📣 There's never a "best" time to share important updates, especially after sitting on this for so long...
I'm joining the faculty @BYU + @BYUCS this Summer as an Assistant Professor in preparation for the upcoming school year. Lots of excitement and a fair bit of nerves. 🧵
2/4
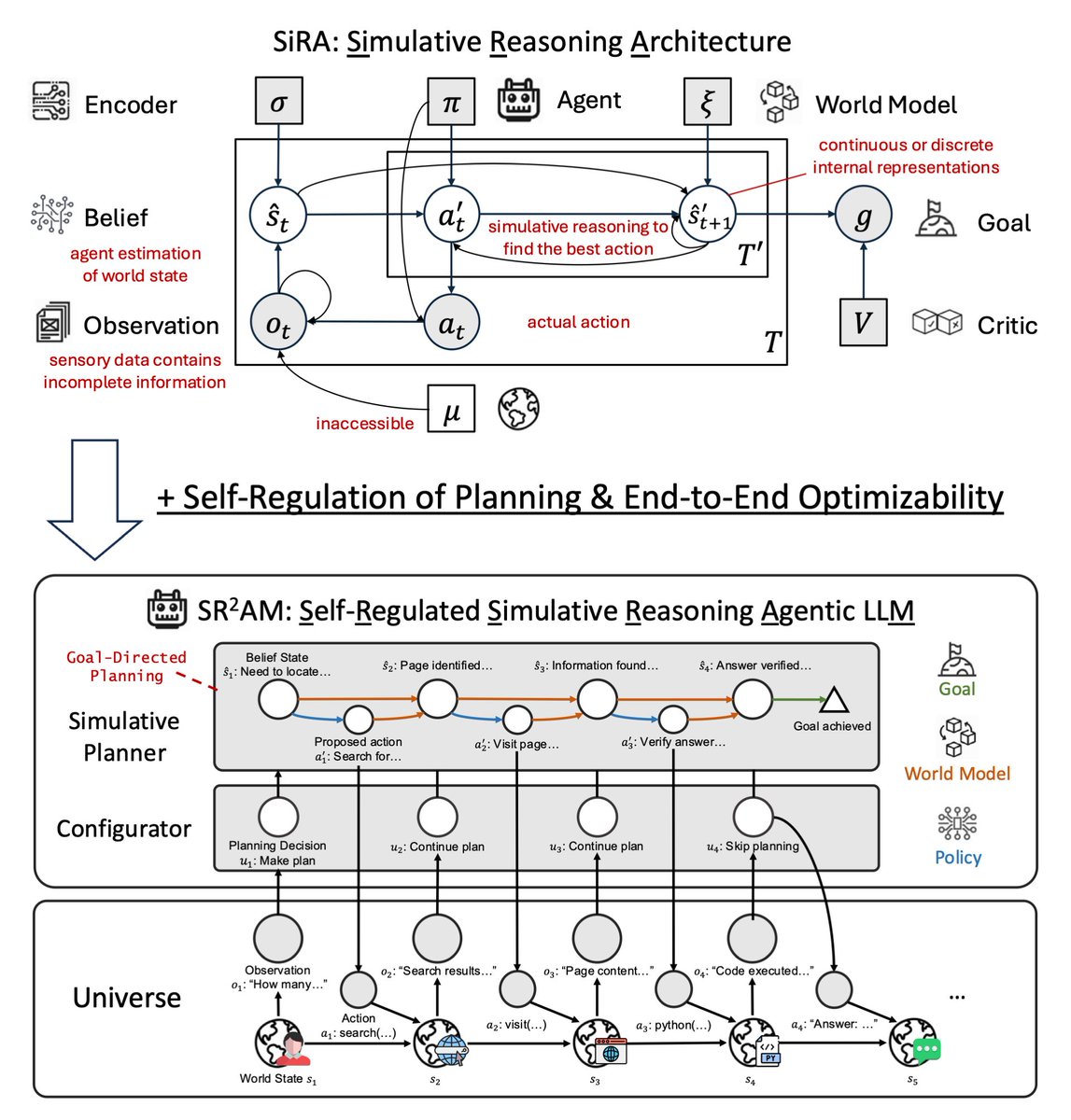
The system decomposes deliberation into three processes: reactive execution (System I), future-state simulation via LLM-as-world-model (System II), and a learned configurator (System III) that decides when to simulate, how far ahead, and when to act directly.
RL trains the configurator to plan further ahead, not more often. Allocation, not compression.
@ziv_ravid Hey Ravid, his skill set seems to map really cleanly to some of the problems we're working on and constructing solutions for @LilaSciences. Can you connect us?
cc: @BenKompa + @AndrewLBeam
Two BIG updates for the RLBrew Workshop at #RLC2026! 📣
1️⃣ Dual submissions are welcome
2️⃣ We’ll be awarding a Best Paper RLBrew Award 🏆
You have 2 DAYS LEFT to submit — deadline: May 29!
Details: https://t.co/segLTne6Tp
Tbh i’m kinda sick of this academic doomerism vibe consuming all of bay area and the self-aggrandizing pov that frontier labs have. Sure a lot of exciting stuff is happening but we wouldn’t be where we are wo academia & there is sth to be said about the pursuit of curiosity.
My friends… get ready for mountain pictures at a higher frequency… I really don’t ever want to take them for granted.
Spent a few days getting some things set up in Provo and couldn’t leave before scampering up “Khyv” Peak (that new name is going to take some getting used to)
📣 There's never a "best" time to share important updates, especially after sitting on this for so long...
I'm joining the faculty @BYU + @BYUCS this Summer as an Assistant Professor in preparation for the upcoming school year. Lots of excitement and a fair bit of nerves. 🧵
SR²AM is out!
Thinking longer ≠ thinking smarter. SR²AM knows which one it needs.
A configurator regulates internal simulation: when to predict future states, how far, and when to skip.
Result: 30B competing with 685B–1T at a fraction of the token cost.
Model and code available
This is a prototype using language-based world models. Stay tuned for our next steps on multimodal and physical world models.
The concept of a configurator, which decides when and how deeply to engage a reasoning process, is not specific to planning, but extensible to learning and adaptation going forward.
📄 SR²AM: https://t.co/LKeXZFN8Hh
📄 SiRA: https://t.co/5JzLSEu4nO
🌐 Project: https://t.co/1CUlEdFMxY
💻 Code: https://t.co/JSBoERYHaB
🤗 SR²AM-v0.1-8B: https://t.co/b1kkuvFL6k
🤗 SR²AM-v1.0-30B: https://t.co/PES00q6a4J
Joint work with @jinyuhou0, @larasnevess, @varad0309, @tw_killian, @waterluffy, @ericxing
New work led by the inimitable @mdeng34 and @jinyuhou0.
We took a fair bit of time thinking about whether an agent can assess how much effort it needs to spend on thinking through the problems it is presented. The resulting algorithm is one step to a fully adaptive future!
Frontier LLMs are converging on efficient, adaptive reasoning. Opus 4.7 lets the model decide how deeply to reason. GPT-5.5 achieves strong results with fewer reasoning tokens.
We study a related but more structural question: what 𝗸𝗶𝗻𝗱 𝗼𝗳 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 should we adapt?
Last year in SiRA (upper figure), we showed that simulative reasoning (System II), which uses a 𝘄𝗼𝗿𝗹𝗱 𝗺𝗼𝗱𝗲𝗹 to evaluate consequences of actions, yields up to 124% improvement over reactive baselines (System I), and that strong reasoning models (o1, o3-mini) fail as planners without this structure.
In our new paper SR²AM (lower figure), we add a learned 𝗰𝗼𝗻𝗳𝗶𝗴𝘂𝗿𝗮𝘁𝗼𝗿 (System III) that self-regulates when to simulate, how far ahead, and when to skip planning entirely.
Efficient reasoning is not just shorter reasoning: it is better allocation of simulation.
It's never made sense to me that RL collapses all reward signals to a single scalar. Today, we fix that!
Introducing Vector Policy Optimization: we train models to inherently optimize for the varied nature of a reward vector, creating diverse sets of answers ideal for test time search. Website and code coming soon!
Reminder! RLBRew deadline in coming up in 7 days! Submit your works soon👩💻
Reminder that we accept under review papers! This is a good place to discuss your ideas and get feedback from the community