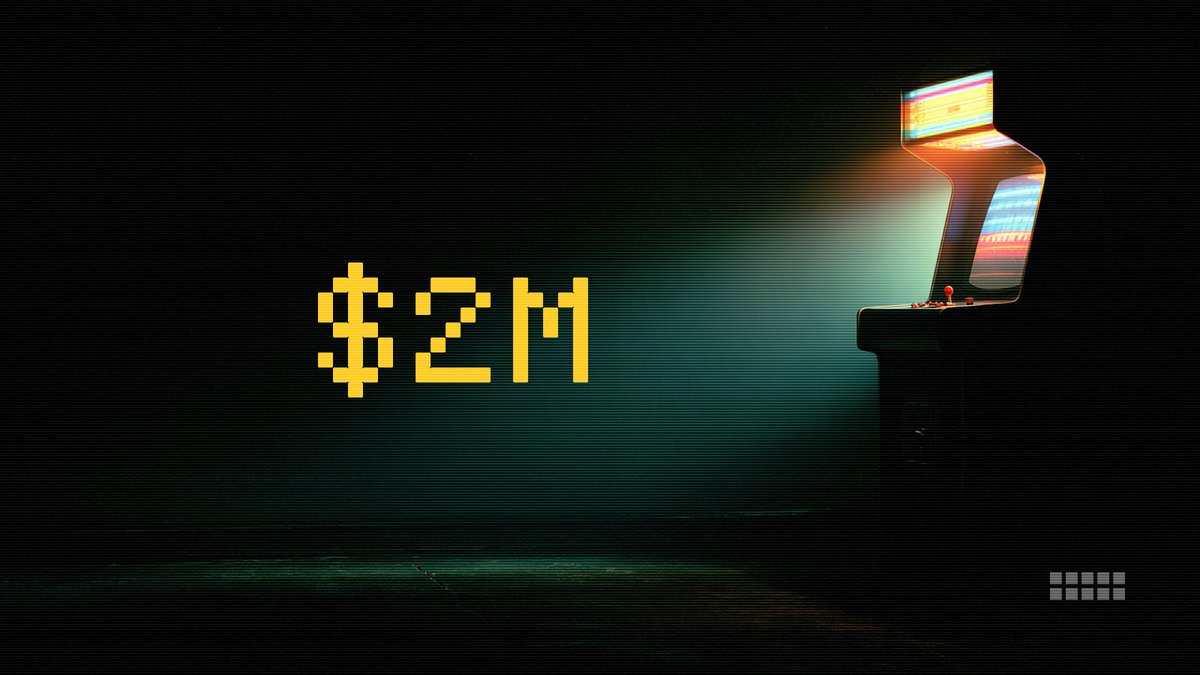OffGridSchedula reads a messy group chat and produces calendar events, entirely on small, locally-served models, with no cloud AI in the loop. It runs on two specialists working together: a fine-tuned ~4-billion-parameter Gemma E4B that turns messy language into structure, and @OpenBMB MiniCPM, which powers the agentic planner that reads the thread, decides which tool to call, and drives the app's own functions over the Model Context Protocol.
Before which model, before size, fine-tuning, or quantization, there's a more fundamental question most teams skip past: encoder or decoder? That call was made twice, once for extraction and once for orchestration, and both times the answer was a decoder. It's worth making the reasoning explicit, because it's the decision the rest of the system is built on.
The decisions behind it:
Why a decoder, not BERT, where the deliverable decides. Per thread the extractor emits one constrained object: events[] (title, ISO-8601 start/end, location, reminders), a reply_draft, and a needs_clarification question when the thread is ambiguous. That isn't classification and it isn't span-tagging. This is generation plus reasoning, resolving "next Tuesday" against a reference date and shifting a start when someone says "arrive 15 min early." Encoder-only models (BERT / RoBERTa / DeBERTa) are discriminative: they understand, classify, tag, embed, but they don't write. To force this onto BERT you'd stitch together an intent classifier and an NER tagger and a datetime normalizer, AND you still couldn't draft the reply. A decoder wasn't the better option here; it was the only option.
Why orchestration is also a decoder job. Planning is generative reasoning too. You can't classify your way to "call extract_events, observe the result, then finalize." So the Agent tab's planner is a second decoder, OpenBMB's MiniCPM, deliberately separate from the extractor: MiniCPM decides which tools to call, the fine-tuned E4B does the extraction, each model doing the one thing it's good at.
**This project was part of the @Gradio #BuildSmallHackathon as part of the Backyard AI track, while adhering to the six earnable merit badges.**
HF Space: https://t.co/5qv5VpdAML
Model: https://t.co/akRWT5JjLQ
Sharing more on agent design from the OffGridSchedula weekend app project. The LLM is scoped to a single hard task, mapping unstructured natural language to a typed schema using grammar-constrained decoding. Deterministic reasoning is deliberately excluded from it.
Interval overlap (a0 < b1 ∧ b0 < a1) is exact, O(1), and independently verifiable, so delegating it to a probabilistic model would strictly dominate on cost, latency, and error while underperforming a comparison operator. The model may propose conflicts; the system discards those and recomputes them from the source calendar.
The same separation governs arrival-aware start times and type-conditioned reminders. This is where load-bearing logistics are guaranteed in code, with model output as the prior.
Principle: the LLM converts language to structure; deterministic logic owns invariants that must hold.
@Gradio@huggingface@OpenBMB
HF Space: https://t.co/5qv5Vpe8Cj
Model: https://t.co/akRWT5JRBo
Introducing the Open Knowledge Format (OKF), an open specification that formalizes the LLM-wiki pattern into a portable, interoperable format.
AI is only as smart as the context we give it. As we build more advanced, agentic AI systems, they need accurate metadata and context to be useful. But in most organizations, that context is locked inside fragmented data catalogs, isolated wikis, scattered code comments, or the minds of senior engineers. Every time a new AI agent is built, teams are forced to solve the exact same context-assembly problem from scratch.
To solve this, we've announced OKF, a vendor-neutral, open specification that formalizes the "LLM-wiki pattern" into a portable, interoperable format. It provides a standardized way to represent the enterprise knowledge that modern AI systems rely on.
— Just markdown: readable in any editor, renderable on GitHub, indexable by any search tool
— Just files: shippable as a tarball, hostable in any git repo, mountable on any filesystem
— Just YAML frontmatter: for the small set of structured fields that need to be queryable: type, title, description, resource, tags, and timestamp
We’ve also shipped reference implementations to help you hit the ground running, including an enrichment agent for BigQuery, a static HTML visualizer, and live sample bundles on @github → https://t.co/ilhAMCrcTc
➕ Knowledge Catalog can now natively ingest OKF!
Stop reinventing data models and building bespoke integrations for every new AI tool. Here's more about how OKF works → https://t.co/FR4kJRsgEH
The weekend build is OffGridSchedula. It turns a pasted chat (or a flyer screenshot) into calendar events, catches conflicts, and drafts the reply. The product is orchestrated by a tiny @OpenBMB MiniCPM 1B model and a fine-tuned local scheduling agent, Gemma 4 E2B (~5 GB GGUF, QLoRA, published on the Hub), run through llama.cpp. 100% local and no cloud AI APIs. Custom @Gradio UI, agent traces shareable as a dataset (or kept private if you like), notes in the repo.
https://t.co/035R18PDh1
https://t.co/akRWT5JjLQ
Some questions were asked about some SA/SWE/FDE decisions deploying OffGridSchedula. Posting some of the best ones.
Why build on a fine-tuned small model instead of using a frontier API? The hard constraint was local-first, so no cloud AI calls. The model has to be edge-sized: gemma-cal, a QLoRA fine-tune of Gemma E4B, ~5 GB at 4-bit, served as a GGUF through llama.cpp. The decision to fine-tune rather than prompt a generic model wasn't about raw capability, it was about reliability of structure. The fine-tune holds 100% schema validity even with no system prompt, won't invent an event from "thanks!", and learns this product's date conventions (what "next Tuesday" resolves to). You trade general intelligence for a model that's steller at one job, that's what is needed on the edge.
Why grammar-constrained decoding instead of generating JSON and parsing it? The single most important reliability decision. Generation is constrained to a JSON Schema derived directly from our Pydantic model (json_schema=ActionPlan.model_json_schema()). The decoder can only emit tokens that keep the output a valid ActionPlan. Compare the alternative, generate free text and parse-and-repair, which is exactly where small models fall over. By constraining at the grammar level, we delete an entire class of failures: no malformed JSON, no missing fields, no hallucinated structure. The contract is enforced at decode time, not hoped for afterward.
Why a second, separate small model just for planning? The fine-tuned E4B is a specialist with natural-language-to-ActionPlan. Orchestration is a different skill, so it requires a different model: @OpenBMB 's MiniCPM (1B), on its own local llama-server. That's a clean separation of concerns, the planner decides which tools to call; the extractor does the extraction, and both stay local, both under the size cap, still zero cloud AI. It's a two-model architecture where each model does the thing it's good at.
HF Space: https://t.co/5qv5VpdAML
Model: https://t.co/akRWT5JjLQ
Traces: https://t.co/QqCKaF08Jw
@Gradio@Google@OpenBMB@HuggingFace
The dates are always in the group chat. The misses happen anyway.
For the Gradio Build Small Hackathon I built OffGridSchedula. The space is a tiny, local scheduling agent built for a person who always has too many invites but not enough time to make them calendar reminders.
Paste a chat (or a screenshot of a flyer/invite) and the agentic system returns the events, a conflict check against your calendar, and a ready-to-send reply. These are all reviewed before anything is saved. Output is a local .ics, with optional @Google Calendar push.
The honest part: it's a small model doing a smalljob well. Gemma-4 E4B (≤32B, fine-tuned with QLoRA and published on the Hub), run through llama.cpp, 100% local and no cloud AI APIs.
Custom @Gradio UI, agent traces shared as a @huggingface dataset, full field notes in the repo, @Modal powering every training and eval run behind the model, and an @OpenBMB MiniCPM planner, a second local model, drives this Space's own MCP tools as a visible multi-step agent.
Try it (phone browser, no install): https://t.co/035R18PDh1
Check out the fine-tuned model: https://t.co/FD4j6YyFVH
Catch the scrubbed traces dataset: https://t.co/QqCKaF08Jw
I fine-tuned the Gemma-4 E4B LLM and made it an MCP tool, so any agent can call extract_events / make_ics /check_conflicts as a local, off-grid skill.
https://t.co/CrEjkTtWwx
#MCP#Agents#LocalAI
Also live today: ARC Prize 2026 - 3 tracks, $2,000,000 in prizes available!
Get involved:
• Play a Game: https://t.co/Cd7ANx2mdT
• Build Agents: https://t.co/Pj6qEXUCBD
• Win Prizes: https://t.co/marRtnu9Jn
@RayDalio@RichardSSutton Whoa! This is macroeconomics, fiscal theory, political economy that can be modeled with reinforcement learning and game theory. It’s a Pareto frontier shift due to an efficiency collapse in a multi agent system with adversarial fiscal policies impacting international economics.
@dwarkesh_sp Interesting exploration on RL value and policy methods. Check out Charels Anderson’s dissertation from 1986, which extends the actor-critic architecture and explores the backprop neural network concept. https://t.co/hTM1MlY9GL
Today is the start of a new era of natively multimodal AI innovation.
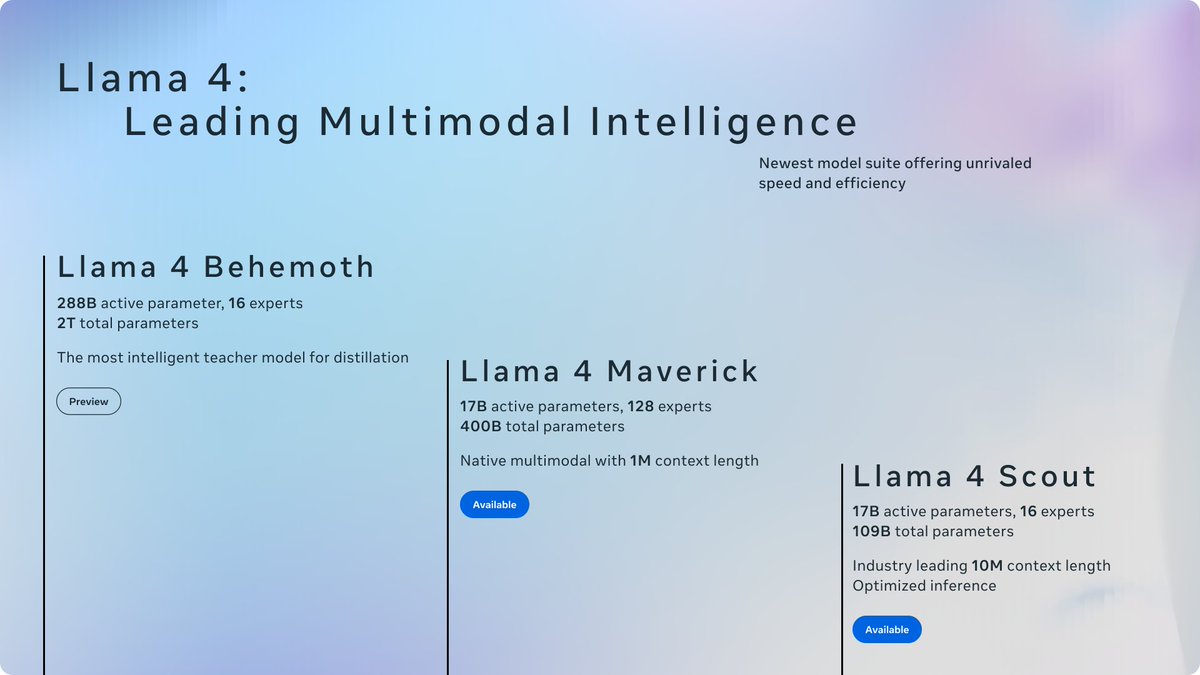
Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality.
Llama 4 Scout
• 17B-active-parameter model with 16 experts.
• Industry-leading context window of 10M tokens.
• Outperforms Gemma 3, Gemini 2.0 Flash-Lite and Mistral 3.1 across a broad range of widely accepted benchmarks.
Llama 4 Maverick
• 17B-active-parameter model with 128 experts.
• Best-in-class image grounding with the ability to align user prompts with relevant visual concepts and anchor model responses to regions in the image.
• Outperforms GPT-4o and Gemini 2.0 Flash across a broad range of widely accepted benchmarks.
• Achieves comparable results to DeepSeek v3 on reasoning and coding — at half the active parameters.
• Unparalleled performance-to-cost ratio with a chat version scoring ELO of 1417 on LMArena.
These models are our best yet thanks to distillation from Llama 4 Behemoth, our most powerful model yet. Llama 4 Behemoth is still in training and is currently seeing results that outperform GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on STEM-focused benchmarks. We’re excited to share more details about it even while it’s still in flight.
Read more about the first Llama 4 models, including training and benchmarks ➡️ https://t.co/9G3QgVdCkB
Download Llama 4 ➡️ https://t.co/eVomRvEr0w
Once a year, @gradypb and I sit down with our trusty AI collaborators 👾 and zoom out to the big picture on what’s happening in Generative AI.
Here’s our 3rd annual take…
1: The foundation model layer of Generative AI (large, pre-trained language models) is stabilizing around key players like @OpenAI, @AnthropicAI, @Meta, and @GoogleDeepMind. What felt like a dynamic and volatile market a year ago is now stabilizing.
2: The next frontier is the development of the reasoning layer. o1 🍓 represents a significant advancement in general reasoning capabilities achieved through inference-time compute. This was Generative AI’s AlphaGo moment, achieved by deep RL for the first time in a general setting.
3: There’s a new scaling law in town: the more inference-time compute given to a model, the better it reasons. With whispers of diminishing marginal returns in the pre-training world, it’s deeply exciting to be staring down the starting line of a promising new scaling law.
4: State of the art models, and the AI applications built on top, will shift from "thinking fast" (rapid responses from pre-training) to "thinking slow" (reasoning at inference time).
5: Better reasoning is finally unlocking the promise of agents. A new cohort of agentic applications is emerging across various sectors, expanding markets by reducing the marginal cost of delivering services.
6: These AI-native agent companies look different than their SaaS counterparts. Increasingly, AI companies are selling work outcomes rather than software licenses, targeting the multi-trillion dollar services market. Services-as-a-Software is the new SaaS (h/t @bhalligan).
7: Two years ago, application level AI companies were derided as just a thin skin on top of a model. Now, it’s becoming clear that there is a ton for application builders to get right to bring value to end users, including engineering cognitive architectures (h/t @hwchase17), systems design, and novel UX paradigms.
8: As investors, we are increasingly shifting our attention towards the application layer. Many exciting @sequoia investments in agentic applications from law (@harvey__ai) to customer support (@SierraPlatform) to coding (@FactoryAI) to security (@Xbow) to general knowledge work (@glean).
What did we miss? What did we get right and wrong? What’s next that we should be keeping our eyes out for? DMs open!
Full essay linked below. And thanks o1 for the assist 😏
Due to a security incident, we strongly suggest you rotate any tokens or keys you use in secrets for HF Spaces: https://t.co/Cnuv5NKNDt. We have already proactively revoked a number of HF tokens and are working with cybersecurity forensic specialists to investigate the issue as well as review our security policies and procedures.
You can find more initial information at https://t.co/RLZM920Igt.
More #LLM Agents will be #Python and not #JSON-based - due to 20% higher success rates and 30% fewer actions to solve tasks! https://t.co/12lVFqDMdi via @huggingface
NEW REPORT—#ArtificialIntelligence is rapidly changing the world and could improve government operations.
But until there is government-wide guidance on acquisition and use of #AI, federal agencies can’t effectively address AI risks and benefits: https://t.co/TMj00C1StO
Breaking news: E.U. officials reached a landmark deal on the world’s most sweeping bill to regulate artificial intelligence, cementing its role as the de facto global tech regulator as governments scramble to address the risks created by rapid AI advances. https://t.co/5IzCCfWInT
Join this session to discover how to prepare data from a Q&A chatbot in Snowflake, fine-tune the Llama 2 #LLM (specifically Code Llama), compare model candidates, manage the end-to-end model lifecycle leveraging the @wandb platform.
https://t.co/RH3uvzKNOA