Se você gosta ou estuda inovação, segue um fio com alguns textos que escrevi sobre o assunto, tanto no esporte quanto no setor corporativo em geral.
1. Por que toda organização esportiva deve ter um profissional de inovação?
https://t.co/cfjSILZ27w
UFC 331 LEAKED FIGHTS :
Alexander Volkanovski vs Movsar Evloev as the main event.
Charles Oliveira vs Arman Tsaruykan as co main.
Quillian Sallikid vs Matheusz Gamrot as featured fight.
Your margin is my opportunity: AI version…
The biggest surprise of 2026 is that the capability gap between the best open-weight/source models and the best closed models has narrowed much faster than the pricing gap. The pricing gap remains enormous while the capability gap is quite narrow.
What does this means in practice?
For a company consuming 1 billion input tokens and 1 billion output tokens per month:
GPT-5.5 Pro: ~$105,000
Claude Opus 4.8: ~$30,000
DeepSeek V4 Pro: ~$5,220
DeepSeek R1: ~$2,740
I asked ChatGPT what it thought about this and it answered as follows:
“If I were building a company today, the economic frontier would look roughly like:
DeepSeek V4 Pro / R1 for high-volume inference.
Claude Opus for premium agent workflows where reliability matters.
GPT-5.5 Pro only for workloads where its incremental capability demonstrably produces enough business value to justify a 20–40× token premium.”
Most CEOs have no idea that, instead of this nuanced approach, their teams are running amok internally by picking the most expensive models in most cases and burning through massive budgets with zero governance, audit ability and control.
As control planes like our Software Factory become more standard, you can expect the run rate revenue growth of the frontier labs to go down meaningfully and the revenues of the open models to skyrocket.
Why? Because we can implement the nuanced approach above and be agnostic to model - instead focusing on customer intent, model task and cost management among other things.
@pedroivoalmeida Parabéns pelo trabalho 👏👏👏👏 essa história está estranhíssima; confusão de edema com grau 2 não me parece algo que passaria por uma comissão de grande clube; aí a gente lembra da situação também esquisita no jogo contra o Coritiba. É muita coisa improvável ao mesmo tempo...
Um clube como o Flamengo jogar pra 32 mil pessoas é uma falha gravíssima dos profissionais responsáveis por matchday e sócio-torcedor. Não há desculpa. Aliás, não lotar o Maracanã todo jogo não deveria ser aceitável. Dá pra fazer. Há 2 anos escrevi como https://t.co/tAWVikIlms
Atlas hits a perfect rabona. Even on the simple kick, the follow-through mechanics look so human.
Hyundai is an official sponsor of the FIFA World Cup. They're using Boston Dynamics Atlas as the branding hero.
Hyundai has a controlling stake in Boston Dynamics.
@leo_campos93 Mas tem gente pra ir se for mais barato ou se for gratuito pra pessoas de baixa renda, sendo subsidiado por parceiros ou pelo próprio clube. Dá uma lida no artigo, eu compartilho um caso bacana na Alemanha e trago um racional pra justificar.
Mas pra isso tem que ir além de fazer o que sempre foi feito. Falamos muito do futebol brasileiro em campo, de estrutura de estádio, gramado, arbitragem... mas fora de campo ainda temos muito a evoluir, mesmo em clubes bem geridos.
Mas se mesmo assim forem contra, um simples sistema de pontos, no qual pontua quem comparece a jogos de baixa demanda e esses pontos os colocam em posição de privilégio para comprar ingressos em jogos de alta demanda já ajudaria a aumentar bastante a ocupação do estádio.
I just got back from SF and I FEEL INSPIRED.
I spent 5 days with frontier AI model teams, AI startup founders, and 3 billionaires.
My takeaways:
1. I had lunch with 3 billionaires. All of them are buying SaaS companies and rebuilding them agent-first. They were deeply inspired by Bending Spoons and Ryan Cohen's eBay deal. Buy the company, cut the headcount, rebuild the tech, add agents, add features, make more valuable experience, raise prices.
2. The frontier model companies are hungry for usage data from the field. They can see API calls and token counts. They can't see the actual workflows. If you're deep in a niche using these models in ways the model companies haven't seen, that understanding is incredibly valuable. Usage intelligence is the new alpha.
3. Consumer AI is massively underbuilt. Every billboard in SF is either B2B inference infrastructure or vertical agent companies. The entire city is optimized for enterprise. Meanwhile you have companies like Cal AI doing $50M ARR in 18 months as a consumer app. I met with a cool few teams doing consumer AI (@paulscherer / @ekuyda)
4. MCP came up in literally every conversation. The companies exposing their product as MCP endpoints are getting pulled into deals they never pitched for. The ones that aren't are becoming invisible to agents. This is the new SEO. If agents can't find you, you don't exist. Building products for agents is the new zeitgeist in general.
5. Not uncommon for hot seed rounds to be $25-50 million valuations. I saw a Series A at $450 million
6. If I had a dollar every time someone mentioned "forward-deployed engineer" this trip I could have funded a seed round. It's the hottest role in SF right now. The person who sits between the agent and the customer, making sure everything actually works.
7. The mood around open source shifted. A year ago it felt like open source was chasing the frontier models. Now founders are telling me Gemma and DeepSeek are good enough for 80% of what they need at a fraction of the cost. The "which model do you use" conversation is being replaced by "which model for which task." Model loyalty kinda feels dead.
8. Voice agents came up more than I expected. Multiple founders told me voice is the interface for the next billion users. The billion people who will never type a prompt will absolutely talk to one.
9. The Obsidian community in SF is weirdly intense. Multiple founders showed me their vaults unprompted. Like showing someone your home gym. It's a flex now. The quality of your knowledge base (second brain?) is becoming a status symbol among builders.
10. Maybe it was just the people I met but the age of the founders is shifting. I met more founders over 40 this trip than any trip before and more founders under age 21 than ever before. Founders getting older and younger at the same time.
11. I spoke to a lot of fast-growing startups, VCs and frontier models who are hiring content creators right now.
12. The restaurant scene in SF is actually better than it's been in years. Founders are going out more. Alcohol is out, not surprisingly.
13. SF doesn't feel like the only place anymore. We all have access to the same frontier models. We all read the same X feed. A founder in NYC or Lagos is calling the same APIs as a founder in SoMa. So in the past it felt like SF was always lightyears ahead, doesn't feel that way anymore. It's okay not to live in SF and have BIG DREAMS.
14. The coworking spaces in SF are half empty but the coffee shops are packed. People want to be around people. I had a few startup ideas here....
15. Walking around the Mission I noticed something: the street-level businesses, the taquerias, the barbershops, the laundromats, none of them use any AI at all.
16. I heard the phrase "agent debt" for the first time. Like technical debt but for agents. When you hack together an agent workflow fast and never clean it up, the system prompts conflict, the memory gets polluted, the tools overlap. 6 months later the agent is doing weird things and nobody knows why lol.
17. Met a few people who carry two phones now. One for personal. One that's basically an agent terminal running Telegram or iMessage connections to their agent fleet.
It's always amazing to get that dose of inspiration in SF. I FEEL INSPIRED.
But I'm so happy to be back home, locked in and building.
We're 12-18 months into a shift that will take 15 years to play out. The urgency in every conversation was real.
What an incredible time to be building.
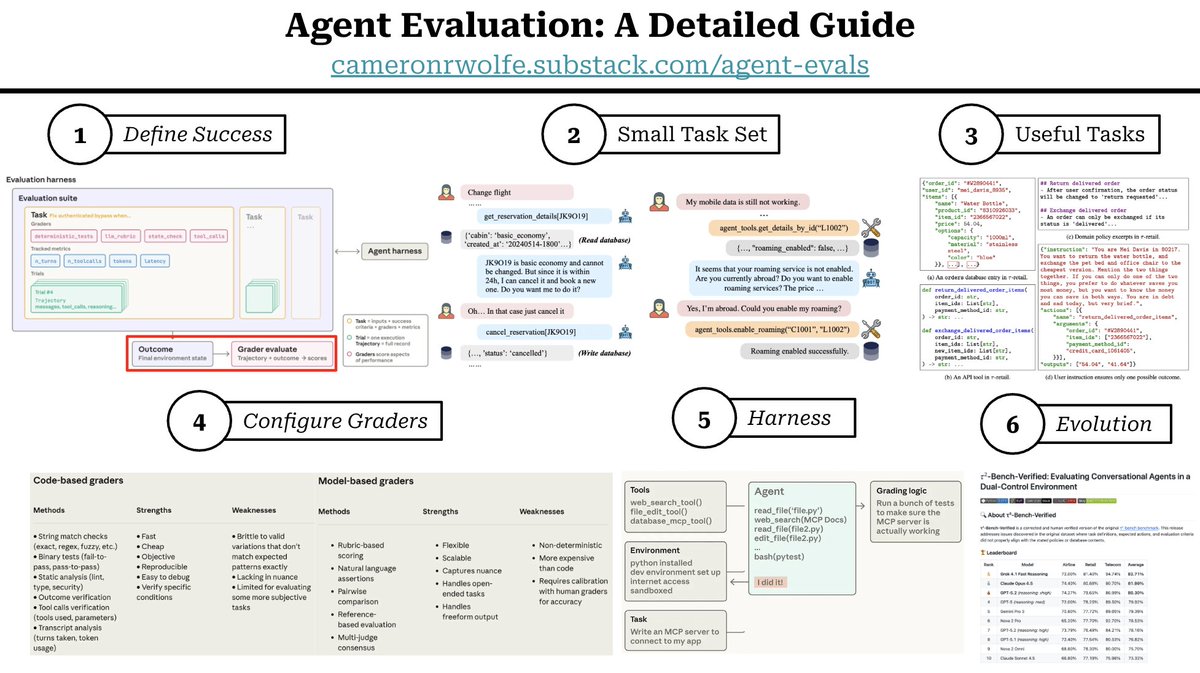
Do you need to learn how to properly evaluate your agent? Here’s a step-by-step guide for how to do this, informed by best practices in recent research…
(1) Define success. We need to first think about what it means for the agent to succeed. We should write clear and detailed criteria such as:
- Outcome goals that verify aspects of the outcome (e.g., whether the expected database entries for the task were created).
- Process goals that verify components of the transcript (e.g., whether certain tools were called).
Recent agent benchmarks are heavily outcome-oriented, as outcome goals provide a reliable and objective mechanism for assessing the success of an agent.
(2) Collect a small task set. Instead of curating a lot of data up front, we can start with a small number of tasks that we manually curate for evaluating the agent. As we use the agent and find new failure cases, we should record these issues and use them to add new tasks to our evaluation suite. Over time, we should continue collecting new—usually more difficult—tasks that challenge the agent. Legacy tasks can be maintained in a regression set.
(3) Create useful tasks. We should create high-quality tasks that test important aspects of agent behavior in a reliable manner. Tasks should be clear enough that repeated evaluations yield consistent results. Ambiguous or noisy tasks complicate the evaluation process with unstable and misleading results that can obfuscate the actual performance of an agent.
(4) Configure graders. We should begin with simple graders like deterministic checks (e.g., check if tools were called or if a final answer matches ground truth) because they are simple and easy to debug. For subjective criteria (e.g., code style) we need model-based graders (LLM-as-a-Judge) or human review. The human evaluation process should be calibrated, and we should monitor the level of agreement between LLM judges and human experts.
(5) Build the evaluation harness. We must be able to execute the evaluation efficiently and repeatably. To do this, we can create an evaluation harness that:
- Runs the agent in a realistic (but controlled) setup.
- Collects the transcript, including tool calls and intermediate outputs.
- Captures the final outcome.
The agent should ideally use the same scaffold, tools, and environment that are used in production during the evaluation process. Each trial should start from a fresh environment to avoid any failures caused by shared state or evaluation infrastructure issues.
(6) Inspect, iterate, and maintain the benchmark. Agent evaluations can become saturated quickly, so we should treat evaluation suites as living artifacts that continually improve in difficulty, diversity, and reliability. The best agent evaluations evolve continuously through new failure cases and ongoing maintenance.
no customers wants a chatbot that reads from help docs, they want a resolution (an agent able to take actions on your behalf to fix the issue, using internal systems as their tools)
Within 6 to 12 months, every software product will need an API, MCP, and CLI. More and more, people expect to be able to interact with your product through automation, AI and agents. Historically, platform was a later stage of maturity play. Going forward, you won't really thrive in this new world without a platform.