I built a Gradio app to dive into the latent space of the new V-JEPA 2.1 models. Found something interesting: specific latent dimensions are hyper-sensitive to temporal shifts, regardless of the video content. Could be an insight into its world model logic... or just a nothing burger.
Picture reaching for something on a high shelf and coming up short. You don’t give up; instead, you find a stool, carry it over, and climb up. Buried in that action is something remarkable: You held the goal in your mind, identified what you needed, and executed a plan. No training required.
A study suggests bumble bees can do the same—the first demonstration of this kind of goal-directed problem-solving in an insect.
Learn more: https://t.co/srV4TqUTsp
AI needs vastly more data than we do. One idea might close the gap: don't predict raw signals (tokens), predict your own abstract latent representation (JEPA, data2vec).
With @DanKorchinski@MatthieuWyart, on a toy model, we prove how much that helps: the gap is exponential.
🧵
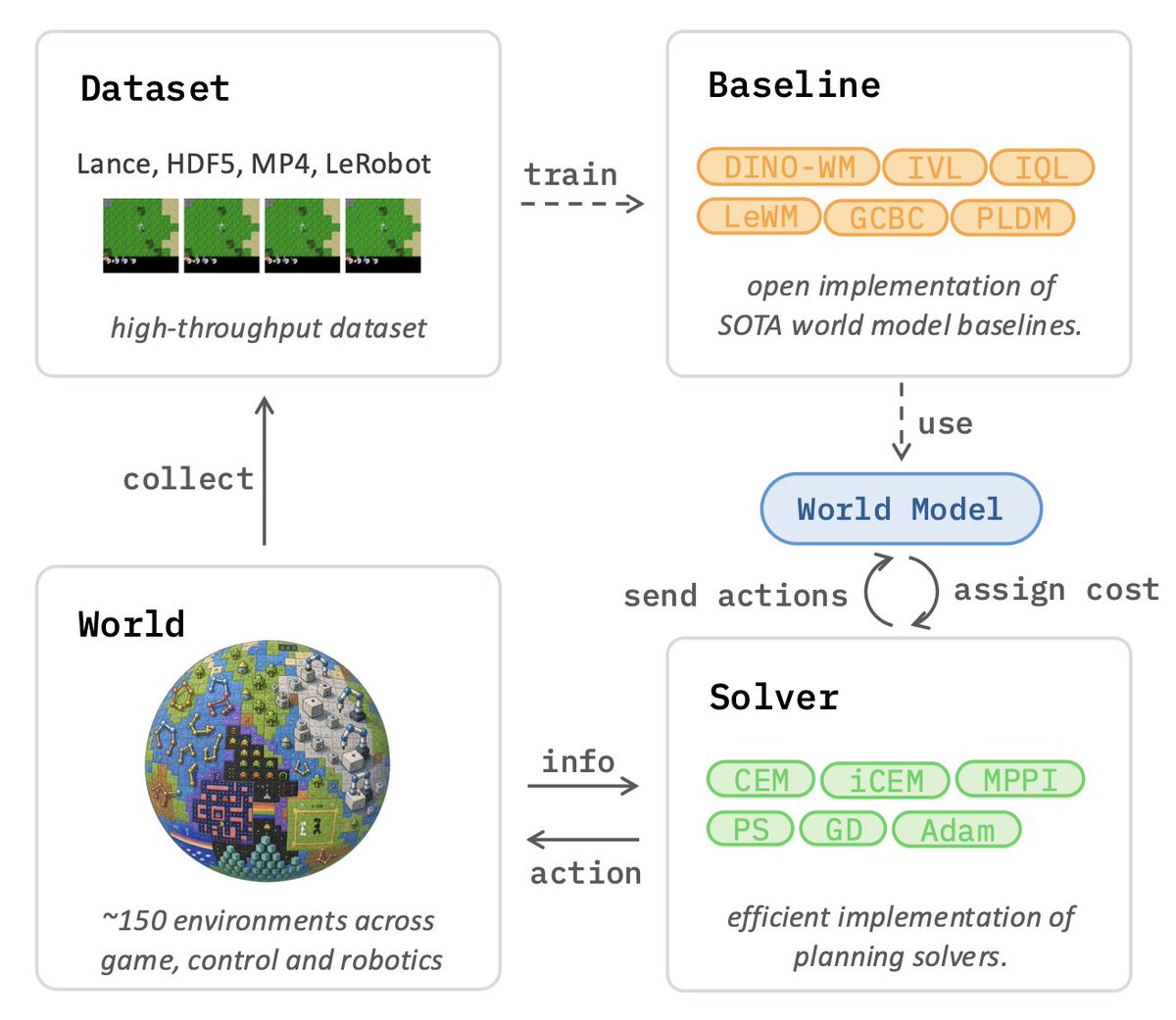
Would you like to join the research effort on JEPA and World Models easily?
After a full year of hard work, we’re excited to finally release stable-worldmodel:
an open-source, scalable platform built to accelerate JEPA & World Model research!
📄: https://t.co/gnxGvens5A
Two weeks ago, watching Agnessa Pedersen mind control a drone in real time, was one of the most moving moments in my career. Agnessa is a rare and wondrous human working towards a wild future.
Do AI models really learn physics, or just learn what physics looks like?
Flatiron's @_helenqu, with @PolymathicAI & CDS researchers including @ylecun, finds that models predicting in latent space recover physical parameters better than pixel-level ones.
https://t.co/DRuHoLqCTK
The same calculator handles a wide range of tasks, including:
- arithmetic (“7+9”)
- weekdays (“nine days after Friday”)
- months (“six months after August”)
Llama built this mechanism from scratch in training, and uses it with striking elegance and flexibility. (4/6)
Our paper "Many Needles in a Haystack" has been accepted at ICML 2026 — see you in Seoul! 🇰🇷🧬
CRISPR screens can test thousands of genes, but budgets are tight and hits are rare. Which perturbations should you run next?
We frame this as a lab-in-the-loop design problem: AI proposes a batch → lab runs it → readouts update the model → repeat. Each cycle gets smarter about where hits are hiding.
Our method, Probability-of-Hit, recovers more hits across 5 real immunology screens. More hits per plate, fewer wasted wells.
Great work by Andrea Rubbi, Arpit Merchant, Samuel Ogden, Amir Akbarnejad, with Pietro Lio & Sattar Vakili 🎉
#ICML2026 #ActiveLearning #PerturbSeq #FunctionalGenomics #CRISPRscreen #LabInTheLoop #AI4Science #BayesianOptimization
A creature smaller than your fingernail just solved the hardest problem in evolutionary biology.
This male peacock spider weighs less than a grain of rice. His brain contains roughly 100,000 neurons.
For comparison, a honeybee has a million. Yet this tiny spider executes a courtship routine so intricate that human choreographers study his movements.
He raises his abdomen like a neon billboard, revealing patterns that shift from electric blue to golden yellow. His front legs wave in perfect synchronization while his third pair of legs vibrate at frequencies that create substrate tremors only the female can detect. The entire sequence lasts exactly 47 minutes and involves over 300 distinct movements performed in precise order.
Get one step wrong and she eats him alive.
Sexual selection created the cruelest performance review in nature. The female peacock spider doesn't just judge his dance. She measures his genetic fitness, his neurological precision, and his ability to execute complex motor functions under lethal pressure. Every movement broadcasts information about his DNA quality, his developmental stability, and his cognitive processing speed.
What breaks your brain is the computational load. This spider must simultaneously control eight legs in different patterns, monitor her behavioral cues, adjust his display intensity in real time, and maintain perfect rhythm across nearly an hour of continuous performance. His nervous system is processing sensory input, motor output, and decision trees at a speed that would challenge supercomputers.
Evolution built a microscopic performer capable of calculations that required millions of years to perfect, all contained in a brain you could barely see without magnification.
The universe keeps hiding its most sophisticated engineering in the smallest packages.
Yesterday I shared an illustration of a solar prominence.
Today, here is the actual video from NASA.
Imagine a raging wall of fire taller than planet Earth, violently twisting and erupting straight off the Sun’s edge.This is a real solar prominence captured by NASA’s Solar Dynamics Observatory in extreme ultraviolet light.
Superheated plasma reaching 10,000–100,000°C is sculpted and held suspended by the Sun’s immense magnetic fields, forming structures that easily dwarf our entire planet.
Adaptive Patch Transformers (APT), a method to accelerate vision transformers (ViTs) by using multiple different patch sizes within the same image. APT reduces the total number of input tokens by using larger patch sizes in more homogeneous image regions, and smaller patches in more complex ones.
APT achieves a drastic speedup in ViT inference and training, increasing throughput by 40% on ViT-L and 50% on ViT-H while maintaining downstream performance.
It can be applied to a previously fine-tuned ViT and converges in as little as 1 epoch, enabling training on high-resolution images with minimal compute budgets. It also significantly reduces training and inference time with no performance degradation on high-resolution dense visual tasks, achieving up to 30% faster training and inference on visual QA, object detection and semantic segmentation.
Paper Title: Accelerating Vision Transformers with Adaptive Patch Sizes
Project: https://t.co/SXnJSEdUP8
Link: https://t.co/3JbdcbcLiC