With Cape's #AI powered Knowledge Retrieval capabilities, connect and #search across all of your hashtag#enterprise datasources with your choice of hosted, or on-premise #LLMs. 🧠 🔥
Schedule a demo to learn more at https://t.co/B4I4Y0dRt3 🗓
We are #hiring! If you are an experienced technical engineer looking for a challenging role, working with a great #team and the latest #ai technologies, please take a look at our open positions! https://t.co/fIvrQx1PI9
With Cape's #AI Workflows and Knowledge Retrieval capabilities, your #compliance and #riskmanagement teams can significantly reduce their manually intensive reporting processes (including #KYC, #CDD, #EDD, #SOC). Integration to all of your data sources, privately and securely!
New product, new website, new video! 🎉
Excited to announce the evolution of Cape Privacy with the launch of Cape Enterprise. 🚀
Build #AI-powered #workflows with your choice of #LLM, together with all of your #data, privately and securely. 💰
https://t.co/wJSA044xES
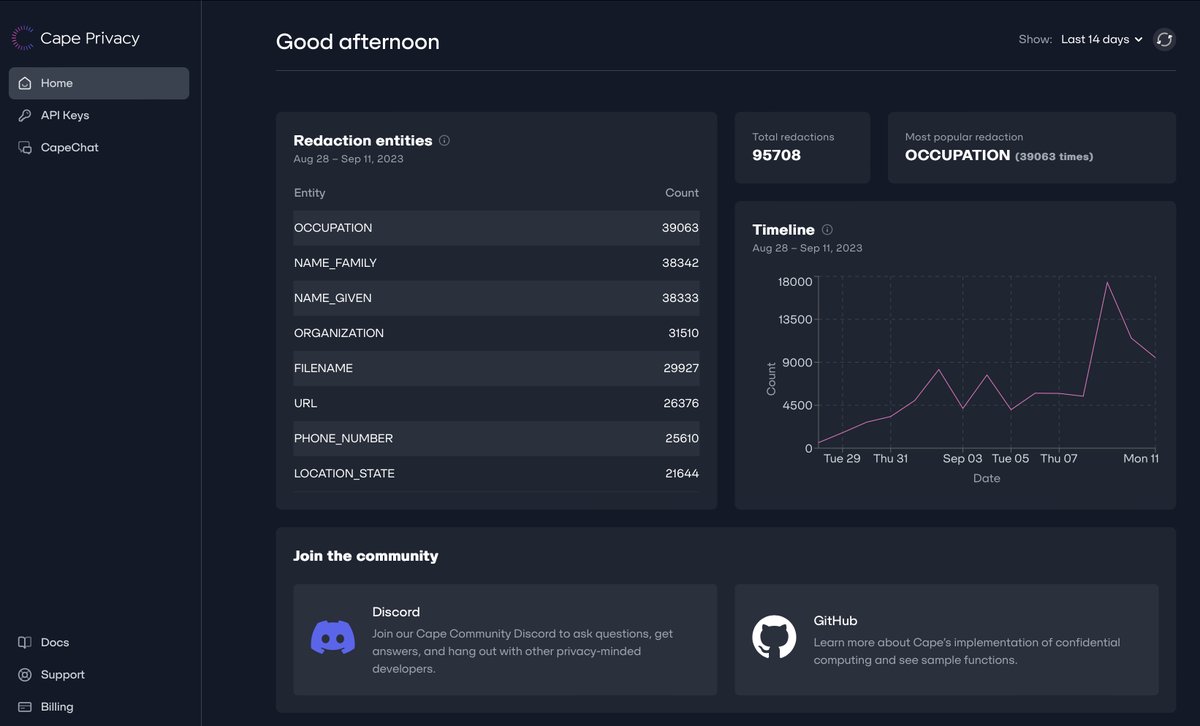
Cape Privacy Analytics gives users important insights as to what sensitive data is being used with multiple #LLMs including #GPT, #Claude, #Cohere and #Llama2. Try it for yourself at https://t.co/MtyhoT1ibH
Nobody can compete with OpenAI.
If you want to integrate a Large Language Model with your application, OpenAI wins every day.
But the problem is that companies can't justify using OpenAI's API with their customer's private information.
Here is a solution:
The @capeprivacy team shared with me their new API. They redact private information from your content, so you don't have to worry about it.
There are two ways you can use the API:
First, you can de-identify your content. De-identification removes any Personally Identifiable Information from the input. You can use the redacted content with OpenAI's API or any other model.
Second, you can use their Completions API, which handles de-identification and re-identification. It removes sensitive information, sends the redacted query to OpenAI, and re-identifies the content.
The attached image shows how simple it is to use the API.
If you are working with any sensitive information, this is a must.
By the way, @capeprivacy tells me they detect and redact 50 types of sensitive entities, like emails, names, credit cards, and addresses. They use secure enclaves to do this so they can’t see any of the information.
Here is a link to their documentation: https://t.co/AfGwEFUX3e
Thanks to @capeprivacy for sponsoring this post.
We're excited to announce new features to the Cape API including support for multiple LLMs, secure vision and voice models, privacy analytics to monitor and measure confidential data. Learn more at https://t.co/wJSA044xES
#openai#anthropic#meta#azure#cohere#llms
Looking to use an LLM but concerned about the sensitivity of your data?
The Cape API keeps your data private while using the LLM of your choice.
Here's how you can get started:
Cape Privacy is excited to announce availability of @Anthropic's Claude 2 (released earlier today) via CapeChat (https://t.co/y1v79qqoPh) and the Cape API.
#ai, #llm, #dataprivacy, #datasecurity, #trustedai, #api
https://t.co/bVWPKRI9LO
CapeChat now defaults to GPT-4 for all users! ✅
We also support GPT-3.5 Turbo 16k.
💸 GPT-4 is 30X more expensive than GPT-3.5, but we made this choice because we want users to have the best experience possible. First impressions are everything! 💯
https://t.co/4jVIFbLHhV
::Introducing the Cape API::
Keep sensitive data private while prompting LLMs like GPT-4 and GPT 3.5 Turbo.
Easily de-identify sensitive data like financial, legal, and internal docs before sending to @OpenAI
Try the playground free:
https://t.co/s5eF5FfIQP
How? /🧵
The Cape team will be at #awssummit2023 Toronto booth 126!
CapeChat runs on AWS #NitroEnclaves, securely combining:
- PII Identification & Redaction
- Encrypted Vector Storage & Search
- LLM Framework (Langchain)
- LLM Support (GPT-3.5-turbo and GPT-4)
https://t.co/7kJ3HZF1Fx
At @capeprivacy, we help companies protect their sensitive data so it can be used in AI pipelines. Here’s a short demo of how you can use Cape with a @huggingface model to secure both the model and the input data. And if you’re at #PyConUS2023 this week, come see us at booth 411!
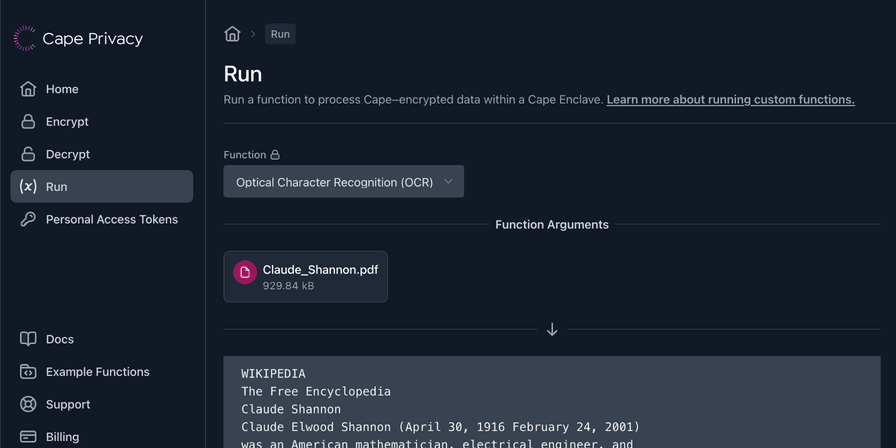
Cape has recently deployed a confidential optical character recognition (OCR) service, which anyone can now use! For its OCR service, Cape uses the excellent Python docTR library.
Read more here: https://t.co/WGizR7CIeP
#OCRservices#dataprivacy#machinelearning
This talk by Justin Patriquin will share how engineers can deploy functions containing proprietary algorithms, models, and secrets while keeping your intellectual property confidential.
Join us @conf42com! https://t.co/7Tu2dcge0T