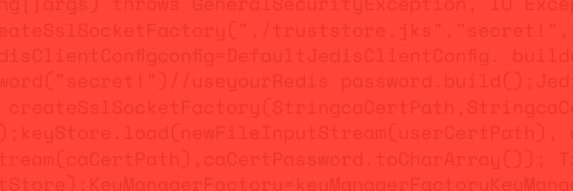
Plus end-to-end throughput improvements across strings, hashes, streams, sorted sets, bitmaps, and more. Download Redis 8.8 here: https://t.co/PylA7I1Vne
Redis 8.8 is here — free to download for anyone on Redis Open Source.
New data structure, a built-in rate limiter, faster streams, and throughput gains across the board. Read all about it here: https://t.co/NHIcjvRAma 🧵
More upgrades:
➡️Hash subkey notifications — subscribe to field-level events
➡️Multiple time series aggregators in one command (hello, candlestick charts)
➡️Explicit JSON float storage: BF16/FP16/FP32/FP64
➡️New COUNT aggregator for sorted set unions/intersections
I built an agentic thing for an upcoming livestream that I'll be on. While building that agentic thing, I learned a lesson. I already knew the lesson. But I didn't know that I knew the lesson. Pretty sure this is called an epiphany. You probably know it too and might benefit from the epiphany. So, I'm gonna share it and then shamelessly plug the livestream.
The thing I built is called Earshot. Earshot consists of three agents: two listeners—one on a microphone, one on my ham radio—that transcribe whatever they hear, decide if it needs any correction, and write it down. And a chatbot that reads what they wrote and lets you, well, chat about it. That's the whole app.
Here's the cool bit. These three agents never talk to each other. The listeners don't know the chatbot exists. The chatbot doesn't know the listeners exist. They just read and write the same shared memory. Ain't nobody wired to anybody.
If that sounds familiar, it should. It's decoupling. The same decoupling we've done with message queues and shared databases and job tables for decades—producers on one side, consumers on the other, some sort of store in the middle. Neither end holding a reference to the other. I reached for it intuitively without realizing I was implementing the same distributed-systems pattern I've used scores of times in the past.
And since this isn't really new, the tradeoffs are the same. No delivery guarantees, no ordering. Things happen when they happen if they happen. Decoupling buys you flexibility at the cost of certainty, same as ever.
But that flexibility is so, so nice. It lets you scale and it lets you extend. Since nothing is wired together, you can add more listeners and more types of listeners, more chatbots and more types of chatbots. Potentially a lot more if your shared state can scale with them.
In Earshot, I used Redis for the shared state, specifically Redis Agent Memory. It was easy to use and gives me scaling, scaling that my toy agents don't really need. But your agents, which do real work for real users, will totally need it. Probably sooner than you think.
I built all of this in VS Code and used GitHub Copilot to assist. In particular, I used Redis' set of agent skills so that Copilot would know how, and more importantly when, to use Redis Agent Memory's APIs.
I plan to demo it all on VS Code Live this Thursday, June 4 at 9am PT. Join @ReynaldAdolphe and me as we take a chatbot that starts with no memory and, one capability at a time, learns to listen to what is in earshot.
Livestream:
https://t.co/8GTNskyvsI
GitHub repo with the demo:
https://t.co/kijROed9qx
Redis Agent Skills:
https://t.co/T5aWsRHvRV
Redis Agent Memory & Redis Iris:
https://t.co/vR768UmJcc
https://t.co/5Rpm7FP3sb
@Redisinc@code@GitHubCopilot
This weekend, join us in SF for our 4th WeaveHacks hackathon!
Sponsored by @OpenAIDevs for the first time (+ @dkundel judging!), @cursor_ai ,@Redisinc and @CopilotKit , Hackers will get over $150 in credits to build multi-agent orchestration systems + Over $15K in prizes!
Last week, we launched Redis Iris, our real-time context engine for AI apps.
AI agents forget everything when a conversation ends. They can't query structured data without custom code. Redis Iris changes that.
We’ve put together a tutorial that shows off two of the core pieces of Redis Iris. Redis Context Retriever turns your entity data into auto-generated MCP tools any agent can discover and call. Redis Agent Memory gives agents persistent session memory and cross-session long-term memory backed by vector search.
A couple of days have passed and we are still thinking about the great conversations from the official Redis Meetup at the One2N.
Thank you to everyone who joined us for a hands on day of building with Redis semantic caching and routing. Until the next one.
We made the @Redpoint InfraRed 100, a list that recognizes the companies that are building the AI infrastructure of today and tomorrow through reliability, scalability, security, and innovation.
Context orchestration at scale is the most important problem to be solved in the agentic era. We’ve built Redis to deliver the right context, with the right meaning, fast enough for agents to act on.
Proud to be building alongside the other teams and companies who raised the bar. Check out the full report: https://t.co/ciajctNqrU
Context is the bottleneck, and unfortunately, it's not something simple to solve.
Here is the way I think about "the right context" (the 4 ingredients I'm always looking for):
1. Context has to be navigable: You want agents to understand and traverse relationships in the context. This is much more useful than thinking of context as "chunks of information".
2. Context has to be fast: You don't want to spend your latency budget retrieving and building your context.
3. Context has to be fresh: You need to decide when your context is stale and when to refresh it.
4. Context has to compound: The more you use the system, the better it should get.
Redis released Iris, a brand new agent context and memory platform that you can use to power smart agents:
https://t.co/kPWMtq5BO5
First, they released the Redis Context Retriever, a semantic layer that sits over your live data.
Instead of getting top-k chunks from a vector store, the Context Retriever lets the agent traverse entities and find related information. For instance, Customer → Invoice → Product.
This is closer to graph traversal than regular retrieval.
Second, they released the Redis Agent Memory, a managed short and long-term memory for agents.
This will handle embeddings, retrieval, summarization, and durable state across sessions.
Every team that's building agents is now reinventing this, and most do it badly.
Third, they made Redis Data Integration generally available. This allows you to continuously sync from Postgres, MySQL, Oracle, warehouses, and document stores into Redis.
This is how you can keep your context fresh.
When you combine these three with Redis Search, you can handle semantic, hybrid, keyword, and structured queries with very low latency.
Thanks to the team for partnering with me on this post.
Context engineering is the single most important area you can focus on right now.
We already have amazing models.
Agents no longer fail because models are dumb. They fail because they don't have the right context.
Here are the 4 ingredients of good context:
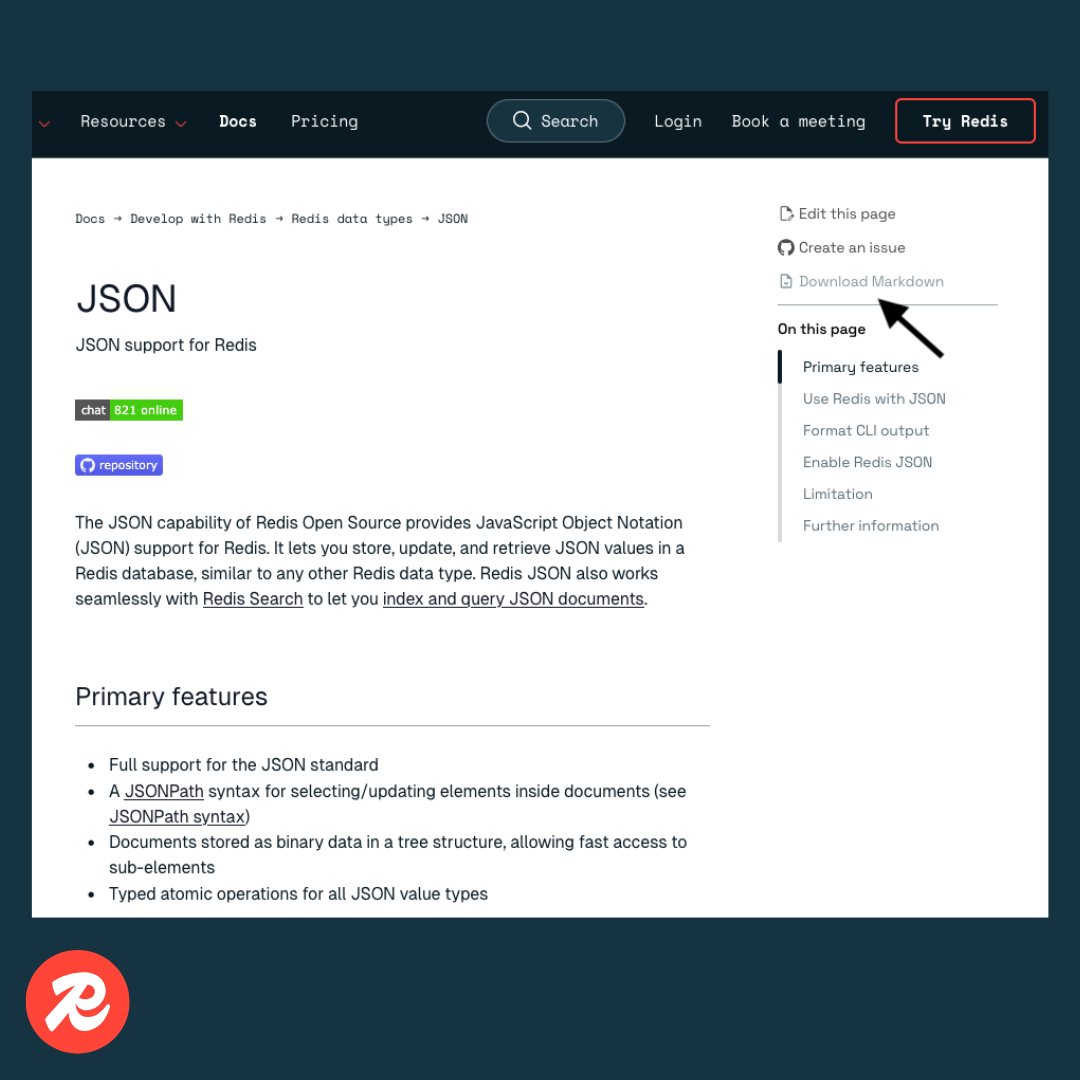
ICYMI: Redis Docs now ships with downloadable Markdown on every content page. Feed them directly into coding agents.
No reformatting. No friction. Just grab the file and build.
Looking for more resources for AI agent development with Redis? We got you: https://t.co/Vkj6KTfGlk
Most Windows microservices don't need Kafka or RabbitMQ.
✅ #Redis Lists for simple queues
✅ Redis Streams for durable processing
✅ Memurai to run it all natively on Windows
C# examples here: https://t.co/9F9s6UT0yb
@Redisinc#DotNet#Memurai#MessageBroker#DevOps
I was building a browser agent the other month when I noticed something.
The tool (Playwright MCP) my agent called when it wanted to navigate a website didn’t return HTML. It returned an accessibility tree.
This was interesting because I’d have assumed we should return HTML. It’s the source of truth for a webpage. But then I thought about what my agent actually needed to do. It didn’t need to render anything. It simply needed to read content and interact with elements. For that job, HTML is full of noise. Styling, layout, structure that only makes sense if you’re a browser.
An accessibility tree strips all of that away.
That made me think about data formats differently. Every format carries assumptions about who’s on the receiving end.
A PDF was designed for print and human eyes. Columns, headers, layout instructions for a renderer. An API response was designed for a frontend, deeply nested, full of display metadata that a UI component needs and an agent doesn’t.
In a sense, every format encodes its intended receiver. The layout assumptions in a PDF are a fingerprint of the human eye. The nesting in an API response is a fingerprint of a UI component.
When we pipe these into an LLM without thinking, we’re not just sending information. We’re sending information wrapped in expectations built for someone else.
I wonder how often we do this blindly. Reaching for the “default” format rather than asking whether it actually serves the agent.
Going forward, the questions I now ask before wiring any data source into an agent: whose world was this format designed for and what does my agent need its format to look like?
If you're building customer support agents, AI copilots, or personalized assistants, this is the memory layer worth understanding. Full tutorial here: https://t.co/8Lcep0MRBv
Most AI agents forget everything the moment a session ends. Redis Agent Memory changes that by giving agents both short-term session context and durable long-term memory that persists across conversations.
Lead Developer Advocate @riferrei builds a LangGraph travel agent that uses Redis Agent Memory with:
→ Short-term memory to keep the current conversation coherent
→ Long-term memory to store preferences and facts across sessions
→ Background extraction to decide what's worth keeping and what isn't