Reinforcement learning has exploded on Modal, and we've been cooking.
Here's a review of lessons learned helping teams train at scale, the patterns we kept seeing, and an open-source library to get started with RL on Modal quickly.
At @modal, we're working to make sure OSS RL frameworks have all the techniques necessary to train frontier open-weights models.
Delta compression is key, but the job's not done. There are still lots of open problems around weight sync, auto-scaling, & cross-cluster training.
My DMs are open!
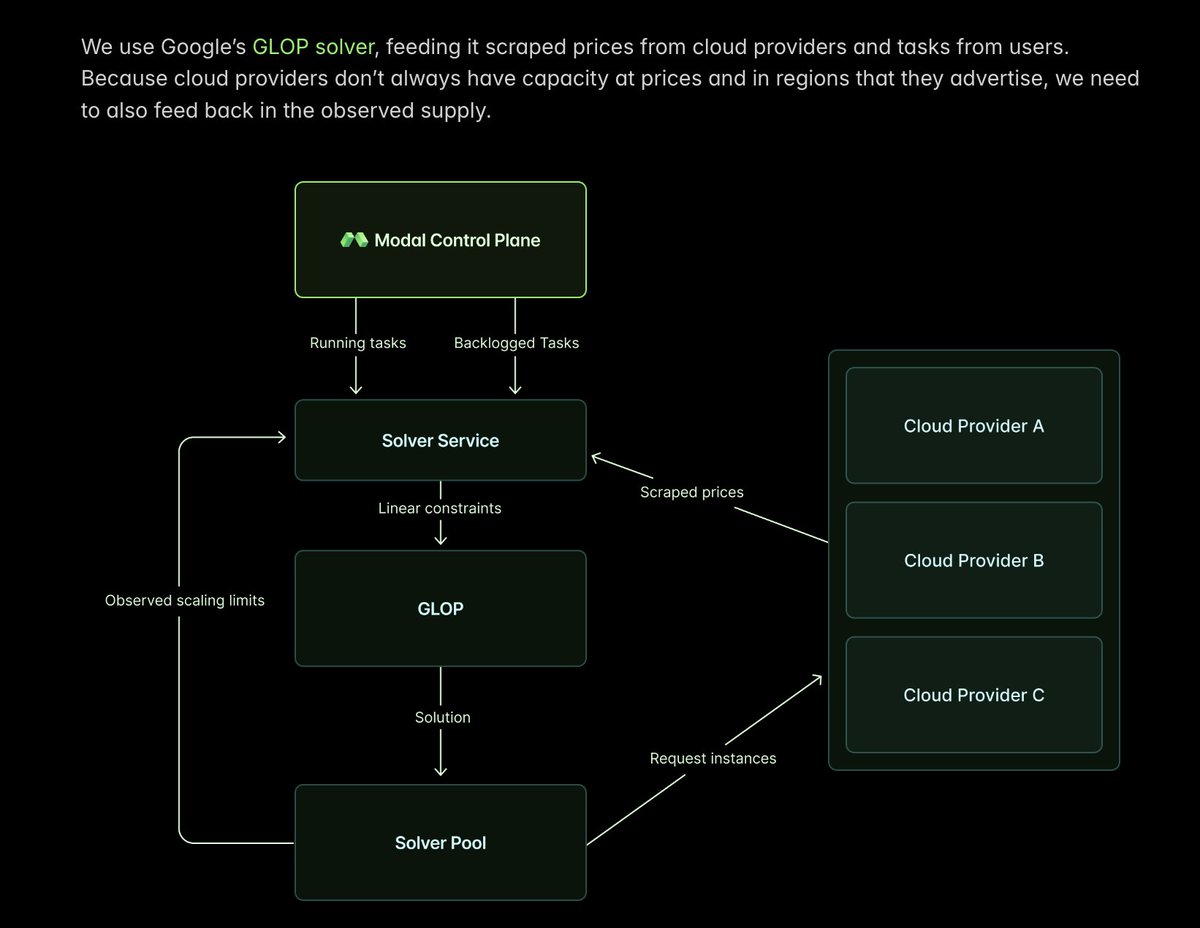
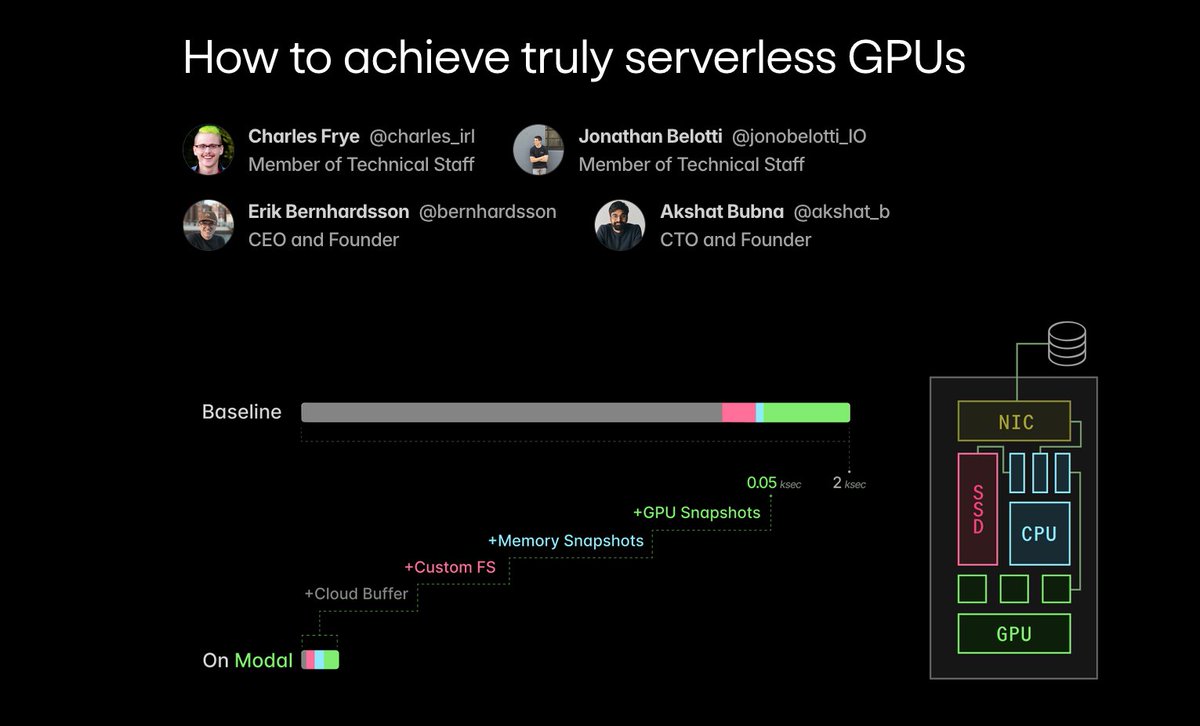
Added a smol new section to last week's blog post on the technical internals of @modal's fast cold boots.
This section describes how we frame cloud buffer management as a linear optimization problem and solve it with GLOP.
https://t.co/DQ4wvuXjre
Inference isn't everything, but it does require a new stack -- not Kubernetes, not SLURM.
At @modal, we dove deep to build that stack.
In this blog post we explain how, from compute management & cloud-native cacheing to CRIU & GPU checkpointing.
https://t.co/DQ4wvuXjre
1. this is usually handleable with the right admonition in SKILL.md or AGENTS.md. here* is one public example, which points to an agent-modal-training.md** that assists in managing the lifecycle of training runs
1b. depending on the RL framework, `modal deploy` can actually be more idiomatic. here's*** an example that should work with any Ray-based RL framework. each training run becomes a `modal.method()` call, which is easy to fan out with `.spawn_map()`
1c. the nice thing about this strategy is that you can cancel a function call without losing the container, so as long as your experiment configs/hparam configs don't require a redeploy, you can interactively run experiments without having to wait for a container to be re-scheduled
2. how is this implemented? if you write this as a function and `.spawn_map(exp_config_iter)`, we will scale up all the workers in parallel, even if we don't have them in our buffer!
* https://t.co/LHNE6sGZ0C
** https://t.co/rvmeMPgHwU
*** https://t.co/7YK5B481eQ
@charles_irl@JulienBlanchon@skypilot_org@modal I’m hoping this release doesn’t add too much at the k8s layer. the core of monarch seemed extremely well suited to run on Modal last I checked
it should just work ™️ when running over RDMA in our @clustered functions