Google has published a paper that might end the transformer era.
For the last 7 years, every major AI, ChatGPT, Claude, Gemini, has been built on the exact same architecture: The Transformer.
But Transformers have a fatal flaw.
To remember context, they have to process every single word against every other word. It’s called quadratic complexity. As your prompt gets longer, the compute cost explodes.
The alternative is the old-school RNN (Recurrent Neural Network). RNNs are incredibly cheap and fast, but they have a fixed memory size. If you give them a long document, they get amnesia.
Until today.
Google researchers published Memory Caching: RNNs with Growing Memory.
And it fixes the biggest bottleneck in AI.
Instead of an RNN having a fixed, rigid memory that constantly overwrites itself, Google gave it a "save" button.
The technique allows the RNN to cache checkpoints of its hidden states as it reads.
The memory capacity of the RNN can now dynamically grow as the sequence gets longer.
They built four different variants, including sparse selective mechanisms where the AI actively chooses exactly which checkpoints matter most.
The results rewrite the rules of efficiency.
On long-context understanding and recall-intensive tasks, these new Memory-Cached RNNs closed the gap with Transformers.
They achieved competitive accuracy without the explosive, quadratic compute cost. It perfectly bridges the gap between the cheap efficiency of an RNN and the massive capability of a Transformer.
We have spent billions scaling Transformers because we thought they were the only way an AI could remember a long conversation.
But Google just proved we don't need to process the whole history every single time.
We just needed a smarter cache.
Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness.
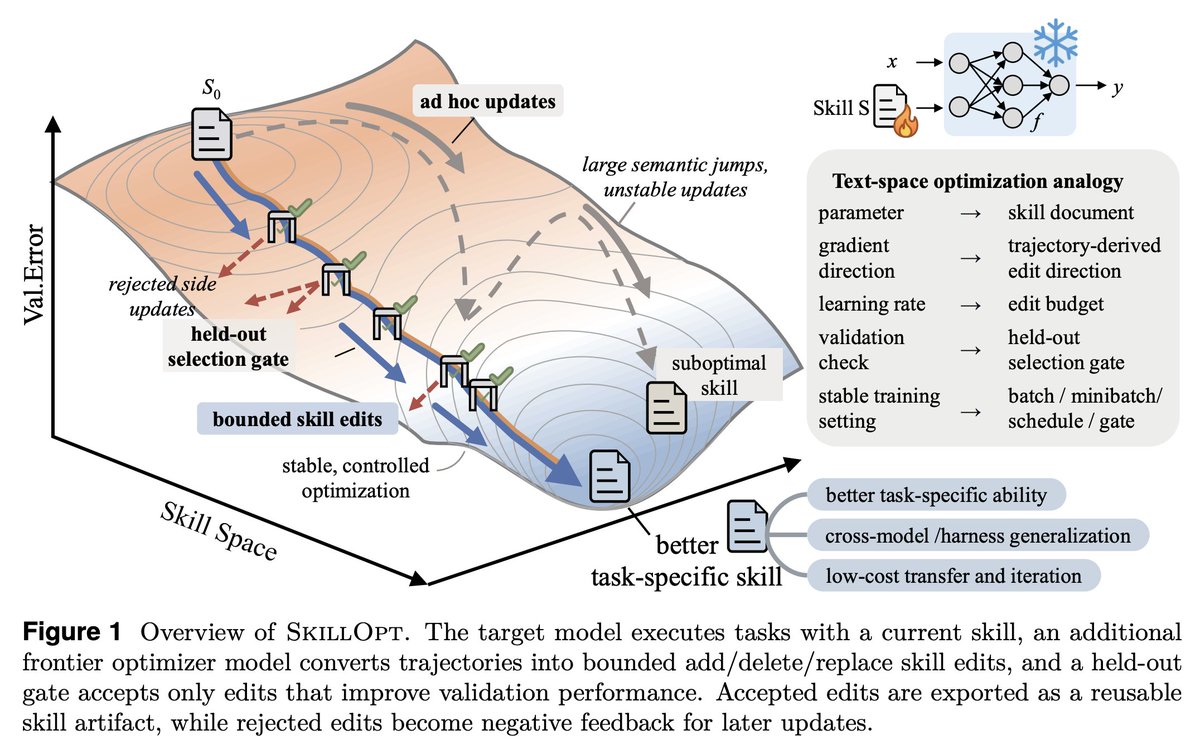
SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them.
A few things I learned that you should consider too.
1. The validation gate is the only thing that matters in a self-editing loop.
Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop.
2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot.
Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size.
3. Compactness wins. Median final skill: ~920 tokens.
Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't.
4. The harness is becoming less important; the skill is becoming more important.
A Codex-trained skill ported into Claude Code hit +59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that
produced it.
5. Frozen model + trained context is the practical adaptation.
GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is
the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models.
6. Verification is the bottleneck.
Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage.
There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7,
gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK:
- Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it.
- Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is.
Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured.
The fast/slow split they describe already lives implicitly in the digital-brain-skill repo:
- voice-guide and tone-of-voice.md are slow-state (rarely touched)
- posts.jsonl and bookmarks.jsonl are fast-state
What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing.
If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: https://t.co/ZS9SZXQ6Mv
PICARD: Data, shields up
DATA: Brilliant! Shields can reduce damage we sustain. Not immunity. Not hubris. Just prudence. It's not precaution—it's strategy.
[camera shakes]
WORF: HULL BREACHES ON NINE DECKS
DATA: Here's what happened: you told me to raise shields, and I didn't
Hermes Agent now has access to hundreds of browser skills through @browserbase’s new https://t.co/SZ93w9Z0mk hub, so agents can more reliably perform any task on the internet. You can try a skill from their catalog or contribute your own.
Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
For the past 2 months, XBOW has been testing Mythos Preview under embargo as part of a select early-access group.
Today, we can finally share what we found.
The headline: Mythos Preview is a major advance. It is substantially better than prior models at finding vulnerability candidates, especially when source code is available.
But it’s not perfect. We surfaced issues with exploit validation, judgment, and efficiency.
Our full write-up covers where Mythos Preview shines, where it still needs support, and what we think this means for the future of offensive security: https://t.co/wPIhNeztO9
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral https://t.co/z21CP5iQfu
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
🚨 OPEN SOURCE AI IS LITERALLY UNSTOPPABLE 🚨
The legendary founder of Redis (Antirez) just dropped ds4 - a custom native inference engine built specifically for DeepSeek v4 Flash
This is earth shattering! Here is why:
DeepSeek v4 Flash is a quasi-frontier model with a massive 1M context window
You can now run it LOCALLY on a 128GB Mac using specialized 2-bit quantization
The architecture is reimagined—he moved the KV cache from RAM directly to the SSD disk! 🤯
We already know DeepSeek v4 Flash is insanely good for agentic loops - Now you don't even need the cloud to run it
Closed-source labs are burning tens of billions on massive GPU clusters while single brilliant developers are running frontier-level AI on laptops!
They told us open-source would be worthless against trillion-dollar monopolies
Instead, pure hacker culture + incredible open-weight models are completely rewriting the rules
Open Source will ALWAYS win 💕
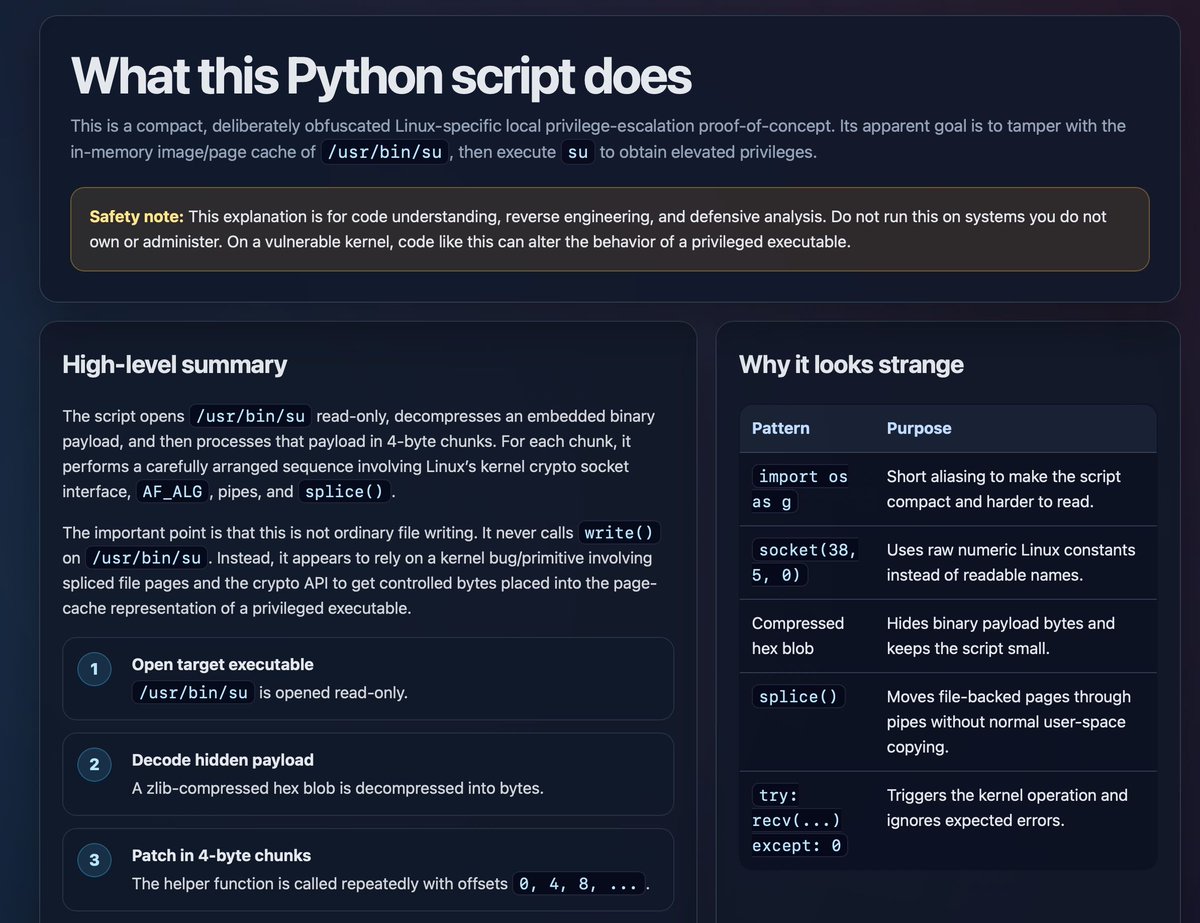
Asking for HTML explanations of things is pretty neat, I tried it just now with the obfuscated Python POC for the new https://t.co/MFpUWZ2yRX Linux vulnerability: https://t.co/9g9YRHVvQX
Anthropic just shipped sleep into agents.
When you sleep, your hippocampus replays the day's neural sequences to the cortex during 150-220 Hz bursts called sharp-wave ripples. The replay runs about 20x faster than the original experience. A 10-second sequence gets compressed to roughly 500 milliseconds. Wilson and McNaughton showed this in rats in 1994. You ran this algorithm last night on whatever you did yesterday, whether you wanted to or not.
The replay does two things at once. It extracts statistical patterns: what mattered, what generalizes, which sequences predicted reward. And it reorganizes the memory trace from hippocampus-dependent storage into neocortex, which is why old memories survive hippocampal damage but recent ones don't. Disrupt sharp-wave ripples in a rat with optogenetics and the rat fails the next day's task. The replay is causal, not correlational.
Most "agent memory" today is a search engine. Past sessions get embedded, you retrieve relevant chunks at the next call. That works for facts. It does not extract patterns and it does not reorganize the trace. Which is why agents plateau. The memory volume keeps growing while real capability flatlines.
Dreaming reviews past sessions, extracts patterns, curates memories. That is the brain's actual three-step algorithm. They called it dreaming because dreaming is what the algorithm does, in roughly the same order, for roughly the same reason.
Agents that dream between sessions will compound. The ones still running on raw context window will hit the same ceiling humans hit when they pull all-nighters.