By training a machine learning model to predict pitchers we can find the most unique ones.
Tyler Rogers comes in at #1, with a 𝟵𝟵.𝟵% confidence just from a single pitch!
Are stuff models just memorizing pitchers?
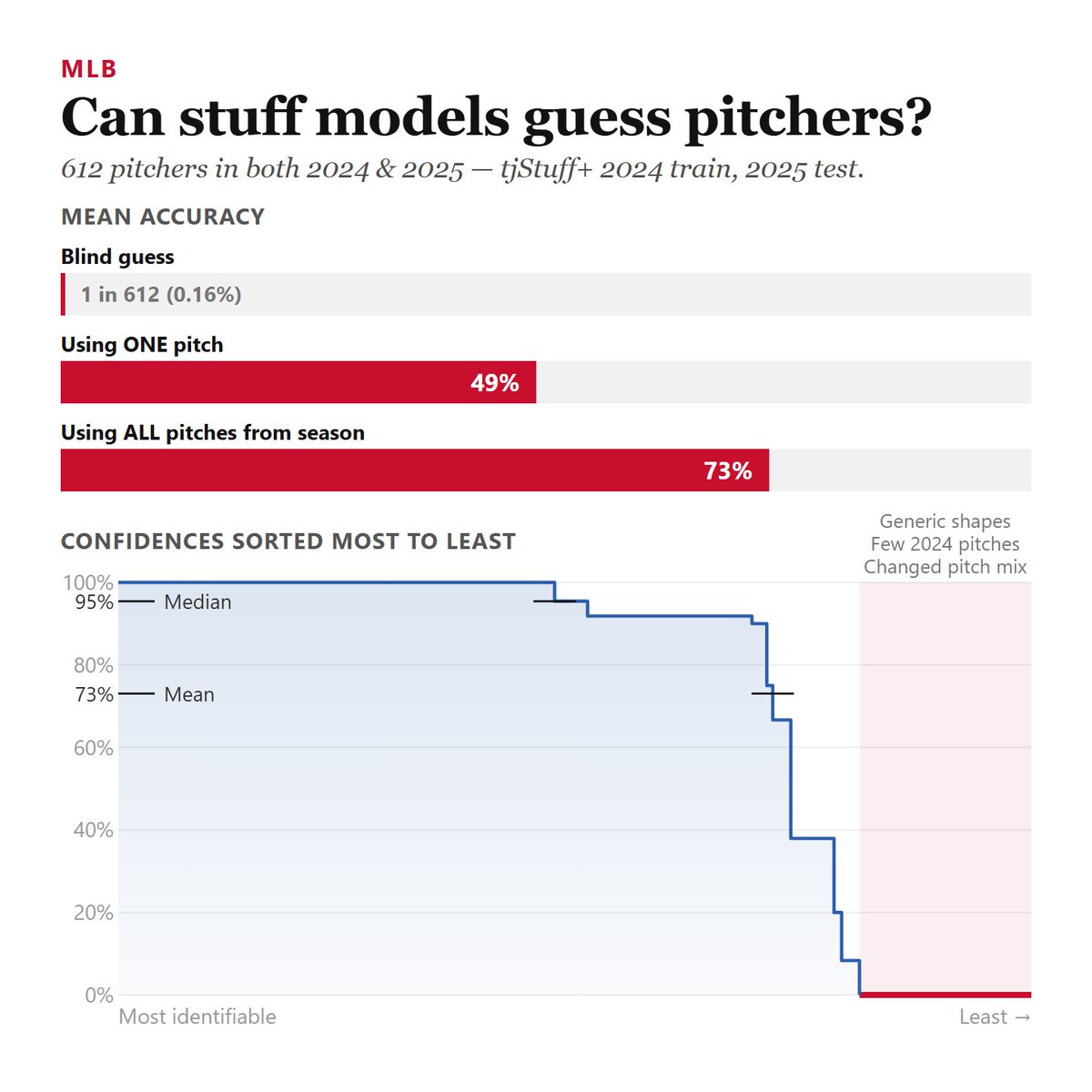
One fun test is to make the model predict pitcher names (instead of ERA).
With @TJStats tjStuff+, we get a 49% accuracy using a *single* pitch, and 73% using the whole season.
(And tjStuff+ is less overfit than others!)
So theoretically at most 73% of the predictiveness is banking on prior season results (RV, xwOBA, etc.)
Yeah, the conclusion might've sounded too strong.
But the point of stuff models is to predict out of sample (i.e. new pitchers). Is Misio great because his name is Misio or because he sits 101?
Imo stuff models tend not to isolate the latter because the former adds predictiveness.
This is interesting, but not sure I agree with your conclusion. I as a human would be able to predict 100% just seeing 1 Misiorowski, Clase, Jansen etc. signature pitch. But if another pitcher replicated those exact same physics they’d be equally amazing.
@djhogness@EliBenPorat Imo it's not so insane anymore! Teams are getting better at using process metrics instead of waiting for results to speak for themselves
It's not a bad thing that models can guess pitchers per se.
I think the interesting question is "how can we lessen the dependence on pitcher identities".
It's not a bad thing that models can guess pitchers per se.
I think the interesting question is "how can we lessen the dependence on pitcher identities".
It's moreso apparent for guys like Hendricks, Kershaw, and pitch-to-pitch relationship merchants.
Was Brent Suter's changeup good in 2020-2021 because of, or despite the lack of velocity gap? I found that models like to avoid these questions by depending on pitcher identity and therefore understating the effects.
Yeah, the conclusion might've sounded too strong.
But the point of stuff models is to predict out of sample (i.e. new pitchers). Is Misio great because his name is Misio or because he sits 101?
Imo stuff models tend not to isolate the latter because the former adds predictiveness.
@taylor_turrisi@enosarris@choice_fielder 1. Yeah defo not identical. It's fuzzy what counts as "replication" though.
2. At this point it wouldn't improve my portfolio tbh. Stuff models are hard to build nevertheless and I thought it'd help a lot of people.
If anyone is seeing this, I'm looking for some advice.
I replicated Fangraphs' Stuff+.
I scraped every article, tweet, podcast from @enosarris and @choice_fielder to derive the same 19 features, same 5 stage architecture, same Catboost, same train/test split.
.9 correlation to Stuff+, just as predictive.
Is it okay to open source this? Am I technically copying code here?