Today I'm publishing a new essay, Policy on the AI Exponential. AI is progressing extremely fast—much faster than the policy process was built to handle. The essay lays out where I think the technology is now, and the action needed to close the gap: https://t.co/Lh6PWae178
you're telling me anthropic & google are paying spacex ~$26b a year for compute?!!
this is more than half the run rate of openai & anthropic just from compute deals & that doesn't even factor in the rocket launches at all.
elon accidentally ended up owning a significant portion of three of the scarcest assets in ai.. power, chips, & physical deployment capability. the best lesson here is that if you’re selling picks & shovels during a gold rush, you don’t necessarily need to find the gold. you just need everyone else to keep digging. & also non software elon is pretty much unstoppable, like prime michael jordan type thing.
Power On: Apple, with its smart glasses launching at the end of 2027, isn’t just going after Meta. It’s aiming to disrupt the entire eyewear industry like its Apple Watch upended the mechanical watch market. https://t.co/JgFcTMkVzJ
Introducing USVC - a single basket of high-growth venture capital, for everyone.
No accreditation required, SEC-registered, and a very low $500 minimum.
Includes OpenAI, Anthropic, xAI, Sierra, Crusoe, Legora, and Vercel. As USVC adds more companies, investors will own a piece of that too.
Liquidity typically comes when companies exit, but we’re aiming to let investors redeem up to 5% of the fund every quarter. This isn’t guaranteed, but if we can make it work, you won’t be locked up like in a traditional venture fund.
It runs on AngelList, which already supports $125 billion of investor capital.
And I’ve joined USVC as the Chairman of its Investment Committee.
—
Go back to the 1500s, you set sail for the new world to find tons of gold - that was adventure capital.
Early-stage technology is the modern version. It says we are going to create something new, and it’s risky. It’s daring.
But ordinary people can’t invest until it’s old, until it’s no longer interesting, until everybody has access to it. By the time a stock IPOs, most of the alpha is gone. The adventure is gone. Public market investors are literally last in line.
This problem has become farcical in the last decade. Startups are reaching trillion dollar valuations in the private markets while ordinary investors have their noses up to the glass, wondering when they’ll be let in.
Investing in private markets isn’t easy. You need feet on the ground. You need judgment built over years. Most people don’t have the patience to wait ten or twenty years for an investment to come to fruition.
But there is no more productive, harder-working way to deploy a dollar than in true venture capital.
USVC enables you to invest in venture capital in a broad, accessible, professionally-managed way, through a single basket of innovation, focused on high-growth startups, at all stages.
It is how you bet on the future of tech: the smartest young people in the world, working insane hours, leveraged to the max, with code, hardware, capital, media, and community. Your dollar doesn’t work harder anywhere.
There is an old line - in the future, either you are telling a computer what to do, or a computer is telling you what to do. You don’t want to be on the wrong side of that transaction.
USVC lets you buy the future, but you buy it now. Then you wait, and if you are right, you get paid.
Get access here:
https://t.co/pAj1sqUsG0
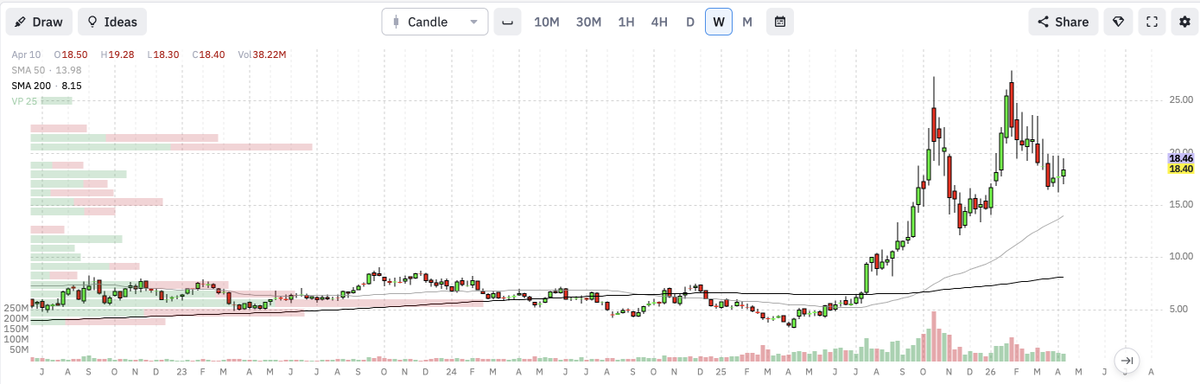
New position...adding to my core position on $UUUU. Looks ready + two pieces of interesting news dropped last week.
Here's the scoop.
Folks have short memories on here...aka moved on from solid narratives to chase other unprofitable slop. But I never stopped watching rare earths.
Ya know the theme that was all the rage 6 months ago with real $$$ deals behind it + legit tailwinds?
Well, the former pentagon chief of staff just joined the realloy (another strategic rare earth firm) as the chair of its advisory board...
Question then becomes...why would a senior defense supply chain official be joining a rare earth company.
Well, maybe the hard 2027 deadline requiring US defense systems to eliminate all chinese-sourced inputs?! See below.
"Beginning January 1, 2027, U.S. defense procurement rules will prohibit Chinese-origin rare earth materials across the entire supply chain, from mining and refining through metallization and magnet production."
Meaning they have ~8 months to partner, build, and/or scale rare earth production in the US.
This is a fixed timeline people...
Don't forget that the US gov't already has taken positions in $MP, $USAR, $CRML, and other adjacent names.
So why $UUUU?
1) asymmetric upside
> still has a potential gov't deal on the table
> unique dual-threat infrastructure play...produces both uranium for carbon-free energy + rare earths for military hardware
> one of the leading US uranium producers
> weekly chart looks insane
> relative strength amid macro noise
> solid r/r with a strong catalyst
> yahoo finance calls it "one of the three companies rebuilding america’s rare-earth arsenal"
I see $UUUU as a big part of the solution for defense contractors + tech giants needing a qualified, non-chinese source of supply.
Looking for +75% on commons in the next 6months.
Thesis invalidation (if these happen, I exit):
- weekly candle close under $16.50
- jan 1st '27 catalyst / deadline gets moved or canceled
$UUUU is currently $18.40.
Same, I have a similar setup. A mix of Obsidian, Cursor (for md), and vibe-coded web terminals as front-end.
Since I do a podcast, the number/diversity of research interests is very large. But the knowledge-base approach has been working great.
For answers, I often have it generate dynamic html (with js) that allows me to sort/filter data and to tinker with visualizations interactively.
Another useful thing is I have the system generate a temporary focused mini-knowledge-base for a particular topic that I then load into an LLM for voice-mode interaction on a long 7-10 mile run. So it becomes an interactive podcast while I run, where I ask it questions and listen to the answers to learn more.
Anyway, heading out for a run now, thanks for the write-up 👊
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
We're shipping a new feature in Claude Cowork as a research preview that I'm excited about: Dispatch!
One persistent conversation with Claude that runs on your computer. Message it from your phone. Come back to finished work.
To try it out, download Claude Desktop, then pair your phone.