Full Professor DSIC-UPV. Former Director of PRHLT Research Center. CTO Solver Machine Learning. European Distributed Deep Learning Library-EDDL Lead Developer.
Introducing Sora, our text-to-video model.
Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions.
https://t.co/YYpOAcrXQ3
Prompt: “Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city street, following several people enjoying the beautiful snowy weather and shopping at nearby stalls. Gorgeous sakura petals are flying through the wind along with snowflakes.”
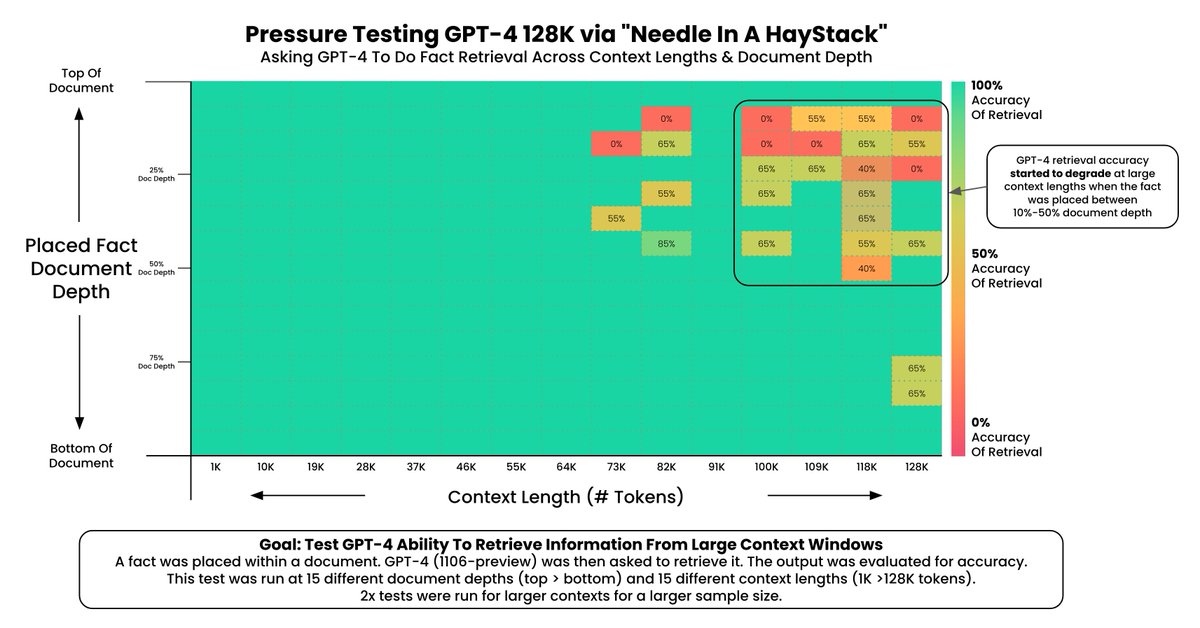
Pressure Testing GPT-4-128K With Long Context Recall
128K tokens of context is awesome - but what's performance like?
I wanted to find out so I did a “needle in a haystack” analysis
Some expected (and unexpected) results
Here's what I found:
Findings:
* GPT-4’s recall performance started to degrade above 73K tokens
* Low recall performance was correlated when the fact to be recalled was placed between at 7%-50% document depth
* If the fact was at the beginning of the document, it was recalled regardless of context length
So what:
* No Guarantees - Your facts are not guaranteed to be retrieved. Don’t bake the assumption they will into your applications
* Less context = more accuracy - This is well know, but when possible reduce the amount of context you send to GPT-4 to increase its ability to recall
* Position matters - Also well know, but facts placed at the very beginning and 2nd half of the document seem to be recalled better
Overview of the process:
* Use Paul Graham essays as ‘background’ tokens. With 218 essays it’s easy to get up to 128K tokens
* Place a random statement within the document at various depths. Fact used: “The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day.”
* Ask GPT-4 to answer this question only using the context provided
* Evaluate GPT-4s answer with another model (gpt-4 again) using @langchain evals
* Rinse and repeat for 15x document depths between 0% (top of document) and 100% (bottom of document) and 15x context lengths (1K Tokens > 128K Tokens)
Next Steps To Take This Further:
* Iterations of this analysis were evenly distributed, it’s been suggested that doing a sigmoid distribution would be better (it would tease out more nuanced at the start and end of the document)
* For rigor, one should do a key:value retrieval step. However for relatability I did a San Francisco line within PGs essays.
Notes:
* While I think this will be directionally correct, more testing is needed to get a firmer grip on GPT4s abilities
* Switching up prompt with vary results
* 2x tests were run at large context lengths to tease out more performance
* This test cost ~$200 for API calls (a single call at 128K input tokens costs $1.28)
* Thank you to @charles_irl for being a sounding board and providing great next steps
La semana pasada celebramos la 2ª edición de nuestro ‘Almuerzo con Inteligencia Artificial’, un encuentro organizado en Madrid que contó nuevamente con Jordi Mansanet, Roberto Paredes y Victoria Corral de Solver como anfitriones y que conecta con empresas que apuestan por la IA.
@elonmusk@clownworld@CommunityNotes No, it is the border between Spain and Morocco. That happens in a particular days when Spain a Morocco relationships were bad… so clearly Morocco can definitively avoid this but they use that as a weapon.