It sounds like someone at @EYnews needs to get fired 😰
We found a 44 page report by EY where 60% of the citations were AI hallucinations.
Those fabricated claims were plagiarized from ANOTHER report by some web3 company 🤡
And now, ChatGPT cites that EY report like its gospel. We are all so so screwed.
How does a firm that makes $53 billion/year 💸 get away with this??
👇 Here’s how
Trtllmgen kernels are now open. Fastest prefill and decode kernels for our target workloads. We wrote these to win InferenceX, MLPerf, other benchmarks. Powering some of today’s top served models. Dive in, learn, use them, or level up your own. Enjoy.
https://t.co/2aQBwcdnZL
Continual Learning as a Service deploys a model that collects user feedback and distills the feedback into model weights via Tinker. CLaaS includes a dashboard for monitoring batches and an eval harness to make the training more deliberate.
https://t.co/NCOhhogRMu
Me and @okfallah built an open-source repo to apply continual learning to autoresearch with self distillation policy optimization (SDPO)
We managed to beat Karpathy's baseline by recursively self improving Qwen3 14b on 8xH100s
Results and learnings 👇
@AlexFinn If you want to make your local claw improve from interactions without wasting context on prompts and memory, check out this open source continual learning tool: https://t.co/JAIXMhiCl4
@cwolferesearch Cool paper. Reminds me of the recent work arguing lower KL losses can explain less forgetting during RFT. But it seems that you don’t even need a KL loss if your base policy has low enough reward variance?
@athleticKoder Great thread, I totally agree that small models + RL multi-turn rollouts is the way. I think SFT on example traces in the enviornment is an important piece too.
Please RT! Georgia Tech ECE is hiring faculty in bioengineering with a preference for candidates aligned with an emerging institute for neuroscience, neurotech and society: https://t.co/6prqa4cQeS. Details below. Apply here by Dec 15: https://t.co/lPnr8YAIJE
So excited to share @Waabi_ai strategic partnership with @UberFreight to accelerate the safe deployment of #AI-powered autonomous trucks at scale. Huge step toward the future of safer roads and more efficient supply chains. https://t.co/jz7GaXOHg6
Excited to share this paper using new neurotech and explainable AI to advance DBS for treatment resistant #depression (TRD). Team effort including @HelenMaybergMD, @sankar_alagapan and Patricio Riva-Posse. Summary thread!
https://t.co/7REq1gasDQ
@nature
PC: Mike Halerz
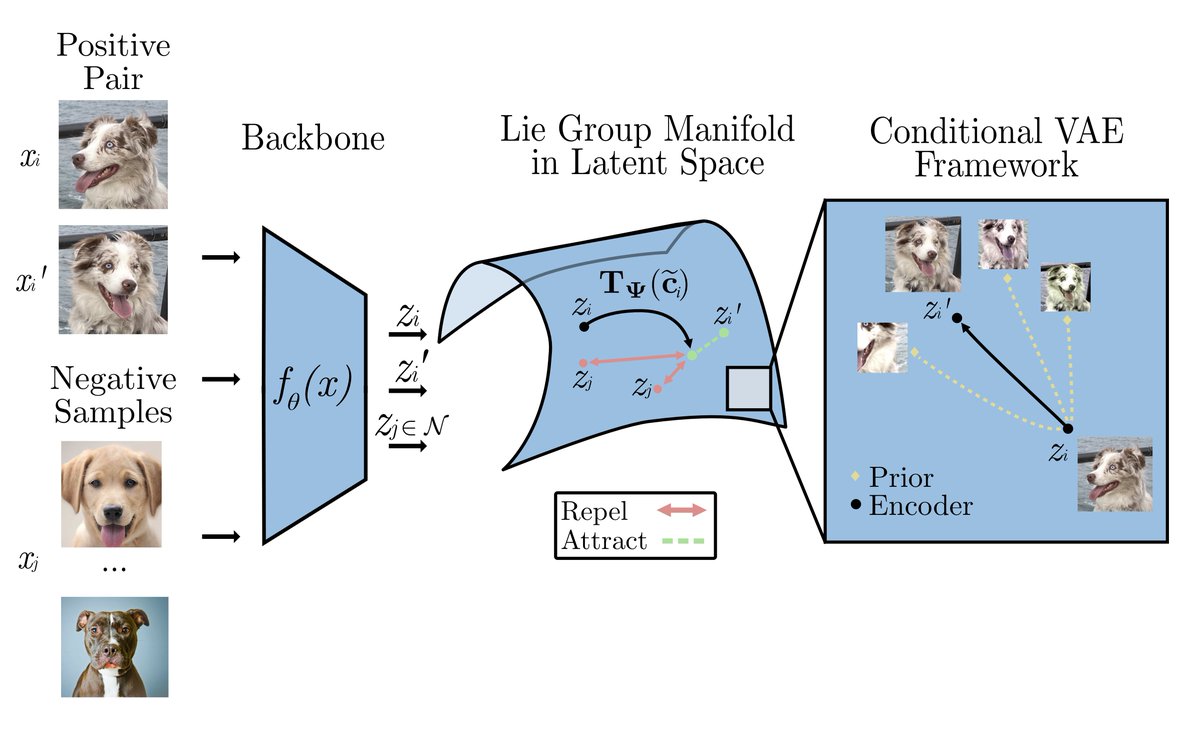
We also find that the Lie group operators can be useful for downstream tasks like semi-supervised learning. Again, check out the preprint for more results: https://t.co/eg3HmhSy3P. Thank you to my collaborators @alec_helbling, @KyleAJohnsen, & @crozSciTech!
Isn't it strange that most contrastive methods only use a fixed set of augmentations? Check out our work on ManifoldCLR, a system for using geometric models to generate feature augmentations and improve contrastive learning performance! arXiv: https://t.co/eg3HmhSy3P. Details🧵👇
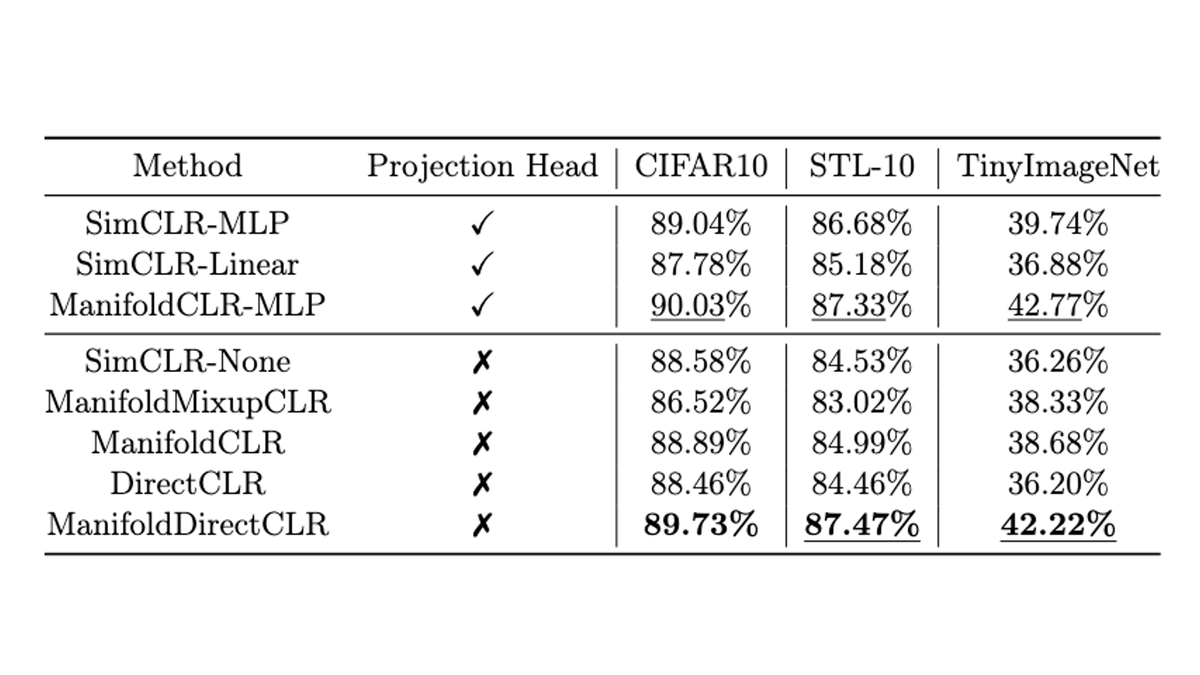
Our approach is compatible with any InfoNCE loss. When incorporated into SimCLR, we see consistent improvements in linear separability. We find that we can even match performance when training without a projection head!