinforcement#FineTuning (RFT) the hot new thing—but is it better than #Supervised Fine-Tuning (SFT)? 🤔
Here’s when RFT wins:
✅ No labeled data? If you can verify correctness, RFT works.
✅ <100 labeled examples? RFT generalizes better.
✅ CoT helps? RFT fine-tunes reasoning beyond SFT.
📖 Read the full blog here 👉 https://t.co/7fbCGwwU71
🚀 Supervised Fine-Tuning (SFT) has been the default for adapting LLMs—but it has a major limitation: it demands a large amount of high-quality labeled data.
🧵 Why Reinforcement Fine-Tuning (RFT) is a better approach when data is scarce: 👇
⭐ We're excited to announce the launch of #SmallCon: A free virtual conference for #GenAI teams looking to build big with small models! ⭐
We're bringing together leading minds in AI from @Meta, @MistralAI, @Salesforce and more for deep dive tech talks and panel discussions on what it takes to build the #GenAI stack of the future and put your #SLMs into production!
Our amazing list of speakers include:
➡ Daniel Hunter, Prev. the Head of AI @ Harvey AI
➡ Margaret Jennings, Head of Product @ Mistral
➡ Manjeet Singh, Sr. Director of AI Platforms @ Salesforce
➡ Abhishek Patnia, St. Staff ML Eng @ Nubank
➡ Diego Guerra Orozco, GenAI Partnership Lead @ Meta
➡ Shreya Rajpal, CEO and Cofounder @ Guardrails AI
➡ Giuseppe Romagnuolo, Head of AI @ Convirza
and much more!
Check out the site for the full agenda and list of speakers: https://t.co/Wn7siXvb5l
Make sure to save your spot!
Thank you to our event cohosts @rungalileo, @gretel_ai and @upstageai !
Revolutionizing Fine-Tuned Small Language Model Deployments: Introducing Predibase’s Next-Gen Inference Engine
Predibase announces the Predibase Inference Engine, their new infrastructure offering designed to be the best platform for serving fine-tuned small language models (SLMs). The Predibase Inference Engine dramatically improves SLM deployments by making them faster, easily scalable, and more cost-effective for enterprises grappling with the complexities of productionizing AI. Built on Predibase’s innovations–Turbo LoRA and LoRA eXchange (LoRAX)–the Predibase Inference Engine is designed from the ground up to offer a best-in-class experience for serving fine-tuned SLMs.
Technical Breakthroughs in the Predibase Inference Engine
At the heart of the Predibase Inference Engine are a set of innovative features that collectively enhance the deployment of SLMs:
✅ LoRAX: LoRA eXchange (LoRAX) allows for the serving of hundreds of fine-tuned SLMs from a single GPU. This capability significantly reduces infrastructure costs by minimizing the number of GPUs needed for deployment. It’s particularly beneficial for businesses that need to deploy various specialized models without the overhead of dedicating a GPU to each model.
✅ Turbo LoRA: Turbo LoRA is our parameter-efficient fine-tuning method that accelerates throughput by 2-3 times while rivaling or exceeding GPT-4 in terms of response quality. These throughput improvements greatly reduce inference costs and latency, even for high-volume use cases.
✅ FP8 Quantization: Implementing FP8 quantization can reduce the memory footprint of deploying a fine-tuned SLM by 50%, leading to nearly 2x further improvements in throughput. This optimization not only improves performance but also enhances the cost-efficiency of deployments, allowing for up to 2x more simultaneous requests on the same number of GPUs.
✅ GPU Autoscaling: Predibase SaaS deployments can dynamically adjust GPU resources based on real-time demand. This flexibility ensures that resources are efficiently utilized, reducing waste and cost during periods of fluctuating demand.
Read our full article here: https://t.co/ToP9mj9rYC
@predibase
What if you could have your own highly-optimized #LLMs running in your #private cloud without any hassle? 🙋♂️ 🙋♀️
Well now you can. No more choosing between #performance and #security — have your LLM cake and eat it too! 🍰 😎
Want to learn how? 💡
Save a spot for our webinar to learn how to easily deploy LLMs in your cloud < 30 minutes with Predibase #VPC. We'll even show you how to get those models to outperform #GPT4! 💰
https://t.co/cNQyUCmxiO
There's a new "best #SLM" in town!
We fine-tuned Llama-3.1-8b-instruct on 25 tasks and it shows a huge improvement over #GPT-4, GPT-4o mini, fine-tuned #Phi-3, and fine-tuned #Mistral-7b.
Small language models continue to set the standard for performance, cost, and privacy!
We had a blast joining the Founded & Funded podcast with @vivekramaswami at @MadronaVentures to chat about all things LLMs, why small #finetuned models are the future, and what it takes to build a successful high growth startup.
Full video: https://t.co/cXr2YnCGHP
What's the best model for fine-tuning? Can 8B param models really beat GPT-4 when fine-tuned to specific tasks?
@predibase we've put together our most complete guide to fine-tuning to date, answering these questions and more: the Fine-Tuning Index:
https://t.co/nFPXC66u85
✨ Introducing the Fine-tuning Index! A comprehensive set of benchmarks for 13 fine-tuned #opensource#LLMs and leading models from #OpenAI across 31 diverse tasks. The index reports essential metrics, including:
📊 Performance
⚡ Speed
💰 Cost
https://t.co/hPBL0AdLCq
Join @gretel_ai Chief Scientist, @yevmeyer, and @predibase DevRel Engineer, @AlexSherstinsky, to learn how to use Gretel's new synthetic Text-to-SQL dataset along with Predibase to easily and efficiently #finetune an open-source LLM.
Save your spot!
https://t.co/mwNRyFQ8Jq