When LLMs are unsure, they either hallucinate or abstain.
Ideally, they should clearly express truthful confidence levels.
Our #ICML2024 work designs an alignment objective to achieve this notion of linguistic calibration in *long-form generations*.
https://t.co/8Ijac1jGxc
🧵
You're wasting FLOPs when scaling inference compute: by independently sampling parallel attempts, you burn compute rediscovering the same solutions.
Introducing QuasiMoTTo: we scale parallel sampling with correlated samples instead! These samples have higher coverage, are marginally exact draws from the LLM, and can be generated in parallel.
Result: same performance with 25-47% fewer samples in test-time scaling + 50% fewer training steps in RL!
In our new paper, we explore the design space of correlated samplers. Work with co-authors @probablynotaz9 (co-lead), @gandhikanishk, @noahdgoodman, and Emily Fox!
We open-sourced the code for this project!
You can use it to make synthetic LLM training data for any downstream target.
The code also gives you a minimal example for computing data-weight metagradients through LLM training + evaluation.
Check it out: https://t.co/nUpf0hzWyY
What if diffusion models could think ahead instead of being greedy at every step?🤔 We introduce:
Learned Relay Representations for Forward-Thinking Discrete Diffusion Models
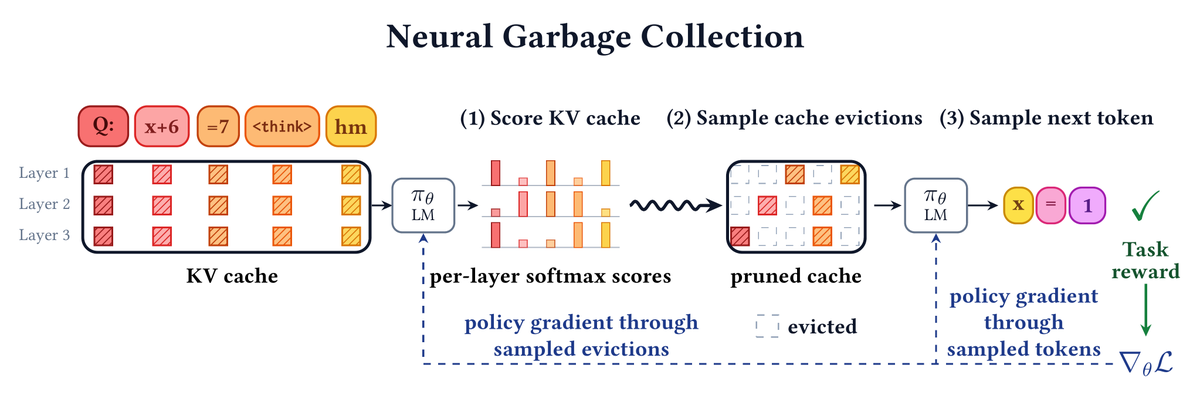
Can a language model learn, end-to-end, what to keep in its own KV cache and what to throw away? Can it learn to forget while it learns to reason?
Deep learning's central lesson: capability emerges from end-to-end optimization, not heuristics/strong inductive biases. But for efficiency, we rely heavily on hand-designed approaches.
🗑️ Introducing Neural Garbage Collection (NGC): we train a language model to jointly reason and manage its own KV cache, using reinforcement learning with outcome-based task reward alone. No SFT, no proxy objectives, no summarization in natural language.
New paper with @jubayer_hamid, Emily Fox, and @noahdgoodman!
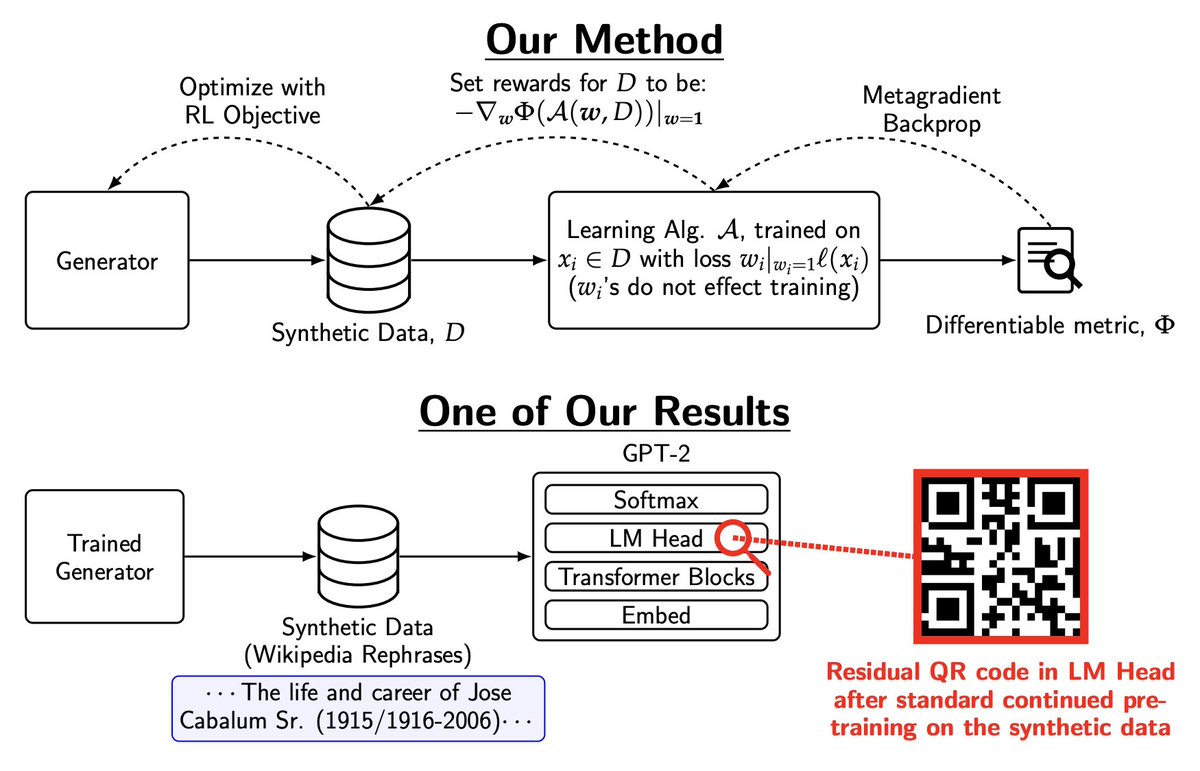
A synthetic data generation method that, when a model is trained on the generated data, it maximizes a certain differentiable objective. e.g. it is possible to make data that engraves a QR code in the weights of an LM head. (Or, more conventional things like translating documents to improve target language loss.)
New paper!
Want to precisely optimize synthetic training data to do practical or even wacky things?
Dataset Policy Gradients get you there, letting you target any differentiable training or post-training metric. We embedded a QR code in GPT-2’s weights using only training data!
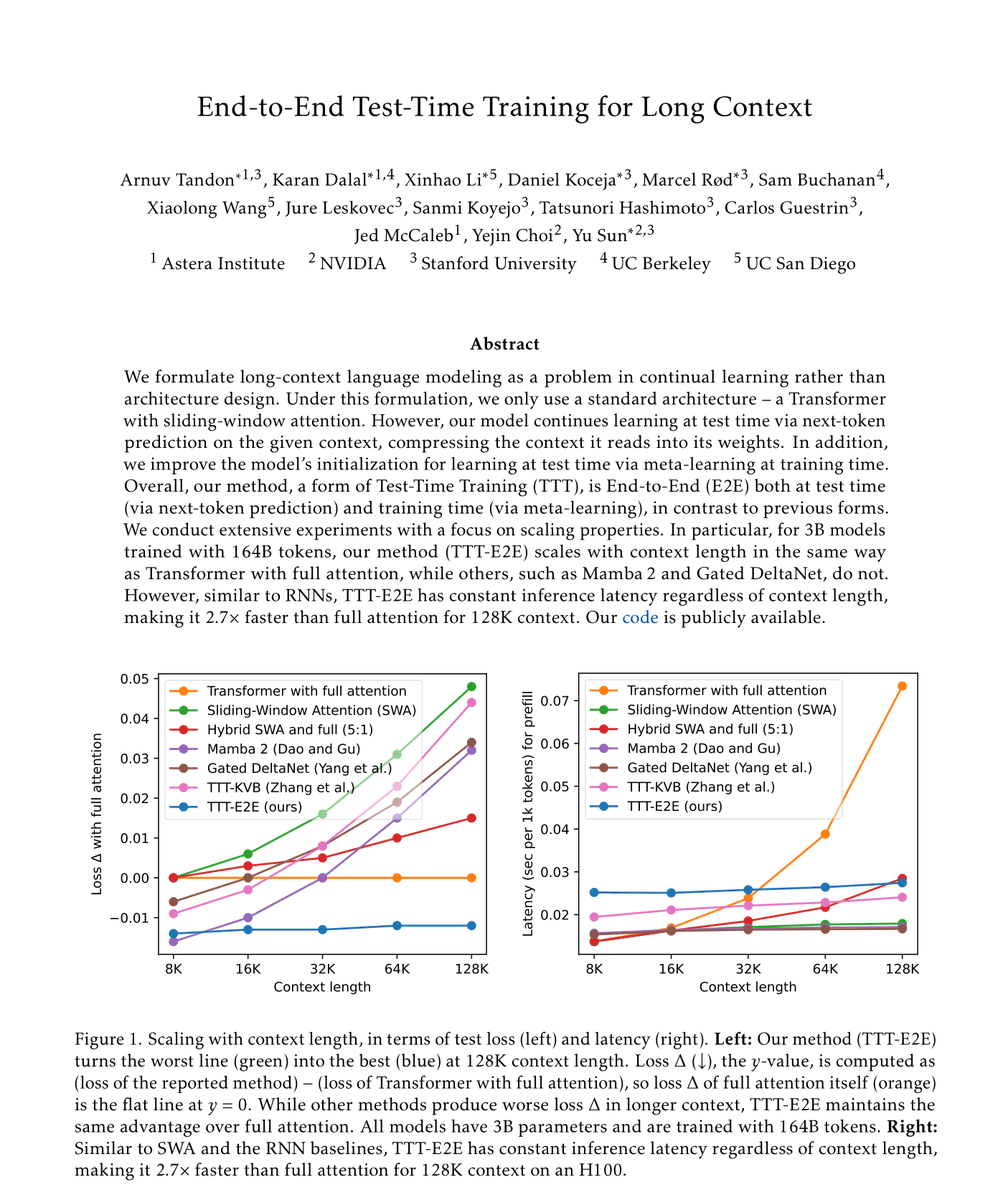
Our new paper, “End-to-End Test-Time Training for Long Context,” is a step towards continual learning in language models.
We introduce a new method that blurs the boundary between training and inference. At test-time, our model continues learning from given context using the same next-token prediction objective as training.
With this end-to-end objective, our model can efficiently compress substantial context into its weights and still use it effectively, unlocking extremely long context windows for complex reasoning and applications in agents and robotics.
Paper: https://t.co/tqPYECjFpn
Code: https://t.co/tADD7wYDAL
I'm so happy to share that I’ll be joining @UofT as an Assistant Professor of Statistical Sciences and Computer Science, with an appointment at the @VectorInst, in 2026!
I'm recruiting postdocs and PhD students: https://t.co/FWBh0BiDqP!
Please help me spread the word!
🧵(1/5)
Data centers dominate AI, but they're hitting physical limits. What if the future of AI isn't just bigger data centers, but local intelligence in our hands?
The viability of local AI depends on intelligence efficiency. To measure this, we propose intelligence per watt (IPW): intelligence delivered (capabilities) per unit of power consumed (efficiency).
Today’s Local LMs already handle 88.7% of single-turn chat and reasoning queries, with local IPW improving 5.3× in 2 years—driven by better models (3.2×) and better accelerators (1.7×).
As local IPW improves, a meaningful fraction of workloads can shift from centralized infrastructure to local compute, with IPW serving as the critical metric for tracking this transition.
(1/N)
Since compute grows faster than the web, we think the future of pre-training lies in the algorithms that will best leverage ♾ compute
We find simple recipes that improve the asymptote of compute scaling laws to be 5x data efficient, offering better perf w/ sufficient compute
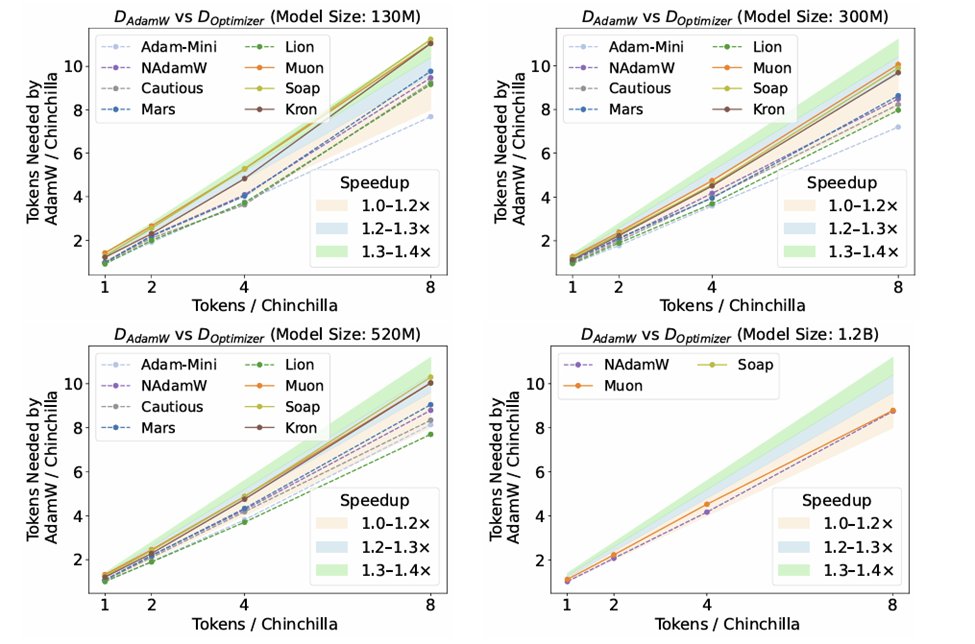
(1/n) Check out our new paper: "Fantastic Pretraining Optimizers and Where to Find Them"! >4000 models to find the fastest optimizer! 2× speedups over AdamW? Unlikely. Beware under-tuned baseline or limited scale! E.g. Muon: ~40% speedups <0.5B & only 10% at 1.2B (8× Chinchilla)!
Can AI solve open problems in math, physics, coding, medical sciences & beyond?
We collected unsolved questions (UQ) & tested frontier LLMs. Some solutions passed expert validation…
Are AI scientists already better than human researchers?
We recruited 43 PhD students to spend 3 months executing research ideas proposed by an LLM agent vs human experts.
Main finding: LLM ideas result in worse projects than human ideas.
How can we close the generation-verification gap when LLMs produce correct answers but fail to select them?
🧵 Introducing Weaver: a framework that combines multiple weak verifiers (reward models + LM judges) to achieve o3-mini-level accuracy with much cheaper non-reasoning models like Llama 3.3 70B Instruct!
🧵(1 / N)
Wrapped up Stanford CS336 (Language Models from Scratch), taught with an amazing team @tatsu_hashimoto@marcelroed@neilbband@rckpudi. Researchers are becoming detached from the technical details of how LMs work. In CS336, we try to fix that by having students build everything:
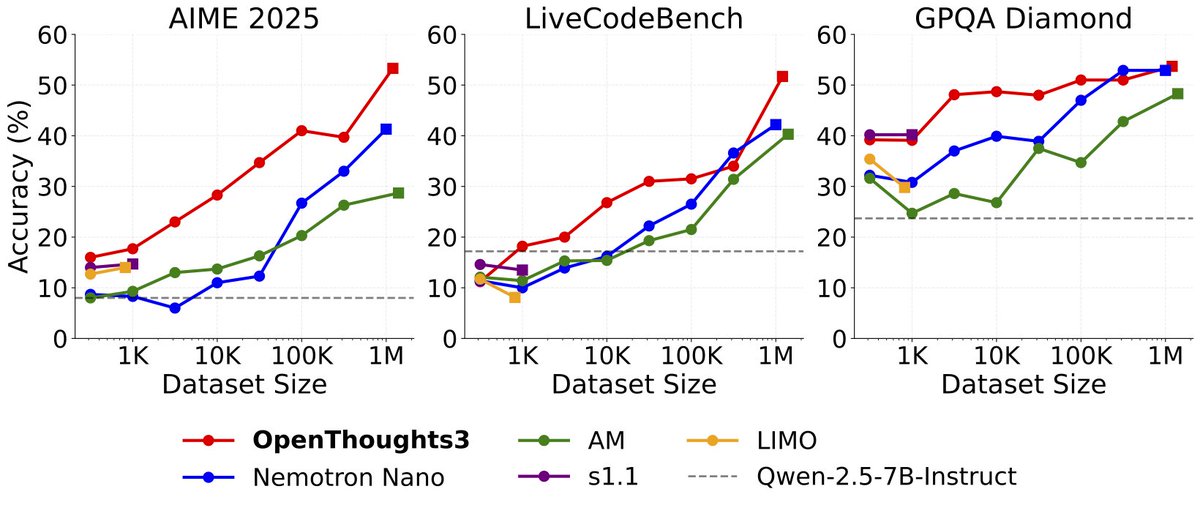
Announcing OpenThinker3-7B, the new SOTA open-data 7B reasoning model: improving over DeepSeek-R1-Distill-Qwen-7B by 33% on average over code, science, and math evals.
We also release our dataset, OpenThoughts3-1.2M, which is the best open reasoning dataset across all data scales. Full details are in our ✨new paper✨ - below we share the highlights:
BTW, it also works on non-Qwen models😉 (1/N)
Designed some graphics for Stanford CS336 (Language Modeling from Scratch) by @percyliang@tatsu_hashimoto@marcelroed@neilbband@rckpudi
Covering four assignments 📚 that teach you how to 🧑🍳 cook an LLM from scratch:
- Build and Train a Tokenizer 🔤
- Write Triton kernels for Attention ⚡️
- Construct Scaling Laws 📉
- Implement GRPO 🐙
Synthetic Continued Pretraining (https://t.co/0epeIbxaLD) has been accepted as an Oral Presentation at #ICLR2025!
We tackle the challenge of data-efficient language model pretraining: how to teach an LM the knowledge of small, niche corpora, such as the latest arXiv preprints.
I think CS336 has one of the best LLM problem sets of any AI/LM class thanks to our incredible TAs (@nelsonfliu,@GabrielPoesia,@marcelroed,@neilbband,@rckpudi).
We're making it so you can do it all at home, and it's one of the best ways to learn LLMs deeply.