Are neural nets across modalities really converging to the same representation as they scale, as the Platonic Representation Hypothesis suggests?
We show that common representational similarity metrics are confounded by network width & depth. We propose a permutation-based null calibration that fixes this.
Result❓
• Global convergence largely disappears.
• Local neighborhoods persist.
We propose the alternative Aristotelian Representation Hypothesis: Neural networks, trained with different objectives on different data and modalities, are converging to shared local neighborhood relationships
Very proud of @FabianGroger and @ShuoWen18 for this work!
Paper: https://t.co/GmkhwsiN1N
Webpage: https://t.co/xaI31BU2FS
Code: https://t.co/5qItdzRBZP
🚨 BREAKING: Meta researchers showed a model 2 million hours of video. No labels. No physics textbook. No supervision at all.
It learned gravity. Object permanence. Inertia.
And it just beat Gemini 1.5 Pro and GPT-4 level models at physics understanding.
Here's what just happened:
An Illustrated Guide to Modern Machine Learning with Geometric, Topological, and Algebraic Structures
Provides an illustrated guide and graphical taxonomy of recent advances in non-Euclidean machine learning.
@PhysInHistory As you go to the gym to make your body fit, try to build mental gym and train your brain with math to make it sharp. To enhance problem solving, and logical thinking skills.
I am extremely bullish about both India and China
The work ethic is very high, they have enormous amounts of local talent and China, especially is building a ton of very cool models.
I am also hopeful that they will continue to be pro open-source and share their research and inventions
AI can definitely bring us together us a global community!
I don’t know how some people register to many courses, and try to study them at the same time.
I just discovered this lately that many do it, but I will not do it in my whole life because of my #autistic brain.
And yeah that is my strength and weakness at the same time, #FOCUS on one thing only, then go to the next.
Good paper by Netflix on cosine similarity.
It goes back to building good RAG systems, which is hard. Before deploying these systems, you have to make intelligent decisions about chunking, hierarchical chunking, embedding, and even the algorithm for similarity look-up.
Failure modes will be high and accuracy low if you don't use the appropriate techniques.
https://t.co/vXXABHdE4E
The cone of positive semi-definite matrices is a fundamental object of convex analysis and optimization. One can encode or approximate convex constraints as linear sections of this cone. https://t.co/OaqHVLkL4A
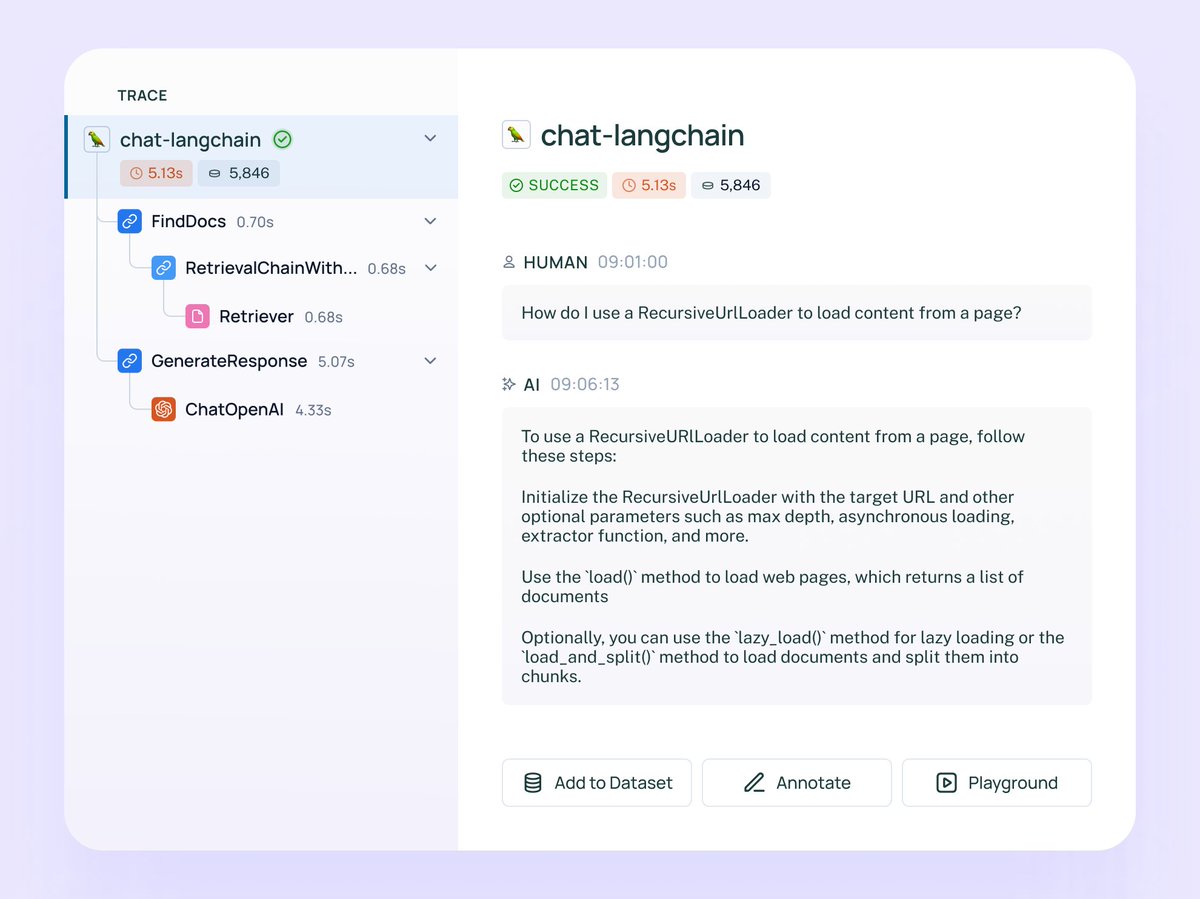
✨ Today, we’re thrilled to announce ✨
- The general availability of LangSmith (no more waitlist!)
- Our Series A fundraise led by @sequoia
- Our beautiful new homepage and brand
We've worked hard over the past few months to add requested features and ensure LangSmith can operate at scale. We’re now confident in saying that it is the most complete platform for building production-grade LLM applications, whether or not you’re using LangChain. Learn more here: https://t.co/KnHphvWyVo and sign up here: https://t.co/EyAuPFrQf3
Our series A round will give us the capital needed to grow our open source and platform offerings. Working with @sonyatweetybird, @romie_boyd, and the rest of the Sequoia team has been a privilege so far! https://t.co/7ktOuD64DX
Finally, we’re excited to unveil our new homepage and brand. Dive into our new website at https://t.co/NBssYyCySX to see the changes for yourself, explore the expanded resources, and discover what LangChain, LangSmith, and LangServe have to offer.
PS — we’re hiring! Explore our careers page and reach out if you think you’re a fit for any of our open positions! https://t.co/KGSa0rqR95
Oldies but goldies: A. Legendre, Nouvelles méthodes pour la détermination des orbites des comètes, 1805. First publication of the least square method, before Gauss according to French people … https://t.co/LJHUYbH8oW
My takeaways from attending WEF at Davos last week:
- There were lots of discussions on business implementation of AI. My top two tips: (i) Pretty much all knowledge workers can benefit from using GenAI now, but most will need training. (ii) Task-based analysis of jobs is helping businesses identify opportunities.
- Also lots of AI regulation conversations. I'm happy to report that the conversation is much more sensible than 6 months ago. For example, the unnecessary fears and discussion on AI extinction risk is fading away. But some big companies are still pushing for stifling, anti-competitive regulations, and the fight to protect open-source is still far from won.
- Attending climate sessions made me even more worried about the lack of action to change our planet's trajectory. Rather than 1.5 degrees Celsius of warming as the optimistic case and 2 degrees as the pessimistic case, I think 2 degrees is an optimistic case, and 4 degrees a more realistic pessimistic case. Decarbonization remains critical; and unfortunately, that we're talking about 1.5-2 degrees rather than 2-4 degrees means we're underinvesting in resilience, adaptation, and potentially game-changing technologies like geo-engineering.
Longer writeup below in The Batch: https://t.co/ZkdsgeF6WU
My way in learning AI #artificalintelligence:
1. Foundation layer: Machine learning, Math for machine learning
2. Gaining knowledge layer: Deep learning, Probabilistic graphical model, and Reinforcement Learning
3. Mining layer: Natural Language Processing, and MLOps
4. Mastering layer: reading researches and continue learning
#MachineLearning #deeplearning
“That is the way to learn the most, that when you are doing something with such enjoyment that you don’t notice that the time passes.” - #AlbertEinstein
7/ So, as aspiring data detectives, let's aim for models that are just right – not too biased, not too variable. Finding that balance ensures our models don't just memorize the past but can also predict the future accurately!
#MachineLearning#BiasAndVariance#DataScience #AIUnderstanding
5/ Think of it as cooking: too little spice (bias) and your dish is bland, too much spice (variance) and it's overwhelming. Achieving that perfect flavor is like finding the optimal balance in ML models.
6/ The challenge lies in identifying and minimizing these biases and variances during model training. It's a delicate dance between simplicity and complexity, between underfitting and overfitting.
4/ Avoidable bias and variance often go hand in hand. The key is finding the sweet spot – a model that captures the essence of the data without getting bogged down by noise.
3/ Striking the right balance is crucial. Too much bias, and your model will generalize poorly. Too much variance, and it becomes a 'memorizer,' failing to adapt to new situations.
🧵 Exploring the nuances of avoidable bias and variance in machine learning! 🤖 Let's dive in.
1/ Bias is like wearing tinted glasses – it distorts our view of the world. In ML, avoidable bias occurs when a model oversimplifies the data, missing crucial patterns. Imagine a detective ignoring key evidence; that's avoidable bias!
2/ Variance, on the other hand, is the model's sensitivity to small fluctuations in the training data. It's like a detective who overanalyzes every detail, including noise. This can lead to the model performing well on training data but poorly on new, unseen data.