السعى هيعمل حاجة من التلاتة.. يا إما هتنجح من أول مرة.. يا إما لو مانجحتش في لحظتها هيديك خبرة في اللي جاي.. يا إما هيخليك تتعلم إن مش هو ده الطريق اللي كان يستحق المجهود فتشوف طريق تاني غيره.. مفيش مجهود بيضيع في المطلق.
RASPIRE (@raspire_) is building app security at AI speed.
As AI accelerates mobile attacks, their platform protects Android and iOS apps from fraud, reverse engineering, and API abuse with zero code changes. They're already securing apps used by 20M+ people across banking, fintech, and healthcare.
Congrats on the launch, @EzV01d & @hsanmost!
https://t.co/0J7Sw3GOHe
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
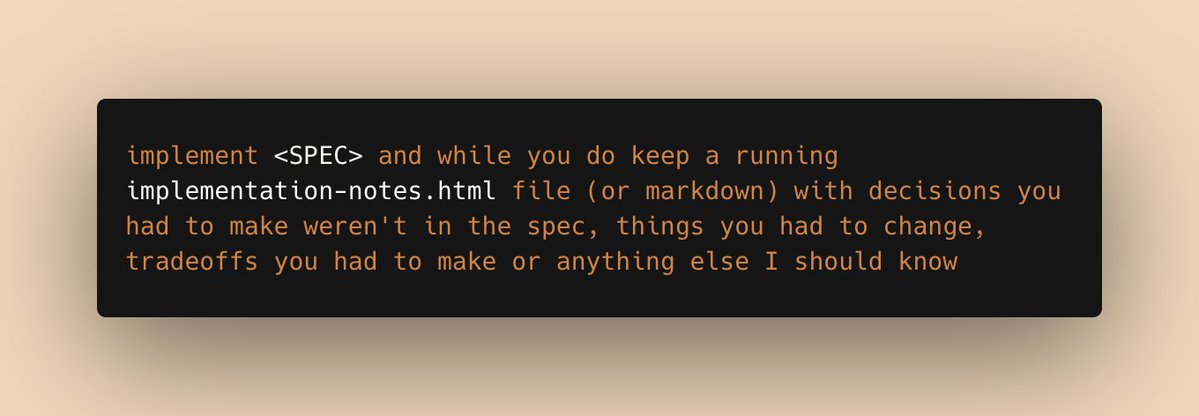
a prompt I've been using a lot recently:
implement <SPEC> and while you do, keep a running implementation-notes.html file (or markdown) with decisions you had to make weren't in the spec, things you had to change, tradeoffs you had to make or anything else I should know
هالو أهل تويتر
أنا من الناس اللي اتأثروا بال layoff الأخير في Breadfast.
بدور حاليا على فرصة في ( مصر او ألمانيا أو ريموت أوروبا)
Senior Software Quality Engineer
Experiance: 5 years [Manual + Automation +API]
الي يقدر يعملي referral يبقى شكرا جدا 🙏🏻
Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
https://t.co/NQ7IfEtYk7
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: https://t.co/NlAfEJjtJV
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
حاليًا بدور على فرصة شغل ..
Junior data engineer
دا CV بتاعي
لو حد يقدر يفيدني بنصيحة، فرصة متاحة، أو
حتى Recommendation أكون متشكرة جدًا
Retweet please
https://t.co/D0bvFKv8ip
🚨 BREAKING: Anthropic just accidentally leaked their ENTIRE Claude Code source code
500,000+ lines
Everything exposed
How? They forgot to remove ONE file before publishing
The irony? Deep in the code they built a secret "Undercover Mode" to prevent leaks... then leaked everything themselves
But wait, there's more
The same day, Axios, a tool used by millions of websites and apps, got HACKED
Someone hijacked a developer's account and snuck in malware
If you installed the latest version, hackers could be spying on your computer right now
Mac, Windows, Linux —> all targeted
Two massive security fails
Same day
Both were caused by simple mistakes
Even billion-dollar AI companies mess up basic stuff
Today, we’re releasing a significant upgrade to our specialized reasoning mode, Gemini 3 Deep Think.
Deep Think is built to drive practical applications, enabling researchers to interpret complex data and engineers to model physical systems through code.
With the updated Deep Think, you can turn a sketch into a 3D-printable reality. Deep Think analyzes the drawing, builds the complex shape, and generates a file so you can create the physical object with 3D printing.
This is rolling out now to Google AI Ultra subscribers. Select the "Deep Think" option in the tools menu to get started.
Learn more here: https://t.co/MMGMgDtoK8
I'm Boris and I created Claude Code. I wanted to quickly share a few tips for using Claude Code, sourced directly from the Claude Code team. The way the team uses Claude is different than how I use it. Remember: there is no one right way to use Claude Code -- everyones' setup is different. You should experiment to see what works for you!
اعتقد البحث ده بيلخص كل اللي قلته السنة دي بخصوص ال agents وحجم الاعتمادية عليها والاحتياج المستمر للعامل البشري
وبغض النظر ان البحث اتكلم عن كذا تقطة مهمة زي ان الاغلبية معتمدة على ال prompting لان ال fine tuning مكلف والعائد منه مش كويس ، وان اغلب ال agent بتحتاج عامل بشري يتحقق من نتايجها كل عشر خطوات ، وان LangChain مش احسن حاجة لو بتبني حاجة حقيقية هتنزل Production
الا ان البحث بيثبت نقطتي في ان ما يسمى حاليا agent هو لايتجاوز ال workflow الذكي واننا مازلنا في مرحلة ال smart automation
وبالتبعية
اننا بعيد جدا عن ما يسمى ال AGI
Introducing the next generation: Claude Opus 4 and Claude Sonnet 4.
Claude Opus 4 is our most powerful model yet, and the world’s best coding model.
Claude Sonnet 4 is a significant upgrade from its predecessor, delivering superior coding and reasoning.