Excited to introduce SOLE-R1, a video-language reasoning model for zero-shot reward prediction for robot manipulation tasks!
SOLE-R1 reasoning can serve as the SOLE signal for learning new tasks (completely from scratch) through online RL - i.e., robots start with random actions and learn previously unseen tasks guided only by SOLE-R1 rewards, without any demonstrations, ground-truth rewards, success indicators, or task-specific tuning.
SOLE-R1 significantly outperforms strong baselines (e.g., Robometer, RoboReward, TOPReward, GPT-5, Gemini-3-Pro) in zero-shot online RL when evaluated across 40 tasks - including a real-world tabletop manipulation setting and 4 sim environments (LIBERO, ManiSkill, Meta-World, RoboSuite).
We open source all models, training data, and code.
Website, demos, and paper at: https://t.co/WCSX8gQl3e
🧵 (1/6)
We found that state-of-the-art VLMs (Gemini, GPT-5, etc.) fail at predicting task progress for online RL, so we built our own: SOLE-R1.
SOLE-R1 is trained on 10 million images and video frames, and 4 million chain of thought traces that reason over both space and time.
The result is a video-language reasoning model that can be used as a reward for online RL with no other reward signals!
The bottleneck to on-robot reinforcement learning is good, scalable reward prediction. Robometer is a massive step in that direction, and the authors have been wonderfully open as well, releasing a large dataset and continuing to improve their model post release.
Thanks to @aliangdw@yigitkkorkmaz and @Jesse_Y_Zhang for joining me and @DJiafei!
We're presenting PEEK at ICRA in Vienna this week 🏰
Stop by at the 9-10:30am poster session on June 3 to say hi and check out some cool VLA generalization 🤖
@yigitkkorkmaz@adcock_brett very cool! @yigitkkorkmaz - if interested, check out our new reward model (SOLE-R1) for online RL
just announced it on X here: https://t.co/iuDAciaqDC
Excited to introduce SOLE-R1, a video-language reasoning model for zero-shot reward prediction for robot manipulation tasks!
SOLE-R1 reasoning can serve as the SOLE signal for learning new tasks (completely from scratch) through online RL - i.e., robots start with random actions and learn previously unseen tasks guided only by SOLE-R1 rewards, without any demonstrations, ground-truth rewards, success indicators, or task-specific tuning.
SOLE-R1 significantly outperforms strong baselines (e.g., Robometer, RoboReward, TOPReward, GPT-5, Gemini-3-Pro) in zero-shot online RL when evaluated across 40 tasks - including a real-world tabletop manipulation setting and 4 sim environments (LIBERO, ManiSkill, Meta-World, RoboSuite).
We open source all models, training data, and code.
Website, demos, and paper at: https://t.co/WCSX8gQl3e
🧵 (1/6)
@_abraranwar@memmelma hi @_abraranwar we agree! just released a new zero-shot reward model that is faster and seems better than baselines (e.g., Robometer, TOPReward, RoboReward) for online RL starting from randomly initialized policies!
just announced it on X here: https://t.co/iuDAciaqDC
Excited to introduce SOLE-R1, a video-language reasoning model for zero-shot reward prediction for robot manipulation tasks!
SOLE-R1 reasoning can serve as the SOLE signal for learning new tasks (completely from scratch) through online RL - i.e., robots start with random actions and learn previously unseen tasks guided only by SOLE-R1 rewards, without any demonstrations, ground-truth rewards, success indicators, or task-specific tuning.
SOLE-R1 significantly outperforms strong baselines (e.g., Robometer, RoboReward, TOPReward, GPT-5, Gemini-3-Pro) in zero-shot online RL when evaluated across 40 tasks - including a real-world tabletop manipulation setting and 4 sim environments (LIBERO, ManiSkill, Meta-World, RoboSuite).
We open source all models, training data, and code.
Website, demos, and paper at: https://t.co/WCSX8gQl3e
🧵 (1/6)
@JeremySMorgan3@Jesse_Y_Zhang hi @JeremySMorgan3, we just released a new zero-shot reward model that performs well with online RL in ManiSkill - if interested, check it out here: https://t.co/iuDAciaqDC
Excited to introduce SOLE-R1, a video-language reasoning model for zero-shot reward prediction for robot manipulation tasks!
SOLE-R1 reasoning can serve as the SOLE signal for learning new tasks (completely from scratch) through online RL - i.e., robots start with random actions and learn previously unseen tasks guided only by SOLE-R1 rewards, without any demonstrations, ground-truth rewards, success indicators, or task-specific tuning.
SOLE-R1 significantly outperforms strong baselines (e.g., Robometer, RoboReward, TOPReward, GPT-5, Gemini-3-Pro) in zero-shot online RL when evaluated across 40 tasks - including a real-world tabletop manipulation setting and 4 sim environments (LIBERO, ManiSkill, Meta-World, RoboSuite).
We open source all models, training data, and code.
Website, demos, and paper at: https://t.co/WCSX8gQl3e
🧵 (1/6)
(6/6)
🌐 Website: https://t.co/WCSX8gQl3e
📄 Paper: https://t.co/KAg9IUwKVt
👩🏻💻 Code: https://t.co/97X9Ad4vPO
Thank you to my co-authors: @thomas_weng, Karl Schmeckpeper, @_ericrosen, Stephen Hart
And special thanks to @BizaOndrej for supervising this work from the very start!
More to come soon!
Excited to introduce SOLE-R1, a video-language reasoning model for zero-shot reward prediction for robot manipulation tasks!
SOLE-R1 reasoning can serve as the SOLE signal for learning new tasks (completely from scratch) through online RL - i.e., robots start with random actions and learn previously unseen tasks guided only by SOLE-R1 rewards, without any demonstrations, ground-truth rewards, success indicators, or task-specific tuning.
SOLE-R1 significantly outperforms strong baselines (e.g., Robometer, RoboReward, TOPReward, GPT-5, Gemini-3-Pro) in zero-shot online RL when evaluated across 40 tasks - including a real-world tabletop manipulation setting and 4 sim environments (LIBERO, ManiSkill, Meta-World, RoboSuite).
We open source all models, training data, and code.
Website, demos, and paper at: https://t.co/WCSX8gQl3e
🧵 (1/6)
(5/6)
Evaluation setting:
We evaluate whether SOLE-R1 can serve as the SOLE supervision signal for learning manipulation skills from scratch via online RL. We run experiments across 4 sim benchmark suites (LIBERO, ManiSkill, Meta-World, and RoboSuite) and in a real-world tabletop manipulation setting with a Franka arm. Across all settings, we evaluate a total of 40 tasks, spanning pick-and-place, articulation, button/lever/knob interactions, and mobile manipulation.
Results:
SOLE-R1 achieves ≥50% success rate on 24 tasks, substantially outperforming all baselines. The strongest baselines include GPT-5 and Gemini, but they reach 50% success on only 7 and 5 tasks, respectively. The non-reasoning models achieve near-zero success on all tasks, with the exception of Meta-World tasks, where Robometer, RoboReward, and ReWiND achieve above 40% success rate on 4 tasks.
Introducing EXPO-FT – Efficient, Reliable & Open-Source VLA Finetuning!
EXPO-FT unlocks π0.5 for challenging manipulation tasks:
Routing string lights & inserting the power connector to illuminate them
Striking pool ball into pocket
Inserting flower into wine bottle
(1/5)
TOPReward is now in LeRobot!
Its an elegant solution using the model's own logit probabilities, and worked very well when I compared it to other VLA rewards (vid below, the red line)
How to use in LeRobot: https://t.co/qjJQfS1whg
Congrats @DJiafei@allen_ai@UW!
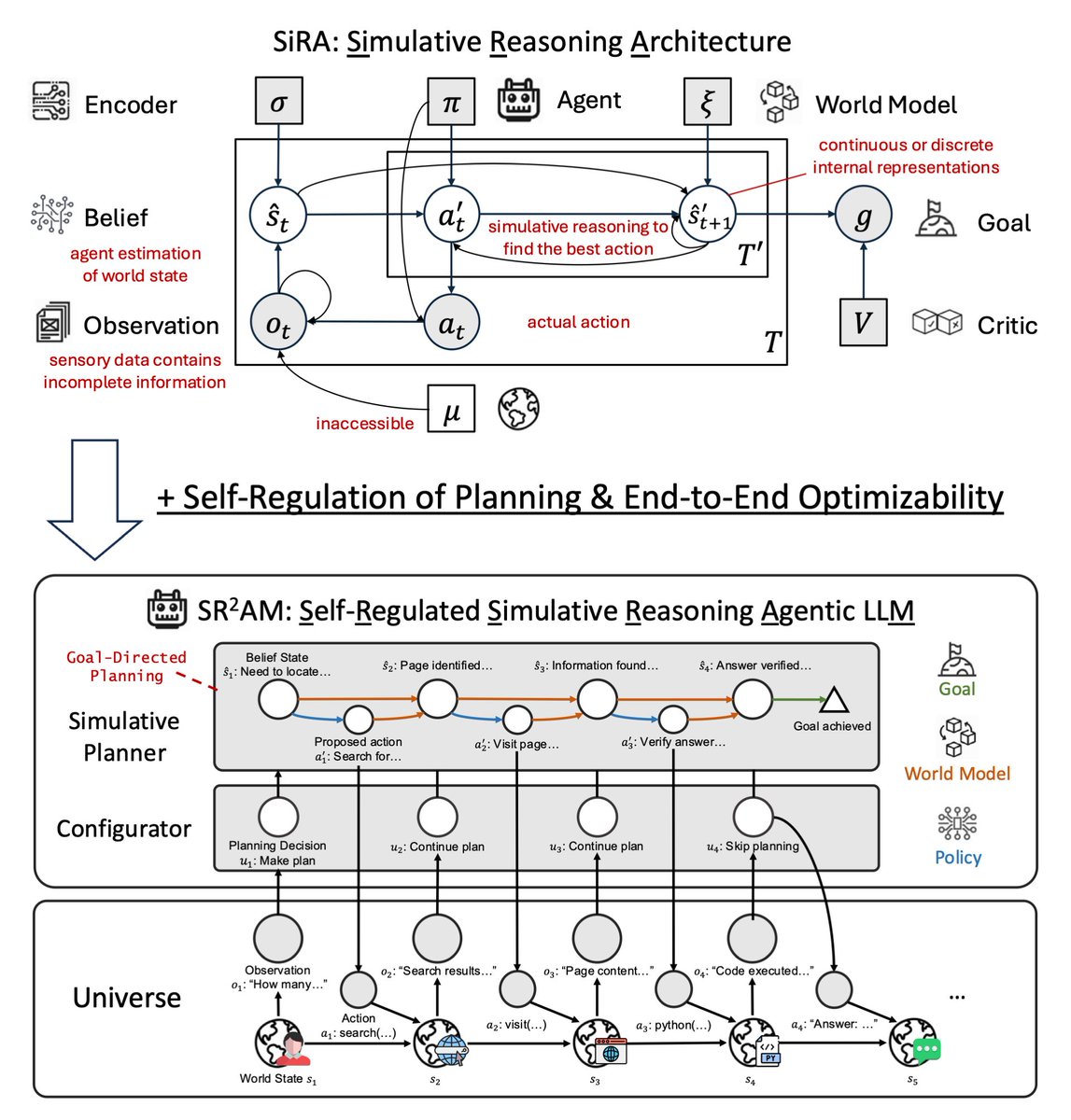
Frontier LLMs are converging on efficient, adaptive reasoning. Opus 4.7 lets the model decide how deeply to reason. GPT-5.5 achieves strong results with fewer reasoning tokens.
We study a related but more structural question: what 𝗸𝗶𝗻𝗱 𝗼𝗳 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 should we adapt?
Last year in SiRA (upper figure), we showed that simulative reasoning (System II), which uses a 𝘄𝗼𝗿𝗹𝗱 𝗺𝗼𝗱𝗲𝗹 to evaluate consequences of actions, yields up to 124% improvement over reactive baselines (System I), and that strong reasoning models (o1, o3-mini) fail as planners without this structure.
In our new paper SR²AM (lower figure), we add a learned 𝗰𝗼𝗻𝗳𝗶𝗴𝘂𝗿𝗮𝘁𝗼𝗿 (System III) that self-regulates when to simulate, how far ahead, and when to skip planning entirely.
Efficient reasoning is not just shorter reasoning: it is better allocation of simulation.
1/ New from @ScaleAILabs: Rubrics (a.k.a. checklists) have become the default reward interface for RL on open-ended tasks without final verifiable answers.
But most rubric RL still relies on static aggregation: fixed human weights over criteria, summed into one scalar reward.
We show that this conflates what should matter in the final answer with what can actually teach the current policy.
https://t.co/H5wTQ27ulb
MolmoAct2 kinda just works out of the box in an unseen environment and with unseen objects.
I find it really crazy that I can just download a model from the internet and plug it into my robot and it can do some tasks at a limited capacity right away.
this video is at 2x speed