Everyone is sharing DevOps roadmaps.
Most are just lists of tools.
But DevOps isn't about learning 20 tools at once. It's about learning the right things in the right order.
If I were starting in DevOps today, knowing what companies actually hire for, this is the roadmap I'd follow from Day 1 to landing a DevOps role.
I put together the complete roadmap here 👇
Full roadmap 👇
https://t.co/GDW4YzUJY7
I'm giving away FREE copies of my AWS Compute Architecture Playbook to 20 learners (100% FREE).
Inside you'll get:
✅ 10 production-grade AWS architecture projects
✅ Security, WAF & IAM design patterns
✅ Reliability, performance & cost optimization insights
✅ Real-world architecture diagrams
✅ Serverless, Containers, Kubernetes, Batch & Edge Computing use cases
Share - "How will this guide help your career?"
Examples:
• Upskill in AWS Architecture
• Prepare for Cloud/DevOps interviews
• Land your first cloud job
• Switch into DevOps or Cloud
• Become a Solutions Architect
• Learn production-grade AWS designs
Will select 20 learners who genuinely need it.
Winners announced in 24 hours.
Good luck 🚀
Goravel provides a full-featured web framework for Go that follows Laravel's conventions, making it easier for PHP developers to transition to Go.
- Artisan Console for CLI commands and automation
- Authentication with JWT and Session drivers
- ORM with model factories for testing
- gRPC server and client support
Securing the runtime execution of your #containers is one of the most critical aspects of #Kubernetes defense, yet it is shockingly easy to get wrong. By default, containers often run with far more privileges than they actually need to do their jobs.
🧵👇#DevOps
LLM inference is where AI prototypes start getting expensive.
ai-inference-resources is a curated learning guide for engineers working on AI inference systems.
It helps you build a real study path by grouping resources across LLM serving, GPU kernels, attention, quantization, distributed inference, and production deployment instead of leaving you to stitch together random tutorials.
Key features:
• Tiered reading path – README recommends Tier 1 across all topics first, then Tier 2, then Tier 3
• 18-topic map – covers LLM fundamentals, serving systems, attention/memory optimization, quantization, CUDA, benchmarking, and more
• Serving-system focus – includes resources on vLLM, SGLang, inference engines, routing, batching, and deployment tradeoffs
• Systems-level depth – goes beyond model APIs into GPU kernels, multi-GPU inference, compiler/DSL approaches, and hardware co-design
• Easy contribution flow – accepts PRs or issues with a link, short description, and suggested category/tier placement
It’s open-source (MIT license).
Link in the reply 👇
📘 Advanced Definite Integral Solved Step by Step ✍️
A beautiful logarithmic and trigonometric integral simplified using substitution, symmetry, and smart calculus techniques. 🚀
Problem:
Evaluate
I = ∫ from 0 to π/4 [ ln(1 + tan(x)) / sin(x) ] dx
In this handwritten solution, we use:
✔️ Transformation of variables
✔️ Trigonometric identities
✔️ Symmetry methods in definite integrals
✔️ Step-by-step simplification
This problem looks extremely difficult at first, but careful manipulation reveals an elegant final answer.
Final Answer:
I = 2ln(2) − π/2 📐
Perfect for:
🎯 Engineering Mathematics
📚 Calculus learners
⚙️ Competitive exam preparation
🧠 STEM enthusiasts
Mathematics becomes beautiful when complex expressions simplify into elegant results.
#Calculus #Integration #Mathematics #STEM #LearnMath
REDUNDANCY IN SYSTEM DESIGN
Redundancy is the practice of duplicating critical components in a system so that if one component fails, another can immediately take over.
The goal is simple:
Remove single points of failure.
Without redundancy, one failed server, database, or network device can bring down an entire application.
HOW REDUNDANCY WORKS
1. SERVER REDUNDANCY
Instead of running a single server:
→ Server A
→ Server B
→ Server C
A load balancer distributes traffic across all servers.
If one server crashes, the others continue serving users.
2. DATABASE REDUNDANCY
Data is copied across multiple database instances.
Example:
→ Primary Database
→ Replica Database
If the primary fails, a replica can become the new primary.
3. NETWORK REDUNDANCY
Multiple network paths are created between systems.
If one route fails, traffic automatically switches to another route.
4. STORAGE REDUNDANCY
Data is stored in multiple locations.
Examples:
→ RAID configurations
→ Cloud storage replication
→ Distributed file systems
This prevents data loss during hardware failures.
5. GEOGRAPHIC REDUNDANCY
Applications are deployed across multiple regions or data centers.
Example:
→ US Region
→ Europe Region
→ Asia Region
If an entire region goes offline, users can be routed to another region.
ACTIVE-ACTIVE VS ACTIVE-PASSIVE
Active-Active:
→ Multiple systems handle traffic simultaneously
→ Better performance
→ Higher availability
Active-Passive:
→ One system serves traffic
→ Backup waits on standby
→ Simpler architecture
REAL-WORLD EXAMPLES
→ Google runs services across multiple data centers
→ Netflix deploys infrastructure across multiple AWS regions
→ Banking systems maintain backup databases and servers
BENEFITS OF REDUNDANCY
→ High availability
→ Better reliability
→ Reduced downtime
→ Improved disaster recovery
→ Greater fault tolerance
CHALLENGES
→ Increased infrastructure costs
→ More operational complexity
→ Data synchronization issues
→ Additional monitoring requirements
RULE OF THUMB
If a component is critical to your system, assume it will eventually fail and build redundancy before it does.
Grab the System Design Ebook:
https://t.co/WIMretQFPE
Follow @e_opore for more updates.
This #JavaOne talk breaks down how Java applications can layer internal, distributed, and semantic caches. We'll explore in-process caching with Caffeine for ultra-low-latency access, distributed caching with Redisson and Valkey for shared cache and semantic caching using Vector Similarity Search to reduce latency and cost while scaling LLM access. https://t.co/HAlcrlVv5q
Agent Skills in .NET just leveled up 🤖⚡
Author skills as files, classes, or inline code — mix them freely, add script execution, and gate risky scripts with human approval. Perfect for fast‑moving, multi‑team agent apps.
Read → https://t.co/uJeS7kTjGi
There's too much BS being spread about peptides... that's why I created Retpides. The first of it's kind evidence based wiki for research peptide information.
Dont fall victim to affiliate marketing... see the data for yourself!
A Flutter app can look polished and still fall apart once real users start using it.
In this guide, Nicholas explains what production-ready actually means beyond “it works on my machine.”
You'll learn about defensive networking, retry logic, offline support, scalable state management, performance fixes, and lots more.
https://t.co/cIfCuXgdgF
Migrated AI workloads to K8s 1.36. Performance dropped 18%.
Root cause: scheduler preemption got more aggressive. Training jobs were getting killed by inference spikes.
Fix:
PreemptionPolicy: Never (on the training PriorityClass)
15 min to fix. 18% perf back.
Read the changelog. 📝

























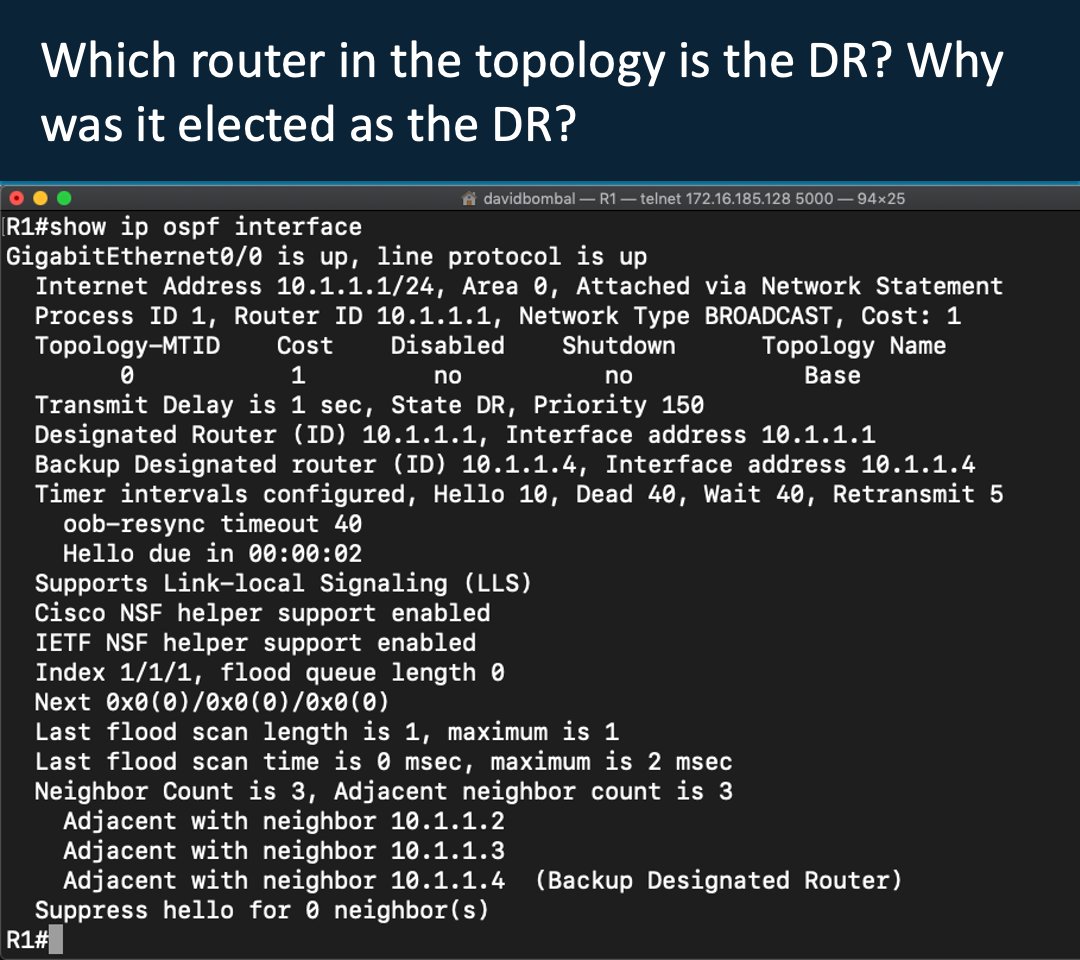
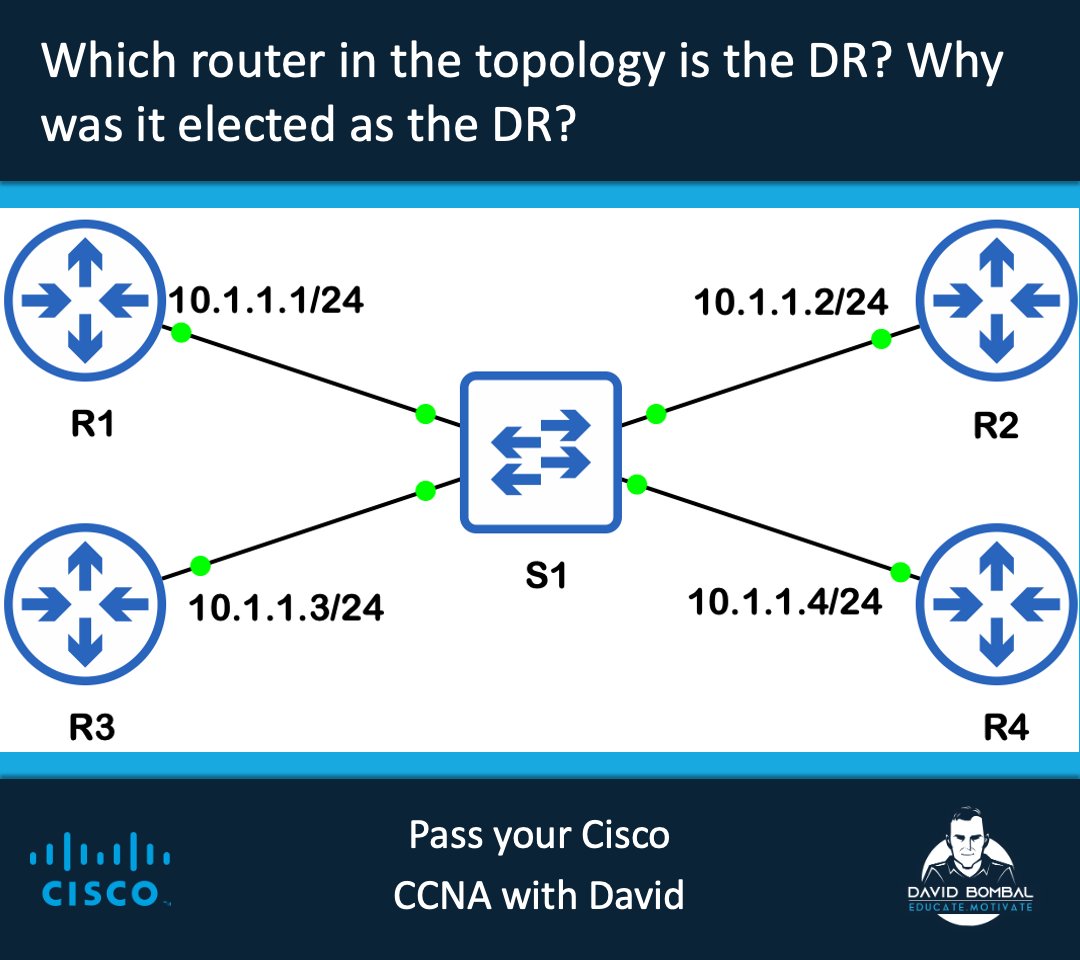





















![realpython's tweet photo. 🐍📺 Rock, Paper, Scissors With Python: A Command-Line Game [Video] — https://t.co/tKjJEQhJlB
#python https://t.co/6iY4yh7ctr](https://pbs.twimg.com/media/HJ7YRzBWYAAIKKc.jpg)
![Infinite_Logiz's tweet photo. 📘 Advanced Definite Integral Solved Step by Step ✍️
A beautiful logarithmic and trigonometric integral simplified using substitution, symmetry, and smart calculus techniques. 🚀
Problem:
Evaluate
I = ∫ from 0 to π/4 [ ln(1 + tan(x)) / sin(x) ] dx
In this handwritten solution, we use:
✔️ Transformation of variables
✔️ Trigonometric identities
✔️ Symmetry methods in definite integrals
✔️ Step-by-step simplification
This problem looks extremely difficult at first, but careful manipulation reveals an elegant final answer.
Final Answer:
I = 2ln(2) − π/2 📐
Perfect for:
🎯 Engineering Mathematics
📚 Calculus learners
⚙️ Competitive exam preparation
🧠 STEM enthusiasts
Mathematics becomes beautiful when complex expressions simplify into elegant results.
#Calculus #Integration #Mathematics #STEM #LearnMath](https://pbs.twimg.com/media/HJXjX_BbkAAYw8A.jpg)



























