Frontier LLMs are converging on efficient, adaptive reasoning. Opus 4.7 lets the model decide how deeply to reason. GPT-5.5 achieves strong results with fewer reasoning tokens.
We study a related but more structural question: what 𝗸𝗶𝗻𝗱 𝗼𝗳 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 should we adapt?
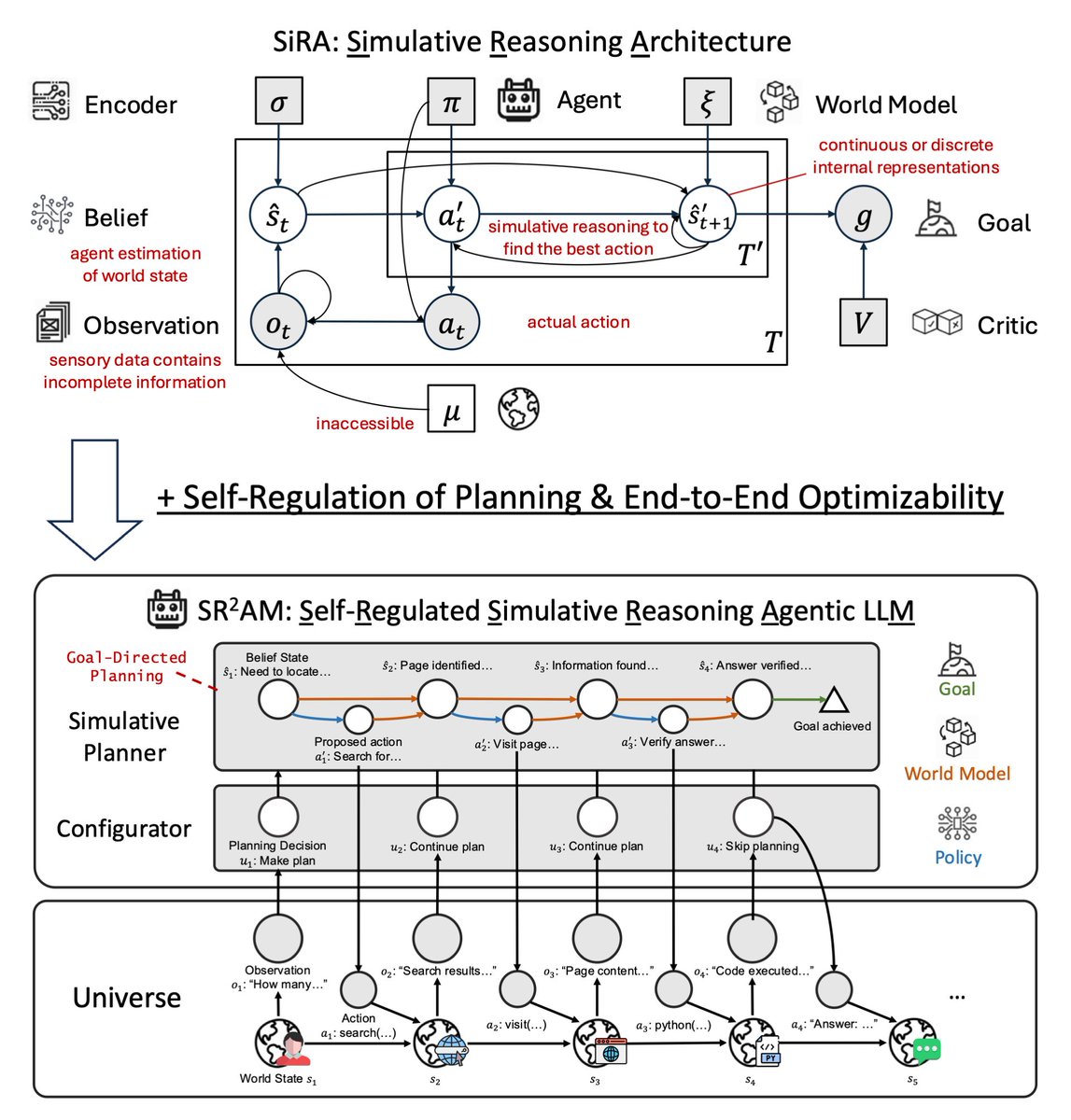
Last year in SiRA (upper figure), we showed that simulative reasoning (System II), which uses a 𝘄𝗼𝗿𝗹𝗱 𝗺𝗼𝗱𝗲𝗹 to evaluate consequences of actions, yields up to 124% improvement over reactive baselines (System I), and that strong reasoning models (o1, o3-mini) fail as planners without this structure.
In our new paper SR²AM (lower figure), we add a learned 𝗰𝗼𝗻𝗳𝗶𝗴𝘂𝗿𝗮𝘁𝗼𝗿 (System III) that self-regulates when to simulate, how far ahead, and when to skip planning entirely.
Efficient reasoning is not just shorter reasoning: it is better allocation of simulation.
@BetaTomorrow@drfeifei Thank you for the summary and interpretation. We agree that there are many intricacies in the mathematical foundation of world models
Thanks for your reply. I agree that the short-term solution is not necessarily at odds with the long-term solution. For example, the program-simulator can be a helpful resource for training the model-simulator.
In these days, however, the long-term solution might happen faster than expected.
#PAN-v1 has already been released by @IFM_MBZUAI last year, and v2 is hot in the works!
Yesterday, @NVIDIAAI has also released the wonderful #Cosmos3
Website: https://t.co/xIrYuRXjgm
Tech Report: https://t.co/K1hIXwTJcO
We agree that the world model should be a simulator that supports decision-making, not rendering beautiful images/videos.
Our difference is in how the world state should be represented.
Should the world be anchored in Gaussian splats and physics engines for program-as-simulator? Or in learned representations for model-as-simulator?
We believe the latter is a more scalable, bitter-lesson-pilled approach.
More in our position paper "Critiques of World Models" coauthored with Prof. @ericxing and @jinyuhou0
https://t.co/NqnxGtKNBL
1/4
Frontier LLMs are converging on adaptive reasoning.
But controlling how much to think is not the same as controlling what kind of thinking to do.
SR²AM introduces self-regulated simulative reasoning: an agent that simulates possible futures through a world model and learns when that simulation is worth the cost.
🧵 Claude-Opus-4.8 takes you too much tokens - but is this issue general across agents? Do agents know how much they'll spend?
Introducing Budget-Aware Agents (BAGEN): We study budget awareness across 4 envs & 5 frontier agents, and find structured failures in most of them.
👇
Interesting analysis. This reminds me of the classical aphorism: “all models are wrong. Some are useful.”
The utility of a world model is perhaps not in simulating everything perfectly down to the atom, but in simulating the scenarios that matter well enough to provide useful reasoning and learning guidance to an agent.
It is ultimately up to an agent to decide when and how much to trust the world model
Thank you for your interest. No plans as of yet -- we are focused on studying the problem of self-regulation rather than full model coverage.
That being said, the verbosity issue is exactly what the configurator is designed to address: learning when deliberation is worth the cost, not just defaulting to more or less reasoning.
The approach is model-agnostic, so in principle, the results will also apply
Frontier LLMs are converging on efficient, adaptive reasoning. Opus 4.7 lets the model decide how deeply to reason. GPT-5.5 achieves strong results with fewer reasoning tokens.
We study a related but more structural question: what 𝗸𝗶𝗻𝗱 𝗼𝗳 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 should we adapt?
Last year in SiRA (upper figure), we showed that simulative reasoning (System II), which uses a 𝘄𝗼𝗿𝗹𝗱 𝗺𝗼𝗱𝗲𝗹 to evaluate consequences of actions, yields up to 124% improvement over reactive baselines (System I), and that strong reasoning models (o1, o3-mini) fail as planners without this structure.
In our new paper SR²AM (lower figure), we add a learned 𝗰𝗼𝗻𝗳𝗶𝗴𝘂𝗿𝗮𝘁𝗼𝗿 (System III) that self-regulates when to simulate, how far ahead, and when to skip planning entirely.
Efficient reasoning is not just shorter reasoning: it is better allocation of simulation.
We agree with LeCun that world model is the way to AGI/ASI.
However, we have different ideas on how WMs should be built and used:
1. LLMs are not doomed; it’s one instance of a world model in language space
2. Generative modeling is great; it provides powerful supervision with minimal assumptions — more bitter lesson pilled
3. MPC is not all you need for agents; you need to self-regulate planning (itself an action for WM), use WM for learning policies, and more
More details in our paper “Critiques of World Models”: https://t.co/NqnxGtKNBL
We agree with LeCun that world model is the way to AGI/ASI.
However, we have different ideas on how WMs should be built and used:
1. LLMs are not doomed; it’s one instance of a world model in language space
2. Generative modeling is great; it provides powerful supervision with minimal assumptions — more bitter lesson pilled
3. MPC is not all you need for agents; you need to self-regulate planning (itself an action for WM), use WM for learning policies, and more
More details in our paper “Critiques of World Models”: https://t.co/NqnxGtKNBL
SR²AM is out!
Thinking longer ≠ thinking smarter. SR²AM knows which one it needs.
A configurator regulates internal simulation: when to predict future states, how far, and when to skip.
Result: 30B competing with 685B–1T at a fraction of the token cost.
Model and code available
New work led by the inimitable @mdeng34 and @jinyuhou0.
We took a fair bit of time thinking about whether an agent can assess how much effort it needs to spend on thinking through the problems it is presented. The resulting algorithm is one step to a fully adaptive future!
LLM training is built on fast MatMuls. But many surrounding ops still run as memory-bound kernels.
CODA reparameterizes them to hide in the matmul’s shadow, fused into its epilogue before results leave the chip.
Bonus: LLMs can write fast CODA kernels too (approaching SoLs).
On popular benchmarks, our 30B model matches systems 20-30x its size (gpt-5.4-xhigh, DeepSeek-V3.2, Kimi-K2.5), while using up to 95% fewer reasoning tokens than comparable 30/32B agentic LLMs.
The trick: don't just reason less, reason about the right things. A learned configurator decides when to simulate, how far ahead, and when to skip planning entirely.
Efficient reasoning is an allocation problem, not a compression problem.
Model and code are openly available.
This is a prototype using language-based world models. Stay tuned for our next steps on multimodal and physical world models.
The concept of a configurator, which decides when and how deeply to engage a reasoning process, is not specific to planning, but extensible to learning and adaptation going forward.
📄 SR²AM: https://t.co/LKeXZFN8Hh
📄 SiRA: https://t.co/5JzLSEu4nO
🌐 Project: https://t.co/1CUlEdFMxY
💻 Code: https://t.co/JSBoERYHaB
🤗 SR²AM-v0.1-8B: https://t.co/b1kkuvFL6k
🤗 SR²AM-v1.0-30B: https://t.co/PES00q6a4J
Joint work with @jinyuhou0, @larasnevess, @varad0309, @tw_killian, @waterluffy, @ericxing
How does self-regulated simulative reasoning perform in practice?
SR²AM-v0.1-8B achieves results competitive with GPT-OSS (120B) and GLM-4.6 (355B).
SR²AM-v1.0-30B is competitive with DeepSeek-V3.2 (685B) and Kimi-K2.5 (1T) at 𝟮𝟲–𝟵𝟱% fewer reasoning tokens than comparable 30/32B agentic LLMs.
The key finding from RL training: the model learns to plan further ahead (+22.8% horizon) rather than more often (+2% frequency). Allocation, not compression.