Introducing Ideogram 4.0: the best open image model in the world.
Think it. Make it. Own it.
Download the weights, fine-tune on your own data, and run it on your hardware. Live on every Ideogram plan and the API today.
Wow, the S&P Dow Jones Indices has just officially announced that they will NOT be changing their inclusion rules to make it easier for “MegaCap” companies (such as @SpaceX) to be fast-tracked into the S&P 500.
Their reasoning:
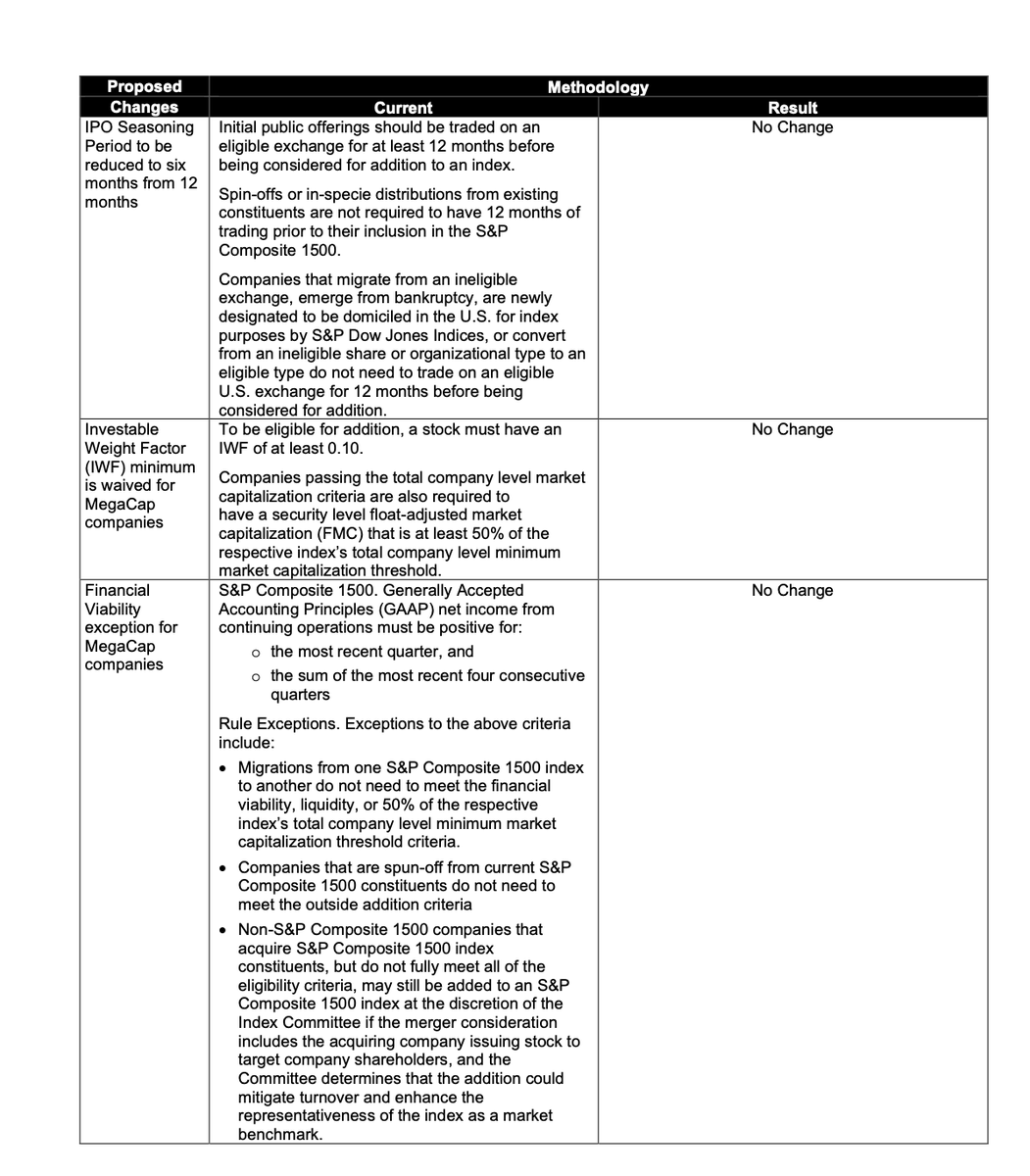
"S&P DJI determined that exceptions to the financial viability, seasoning, and IWF requirements should not be granted solely based on market capitalization. The decision not to adopt the proposed exceptions preserves core index principles by maintaining consistent application of these key requirements. Although there may be trade-offs between strict adherence to these eligibility requirements and broad representativeness, the current methodology provides substantial market coverage and sector balance. As a result, the indices can continue to meet their stated objectives while preserving their role as representative and investable benchmarks for the U.S. equity market.
No changes will be made to the eligibility criteria including financial viability screens, seasoning period, or minimum IWF, for the S&P 500, S&P MidCap 400, or S&P SmallCap 600 as a result of the S&P Dow Jones Indices consultation on the treatment of MegaCap companies. Accordingly, there will be no changes to existing methodology for this index family."
This means that the earliest @SpaceX could be eligible to be added to the S&P 500 would now be June 2027.
The requirements that will now remain in place are:
• No changes to S&P 500 eligibility rules for mega-cap companies.
• Mega-cap companies will still need to wait 12 months after their IPO before being considered for S&P 500 inclusion.
• S&P will not waive profitability requirements for mega-cap companies. The company must have positive GAAP net income in the most recent quarter, and the sum of the most recent four consecutive quarters.
• S&P will not waive minimum public float requirements for mega-cap companies. At least 10% of a company's shares must be publicly tradable ("free float").
The S&P rejected proposals that would have:
• Reduced the IPO seasoning period from 12 months to 6 months
• Waived profitability requirements
• Waived minimum public float requirements
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇
Super excited to announce seven new world-class MAI models today. They represent what we consider a new era in AI designed to keep you in control and on the frontier.
First is our text foundation model, MAI-Thinking-1, exceptionally strong on reasoning and SWE tasks.
- It’s a 35B active parameter MoE with a 256K context window. Independent human raters on Surge prefer it for overall quality in blind side-by-sides versus Sonnet 4.6, and it’s achieved 97% on AIME 2025, the key measure of its general-purpose reasoning abilities.
- It's at 53% on SWE Bench Pro, placing it right alongside Opus 4.6 on one of the toughest coding benchmarks.
- And since we co-designed our models with our own silicon, MAI-Thinking-1 is optimized on our MAIA 200 chip. Benchmarking head-to-head against the GB200, we see 30% better performance per dollar as well as a 1.4x performance-per-watt gain when running our MAI models on the MAIA 200 end-to-end.
Next is MAI-Image-2.5 and its Flash variant. Two super strong models now at #2 on the leaderboards, surpassing the score of Nano Banana 2 on image editing.
Last for now is MAI-Code-1-Flash, our new inference efficient coding model, especially tuned for VS Code and GitHub Copilot CLI.
- Code-1-Flash achieves 51% on SWE Bench Pro, despite having just 5B parameters, putting it closer to Haiku in size but cheaper in cost.
All of this is the foundation for Microsoft Frontier Tuning. It lets you customize our models to create custom, company-specific agents that only you control. You can make our model, your model. Your data. Your agents. Your moat.
Early adopters are already seeing a difference. When we tuned our models for McKinsey’s tasks, MAI delivered the highest win rate, outperforming GPT-5.5 on quality, while being 10x lower on cost.
Also really excited to be collaborating with the amazing team at Mayo Clinic to jointly train a new frontier AI model for healthcare.
Our announcements today mark another milestone on the road to humanist superintelligence. You can learn more and about our other new models in our latest blog: https://t.co/v65eop5Ixq
Today we're releasing Mellum2: our first "serious" LLM.
This is a 12B A2.5B MoE LLM pre-trained on ~11T tokens and post-trained with RLVR.
I'm proud to be leading the team that was working on it for the last 6 months.
We release base/SFT/RL checkpoints along with a tech report
Inference Optimizations Behind the MiMo-V2.5 Series API Price Reductions
Read the full technical blog: https://t.co/B5tp4tdnim
The V2.5 model family, including MiMo-V2.5 and MiMo-V2.5-Pro, is built on a Hybrid Sliding Window Attention (Hybrid SWA) architecture, which compresses KVCache storage to roughly 1/7 that of Full Attention. However, architectural advantages rarely translate directly into measurable gains in production serving. To realize these gains, we redesigned KVCache management, tiered caching, and the prefix-cache tree; addressed key challenges in SWA KVCache handling; and optimized scheduling as well as the Prefill/Decode pipeline.
Validated on real production traffic, these optimizations have increased effective KVCache capacity by nearly 5x, with server-side cache hit rates averaging 93%–95% across mainstream harness frameworks. Together with MoE configuration tuning and multimodal inference optimizations, they enable more efficient long-context inference and form part of what makes the recent API price cuts possible.
Isn’t it about time for the Nothing Watch (1)? ⌚️
A watch running WearOS, powered by Essential Space, would be absolutely perfect. What do you think, @nothing? @getpeid ⚪️
🚀 Better inference efficiency, lower costs, broader access.
MiMo-V2.5 Series API pricing is now permanently reduced — by up to 99% compared to previous pricing.
✨ Unified pricing across all context lengths.
MiMo Token Plans have also been upgraded:
• 5–8× more usable tokens at the same price
• Simpler and more transparent billing rules
🎁 As a thank-you to current users, all current Token Plan credits will be fully reset.
🎧 MiMo-V2.5-TTS remains free for a limited time.
⏰ Effective May 26 at 6:00 PM PDT.
These improvements are powered by continued inference optimization and serving efficiency upgrades across the MiMo stack.
🛠️ We’ll also publish a detailed technical blog on the inference optimizations later — stay tuned.
What if @nothing made a laptop? 💻
Introducing NOTHING BOOK. A speculative exploration of a gaming/creator powerhouse wrapped in Nothing’s signature design language. Transparency meets performance. ⚪️
CXMT, China’s major DRAM producer, is entering global consumer memory supply chains
A Corsair DDR5-6000 16GB Vengeance module was spotted using ChangXin Technologies, CXMT, DRAM
DRAM supply is tightening because Samsung, SK Hynix, and Micron are prioritizing HBM, LPDDR5X, and other AI-related memory products. That leaves less capacity for standard PC DRAM, forcing module makers like Corsair to look for alternative suppliers
CXMT is improving quickly. It is already offering DDR5 up to 8000 MT/s, with 16Gb and 24Gb dies, while other Chinese memory companies are also pushing into DDR5 RDIMMs for data centers and workstations
The Corsair kit shown is DDR5-6000, CL36, which is roughly in line with common Samsung and SK Hynix-based DDR5 kits at similar specs
In Kenya, the average citizen earns KSH 20,000 a month.
In that same Kenya, a Senator is "owed" KSH 18,000 A DAY for "food and drinks".
By that poor citizen.
It is perversion of government into an extraction machine.
Aleph 2.0 is here. Now you can edit a single frame in your video, preview the change and then Aleph 2.0 carries that edit across the rest of your video.
Try it now in the new Edit Studio on web at the link below.