Apache Calcite is the most popular query optimization framework and a prominent member of the "composable data systems" movement. Our new blog post analyzes the drivers of Calcite's success and how we can use this knowledge to push innovation further.
https://t.co/Z0YMsUeYGn
How to avoid the full scan when joining a large fact table without predicates with a small dimension? Read our new blog post about dynamic filtering, a must-have optimization that skyrockets your analytical engine performance. We use Trino as an example. https://t.co/bTanQof2vL
Aggregation is one of the most frequently encountered operations in analytics. Our new blog post discusses how Apache Calcite and Trino optimizers deal with distinct aggregations and why you may need joins and window functions here. https://t.co/OhxMeAxDuL
Yaay, just surpassed the 1k commit mark on DuckDB (about 3.5 years from my 1st one) and has been a hell of a ride, with a bit of everything, from indexes, joins, data skipping, columnar format integrations, optimizer, aggregation functions, python API, types (enums, nested),…
Read an article the other day that was like “it’s pretty inefficient to separate compute and storage for analytics, maybe we should support predicate and projection push down to storage” and people were like “whoa” and that’s how I know how old all of you are.
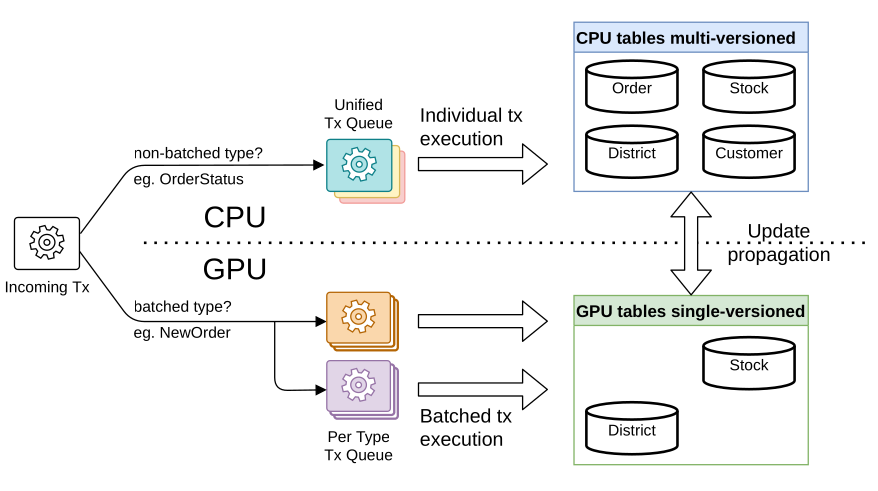
Our paper "#GaccO - A GPU-accelerated OLTP DBMS" was accepted to @2022Sigmod .
In this work, we propose a system that accelerates #OLTP workloads by leveraging
both CPU and #GPU ressources.
AFAIK Stavros is making the provocative argument that @tiledb's matrix data model should be used for any database. It's a bold strategy, cotton. Let's see if it pays off for him.
TileDB is another @samrmadden spin-off start-up from his work with @Intel Labs and @ISTC_BigData.
Vaccination DB Talk 2nd Dose #2 - Jagan Sankaranarayanan presents the Google Napa data warehouse: https://t.co/DbzcmgoHA3
I've known about Hakan's team and Napa project for several years. It's great that they can talk publicly about it now. Jagan is only scratching the surface.
If you haven't heard, Napa is Google's new internal data warehouse that replaces Mesa (VLDB'14). This should be a good talk. See their new VLDB'21 paper that describes Napa's architecture: https://t.co/RMlnXAPpWc
In query optimization, the number of possible plans grows exponentially with the query's complexity.
This blog post discusses memoization - a technique that allows cost-based optimizers to consider billions of alternative plans in a reasonable time.
https://t.co/C1Iv53fWF7
Want to know what is cost-based optimization? In this blog post, we discuss how query optimizers use costs to find the best execution plan.
https://t.co/VvghVvxUJE
Rule-based query optimization is a popular pattern used in many modern engines. Our new blog post gives an overview of rule-based optimization and its applications in Apache Calcite, Presto, and CockroachDB. https://t.co/q0AgNwAfce