🇬🇧/ From now on, in this account I will only share technical content on math, AI, science, and applications in fields like entrepreneurship, startups, and finance.
I'll create a separate personal account to keep opinions apart.
Jane Street AI Engineer revealed how they trained their own LLM for trading to make $22.5B/year
16 minutes. free. straight from tier-1 quants.
bookmark & watch - this is the most honest "AI inside a hedge fund" talk ever published.
forget the "AI trading bot" YouTube grifters. This is the real inside view: data, training, evals, integration.
then start building your own bot using post below.
It is dangerously easy to build a neural network today without actually understanding how it works.
We live in an era of 'import torch'. You can train a model in three lines of code, but the moment you need to debug a collapsing loss function or a vanishing gradient, syntax won't save you. You need first principles.
I recently went through this notebook collection by Simon J.D. Prince, and it is the antidote to tutorial hell.
Instead of just showing you the code, it forces you to visualize the mechanics:
1./ The Math => It builds the intuition for shallow networks and regions before adding complexity.
2./ The Optimization => It doesn't just use an optimizer; it compares Line Search, SGD, and Adam so you see why they behave differently.
3./ The Modern Stack => It connects the dots from basic backpropagation all the way to Self-Attention and Graph Neural Networks.
Move from running code to engineering systems => this is a goldmine.
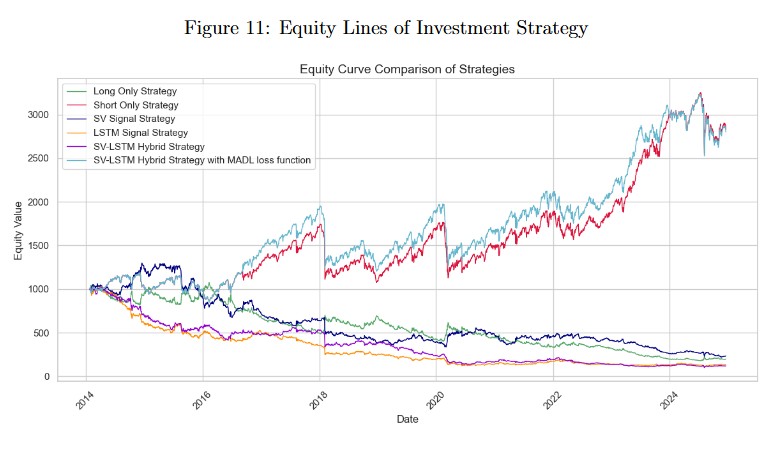
"Stochastic Volatility Modelling with LSTM Networks": "The Stochastic Volatility model contributes statistical precision... latent volatility dynamics... in response to unforeseen events, while the LSTM network... detects complex, nonlinear patterns in financial time series." https://t.co/K2of3kJIRU
According to Ray Dalio, the easiest way to adjust for risk is to seek uncorrelated returns.
Ray's made billions from a simple idea.
Here's how to do it in a few lines of Python code:
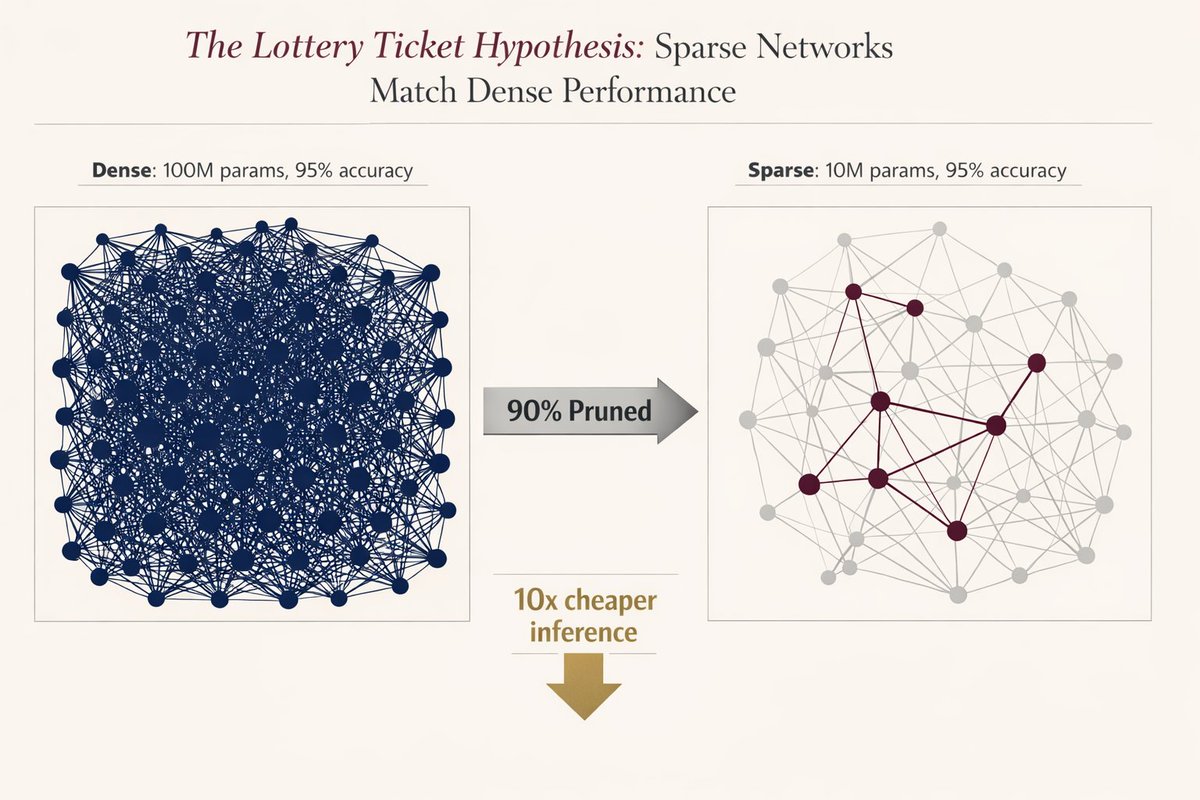
🚨 MIT proved you can delete 90% of a neural network without losing accuracy.
Five years later, nobody implements it.
"The Lottery Ticket Hypothesis" just went from academic curiosity to production necessity, and it's about to 10x your inference costs.
Here's what changed (and why this matters now):
Information geometry for deep learning:
neuromanifold of stochastic NNs, Fisher-Rao norm, natural gradient, singularities.
Relative Fisher information (RFIM) and relative natural gradient for tackling large NNs (ICML):
https://t.co/lkStzvHdpT
2/ Sapient Intelligence is a Singapore-based AI research startup focused on creating brain-inspired reasoning systems. They recently dropped HRM - a brain-inspired AI model that doesn’t think in tokens.
HRM (Hierarchical Reasoning Model) uses multi-timescale recurrence - a structure inspired by how humans reason, not how language models complete sentences.
One loop handles fast decisions. Another refines ideas over time. Together, they think, not just complete.
Flow Matching (FM) is one of the hottest ideas in generative AI - and it’s everywhere at #ICML2025.
But what is it? And why is it so elegant? 🤔
This thread is an animated, intuitive intro into (Variational) Flow Matching - no dense math required.
Let's dive in! 🧵👇
We present Panda: a foundation model for nonlinear dynamics pretrained on 20,000 chaotic ODE discovered via evolutionary search. Panda zero-shot forecasts unseen ODE best-in-class, and can forecast PDE despite having never seen them during training (1/8)
https://t.co/AuWFmVal8o
people say GNNs are turning obsolete, but one thing I noticed in my experiments:
attention is not so good at picking up local fine-grained details and you need GNNs to do the job!
This is because GNNs are a lot more expressive when it comes to pairwise interactions.
1/n
@francoisfleuret I’d say, in no particular order:
1 - FlashAttention, mostly because you can avoid materialising the weights matrix.
2 - MoE - scaling laws indicate it’s always more convenient to have it.
3 - Ring Attention + RoPE - long context
4 - GQA - reduce KV cache size
New version on https://t.co/ZAEbHWNSm8. Couldn't have done it without help from my student Amanjit who joined as a co-author. Includes new implementations with neural OT. Figure shows our primal and dual displacement interpolations w.r.t. "transport KL-geometry" on the simplex.
@PetarV_93@omarsar0@fedzbar Tired: all the Studio Ghibli-like generations 📉
Wired: the "Petar mode" in AI Studio to generate beautiful TikZ figures from scribbles 📈
We knew very little about how LLMs actually work...until now.
@AnthropicAI just dropped the most insane research paper, detailing some of the ways AI "thinks."
And it's completely different than we thought.
Here are their wild findings: 🧵