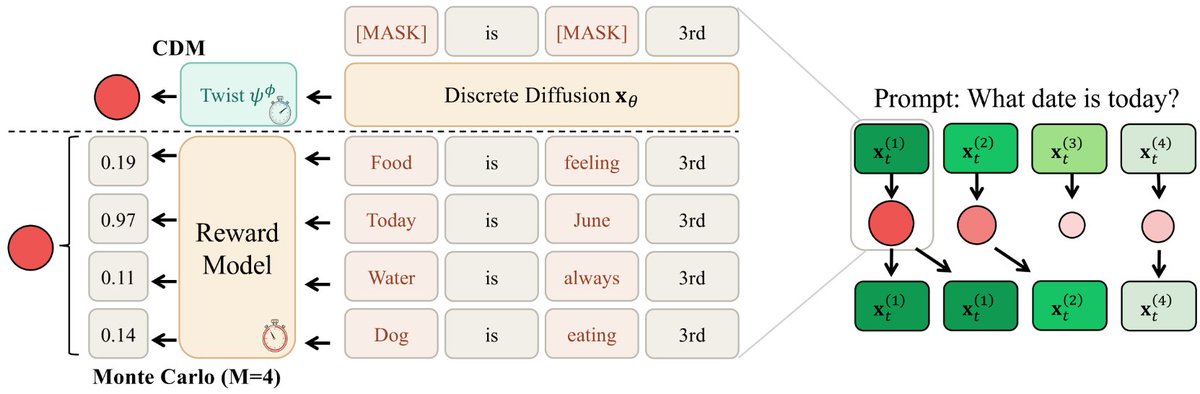
(1/9) Should we fine-tune the diffusion model for reward alignment? 🤔
Not really. Instead, learn the twist function.
We introduce Contrastive Distribution Matching to amortize the cost of inference scaling. 🚀
Website: https://t.co/Kq9xL4SZkH
Paper: https://t.co/7a1DdK4OnY
FUDOKI: A Multimodal Model Purely Based on Discrete Flow Matching
Really nice work. Uses embedding distances to define corruption process, and a single unified bidirectional Transformer + Discrete Flow model for both image and text generation. No special mask tokens involved!
We present our paper
"Ψ-Sampler: Initial Particle Sampling for SMC-Based Inference-Time Reward Alignment in Score Models"
Check out more details
arXiv: https://t.co/pDSllDC79O
Website: https://t.co/PCRYxlUBiI
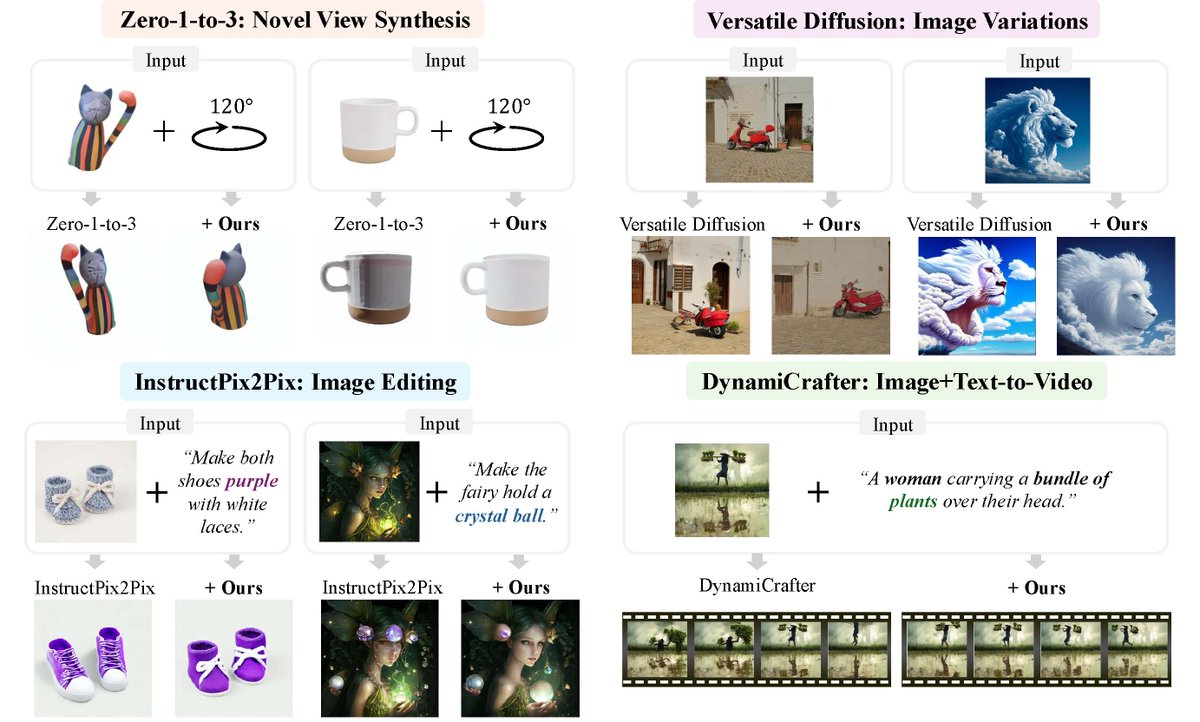
❗️Vision-Language Models (VLMs) struggle with even basic perspective changes!
✏️ In our new preprint, we aim to extend the spatial reasoning capabilities of VLMs to ⭐️arbitrary⭐️ perspectives.
📄Paper: https://t.co/qq5s8jHtVN
🔗Project: https://t.co/sh5W8VLwZO
🧵[1/N]
🚀 We’re hiring!
The KAIST Visual AI Group is looking for Summer 2025 undergraduate interns.
Interested in:
🌀 Diffusion / Flow / AR models (images, videos, text, more)
🧠 VLMs / LLMs / Foundation models
🧊 3D generation & neural rendering
Apply now 👉 https://t.co/h7FdzC8Hmt
🔥 Grounding 3D Orientation in Text-to-Image 🔥
🎯 We present ORIGEN — the first zero-shot method for accurate 3D orientation grounding in text-to-image generation!
📄 Paper: https://t.co/x20WdG96Hs
🌐 Project: https://t.co/fE7ozSbf46
GPT-4o vs. Our test-time scaling with FLUX (1/2)
GPT-4o still cannot count objects (see the ten, not seven, tomatoes on the left), but our test-time technique makes it work with FLUX.
What you need is not a new model, but a test-time technique!
🌐 https://t.co/3zMdsrp1Ln
Inference-time scaling can work for flow models
@kaist_ai proposed 3 key ideas to make it possible:
• SDE-based generation – Adding controlled randomness allows flow models to explore more outputs, like diffusion models do.
• VP interpolant conversion – Guides the model from noise to image using "variance-preserving", so the model explores a wider range of outputs.
• Rollover Budget Forcing (RBF) – Distributes computation effort over time, assigning more resources to the steps that matter most.
Details🧵
5/ Choice of Unconditional Prior
Should the unconditional noise come from the base model or another unconditional model? Notably, We find that the base model does not necessarily need to be the true base model but can be another diffusion model with good unconditional priors.
🔥 Pushing flow models to new frontiers 🔥
🚀 Our inference-time scaling precisely aligns pretrained flow models with user preferences—such as text prompts, object quantities, and more—for under $1! 💵
📄 Paper: https://t.co/O1g6eAErVL
🔗 Project: https://t.co/8aXZD78WrN
🌟 Check out our SyncTweedies code! We introduce a general diffusion synchronization approach that enables the generation of diverse visual content, such as panoramas and mesh textures, using a pretrained image diffusion model in a zero-shot manner.
🌐 https://t.co/Ml5cj49i9R
🚀 Code for SyncTweedies is out!
Code: https://t.co/kifi811CRM
SyncTweedies generates diverse visual content, including ambiguous images, panorama images, 3D mesh textures, and 3DGS textures.
Joint work with @63_days @KyeongminYeo@MinhyukSung .
���ReGround is accepted to #ECCV2024!
📌 https://t.co/bMIwU25VRn
Crucial text conditions are often dropped in layout-to-image generation.
🔑 We show a simple rewiring of attention modules in GLIGEN leads to improved prompt adherence!
Joint work w/ @MinhyukSung
A major update from the previous version!
In the paper, we discuss how Polyak's momentum induces *larger* catapults and explain it via the self-stabilization of @alex_damian_.
Led by @PrinPhunya (kudos!) + myself, and joint work with Bohan Wang, Huishuai Zhang, and Chulhee Yun





















![yuseungleee's tweet photo. ❗️Vision-Language Models (VLMs) struggle with even basic perspective changes!
✏️ In our new preprint, we aim to extend the spatial reasoning capabilities of VLMs to ⭐️arbitrary⭐️ perspectives.
📄Paper: https://t.co/qq5s8jHtVN
🔗Project: https://t.co/sh5W8VLwZO
🧵[1/N] https://t.co/Bo3axJ16k9](https://pbs.twimg.com/media/Gps5FBDbAAAHzZR.jpg)