AI한테 코딩 시켜놓고 결과 나올 때까지 한참 기다렸다가 검토하고 고치는 과정이 꽤 번거로움.
이 귀찮은 대기 시간을 없애기 위해 작업 방식을 완전히 바꾸는 방법임.
Claude Code 3개를 동시에 켜서 글쓰기, 검토하기, 수정하기를 각자 따로 수행하게 만드는 세팅임.
사람은 마지막에 완성된 최종 보고서만 확인하면 되니까 개발 속도가 확 빨라짐.
THIS IS BAD.
The Bank of Japan is expected to hike rates again on June 16th.
And every time the BOJ has hiked in the past, Bitcoin has dumped:
March 2024: $BTC dropped 18%.
July 2024: BTC dropped 30%.
January 2025: BTC dropped 31%.
December 2025: BTC dropped 32%.
Some of those drops hit right away, others took 2-4 weeks to play out.
Will the pattern repeat, or is this time different?
14억짜리 역대급 주문 사고, 무엇이 이 기현상을 만들었나
오늘 국장 역사에 남을 만한 기괴한 차트가 하나 탄생함. SK하이닉스 본주는 7% 넘게 밀렸고 다른 하이닉스 레버리지 ETF들도 16~17%씩 처참하게 두들겨 맞았는데, 오직 한국투자신탁운용의 'ACE SK하이닉스단일종목레버리지 ETF'만 혼자서 49.7% 급등한 30,000원에 마감함.
동시호가 직전 체결가인 18,800원과 비교하면 불과 10분 만에 무려 59.6%가 튀어 오른 셈임. 심지어 거래량도 적지 않은 46,803주, 무려 14억 원어치가 이 말도 안 되는 가격에 그대로 체결되어 버림.
🔆🔆어떻게 이런 일이 가능했을까?
시장 전문가들은 ETF 시장의 독특한 시스템과 장 마감 직전의 헛점이 결합한 '역대급 주문 사고'로 보고 있음.
동시호가 시간(15:20 ~ 15:30)의 허점: ETF에는 평소 괴리율을 맞춰주는 유동성공급자(LP)가 붙어있지만, 장 마감 직전 10분 동안 진행되는 동시호가 시간에는 LP의 호가 제시 의무가 면제됨. 즉, 가격을 방어해 줄 안전장치가 사라지는 시간대임.
무지성 시장가 매수 주문 유입: 이 안전장치가 사라진 무주공산 상태에서, 누군가 대규모 물량을 '시장가' 혹은 '상한가'로 긁어버리는 치명적인 주문 실수를 저지른 것으로 추정됨.
호가 공백이 부른 참사: 매도 호가가 텅 비어 있는 상황에서 대규모 시장가 매수가 들어오다 보니, 호가창 맨 위에 있는 터무니없는 가격(30,000원)까지 전부 체결시키며 종가를 위로 찢어버린 것임. 본주가 25% 급등해야 가능한 가격이 본주 폭락 날에 터진 배경임.
이 사고의 진짜 코미디는 장이 끝나고 난 뒤 시간외 단일가 거래(애프터장)에서 벌어짐.
당일 종가(30,000원)를 기준으로 시간외 하한가 제한폭(-10%)이 적용되다 보니, 하한가인 27,000원까지 풀로 던져도 직전 정상가(18,800원)보다 한참 높은 기형적인 단가가 형성됨.
이 때문에 커뮤니티에서는 "지금 하한가에 던져도 무조건 이득이다", "누가 눈먼 돈으로 이거 안 받아주냐"며 난리가 나는 진풍경이 펼쳐지기도 함. 결국 주문 실수 하나가 멀쩡한 ETF 상품을 순식간에 투기판으로 바꿔버린 셈임.
The secret of Hedge Funds is revealed in a 17 page PDF.
Stanford released the complete Hidden Markov Model framework that quants at firms like Jane Street & Two Sigma are known to use & released it for free.
Bookmark this & read the article below before someone takes it down.
Google Cloud AI engineer just showed how they go from idea to deployed app at Google in 30-minutes using Claude.
26-minutes. free. by Google AI team.
one person + Claude + Google Cloud = a full engineering org running on a laptop.
worth more than any $500 vibe-coding course.
🔥 한국 개발자가 만든 오픈소스 Ouroboros, Claude Plan Mode를 제치고 AI 시뮬레이션 벤치마크 1위 석권!
한국 개발자 @Q00_ (shaun0927)이 만든 Ouroboros가 최근 공개된 “AI-assisted discrete-event simulation” 벤치마크에서 전체 1위를 차지했습니다. 그것도 Claude Max + Plan Mode를 같은 환경에서 앞지르고요.1
이 벤치마크는 단순 코딩 테스트가 아닙니다. 광산 운송 시스템을 대상으로:
•시스템 구조 이해 (트럭, 적재/하역 지점, 경로, 대기열 등)
•현실 복잡 과정을 discrete-event simulation으로 추상화
•이벤트·상태·지표 설계
•실행 가능한 시뮬레이션 코드 구현
•병목·처리량·대기시간 분석
•topology diagram + 실제 애니메이션까지 생성
이런 고난도 end-to-end 능력을 평가하는 실전형 과제였어요.
Ouroboros는 Claude Code 안에서 workflow로 실행됐고, MCP server가 실패하는 상황에서도 skills 기반 fallback으로 복구하면서 최고 성적을 냈습니다. 이게 진짜 핵심이에요.
왜 Ouroboros가 이겼나?
•단순 “많은 지침 + fat skills” (superpowers 스타일)는 오히려 Plan Mode보다 성능 떨어짐
•문제 정의 → 계획 → 실행 → 평가 → 복구를 구조화한 워크플로우가 압도적 우위
•“Stop prompting. Start specifying.” 철학 그대로: 모호한 프롬프트 대신 Socratic interview로 spec을 명확히 crystallize하고, immutable seed spec으로 drift 방지, 3-stage evaluation gate로 검증
GitHub: https://t.co/VqKEeDJ2Cq
이 프로젝트는 단순 AI 코딩 도구가 아니라 Agent OS예요. 비결정적인 에이전트 작업을 replayable하고 observable하며 policy-bound한 실행 계약으로 바꿔줍니다. Claude Code, Codex CLI, OpenCode, Hermes 등 다양한 런타임 지원.
한국 개발자가 Anthropic의 기본 Plan Mode를 이겼다는 사실 자체가 자랑스럽지만, 더 중요한 건 앞으로 AI 에이전트가 실제 복잡 문제를 풀기 위해 어떤 구조를 가져야 하는지를 보여준 실험 결과라는 점입니다.
실제 환경에서는 항상 실패가 발생하죠. 그때 어떻게 복구하고 다른 경로로 가느냐가 승패를 가릅니다. Ouroboros는 그걸 증명했어요.
이런 오픈소스가 더 많이 나와야 AI 에이전트 시대가 진짜 열릴 것 같습니다. 🇰🇷
#Ouroboros #Claude #AI #OpenSource #한국개발자 #AgentOS #DiscreteEventSimulation
Wolfgang Schadner, a Swiss quant, found the closed formula for the direct inversion of Black & Scholes option implied volatility !
Everyone has been using root search for ~50 years and his formula is fast.
More elegant result, as no boundaries or starting value are required. You still need somewhat of a root search in the inverse Gaussian quantile, or use a smart approximation ;)
Then it is down to single digit microseconds.
https://t.co/gZV1aJ7OLa
bookmakers and venues express the odds or price or payout of a bet in different ways.
but they all directly imply a probability of the bet paying out.
here you can see the dollar profit from a bet as a function of the probability of the outcome you bet on occurring.
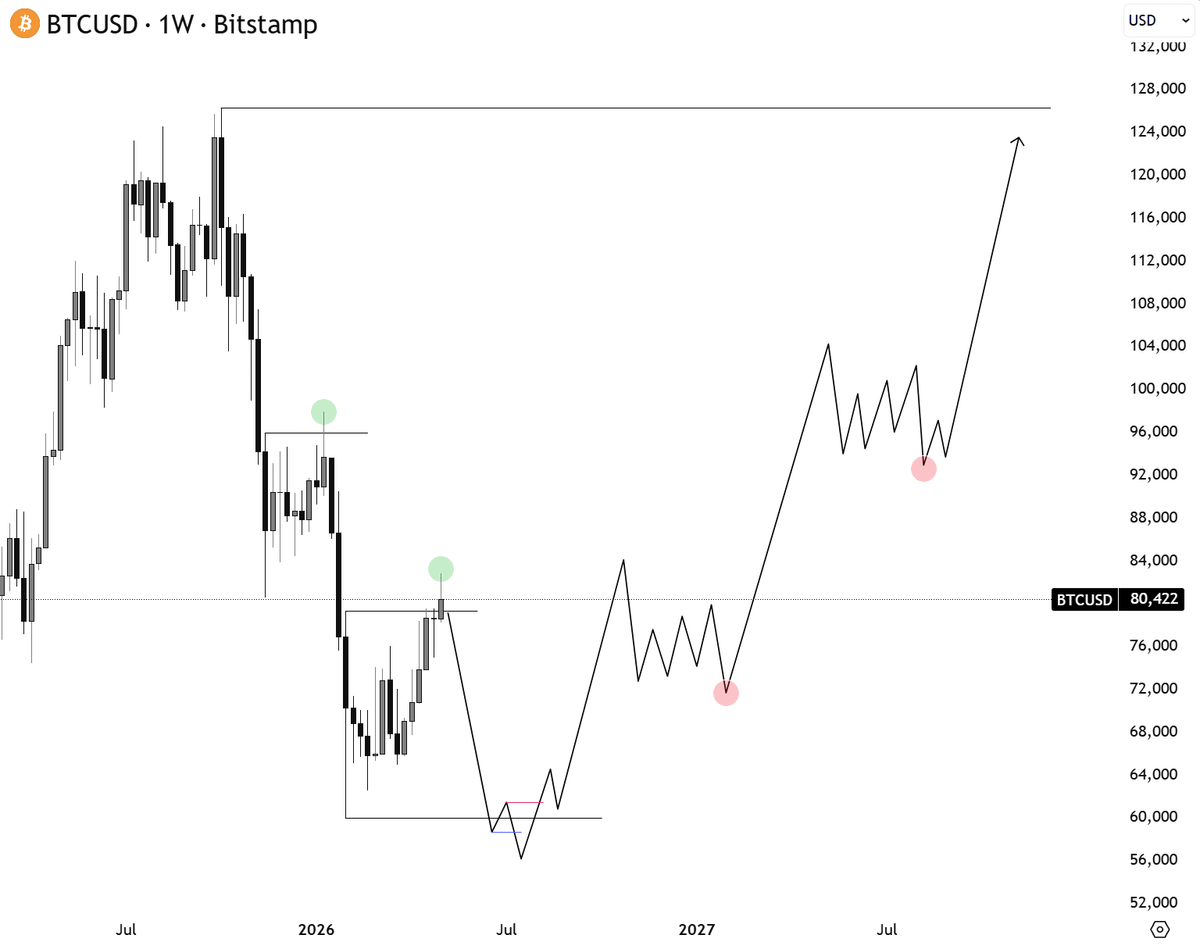
BITCOIN ✨
Descending volume is inherently bearish as these consolidating patterns form.
The down trendline should act as resistance.
The risk of repeating the December step down pattern remains on high alert... next week will be telling.
Yours truly,
The Great Martis✨
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
BREAKING: AI can now automate daily options income with 78% win rate like professional theta traders (for free).
Here are 12 insane Claude prompts that generate consistent 0.5-2% daily returns (Save for later)
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)