🚀 We just launched Gemini 3 Pro — the strongest multimodal understanding model ever built.
I lead product for Gemini’s multimodal vision capabilities, and I want to share more about the massive wins we are seeing across document, screen, spatial, and video understanding. 🧵
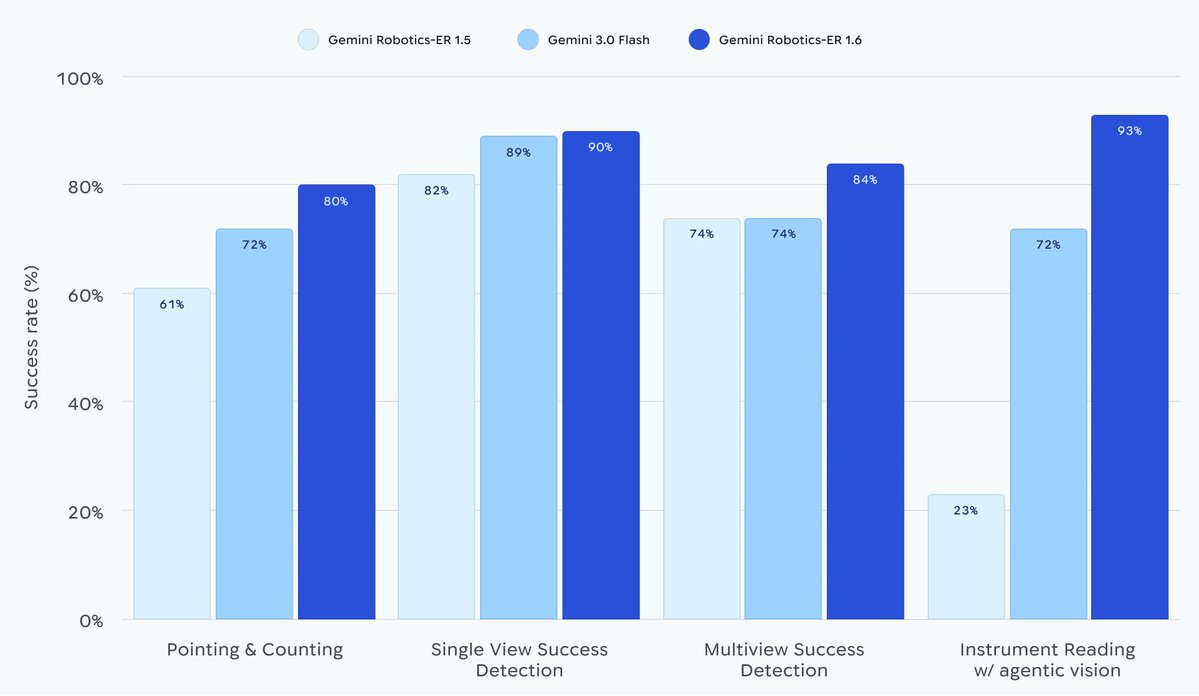
Gemini 3.5 Flash outperforms 3.1 Pro on many vision use cases (like the below Roboflow eval) while being ~6x faster on average 🤯 Gemini multimodal understanding for the win.
Had fun speaking at Cloud Next 2026 as a panelist for "How DeepMind Makes Modeling Decisions" ✨ DM me if you want to keep chatting about the future of frontier models and multimodal agents 🤖
filesystem + code sandbox combo eats another modality.
remember when o3 destroyed at geoguessr?
gemini agentic vision will find location on any street photo you take faster than Liam Neeson can get back his daughter
Gemini 3 Flash now uses an agentic "think-act-observe" loop to solve complex visual tasks 🤖
@GoogleDeepMind engineer @ptruiz_dev demonstrates how the model runs Python code automatically to zoom and inspect items, annotate images, and re-visualize data into charts.
Back at Harvard Business School last week speaking on frontier AI + agents 🤖
As a ’23 alum, it was energizing to be back - this time teaching from the other side of the classroom
My AI agent workshop was completely packed, with 100+ students - signal on how much Harvard is leaning into AI
The students’ agency, raw IQ, and curiosity left me wildly optimistic about the next wave of AI builders 🚀
Grateful to Profs. Jeffrey Bussgang & Allison Mnookin and the Launching Tech Ventures team for the invite 🙏🏼
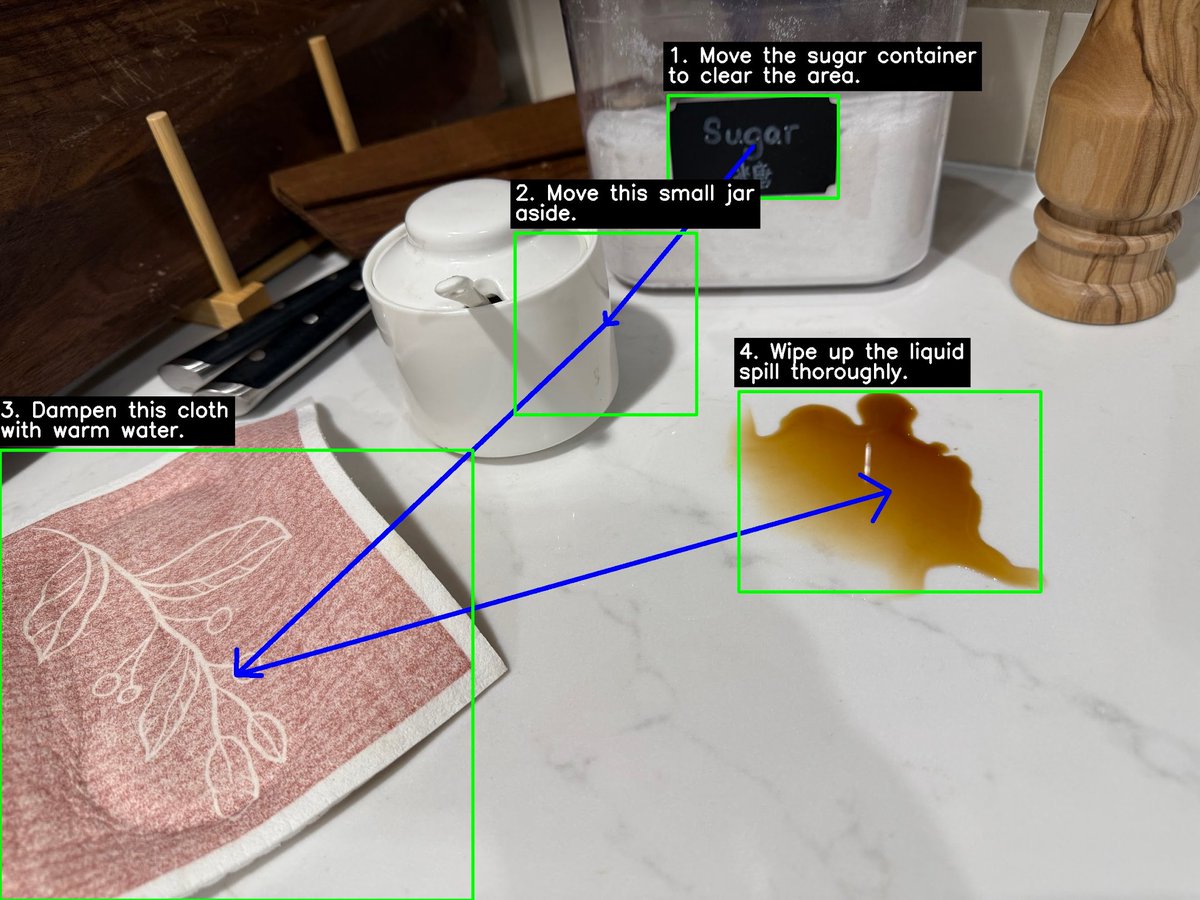
Introducing Agentic Vision with Gemini 3! 👀🔥
Gemini can now write and execute code to zoom, annotate, inspect, and plot directly with vision input, all while leveraging it's advanced reasoning capabilities
🚀 Excited to officially launch 👁Agentic Vision via Gemini 3 Flash. Gemini can run code execution on image uploads to zoom, analyze, and annotate:
🔍 Zoom: 5-10% quality win across vision benchmarks
🧮 Analyze: do image math with code (e.g. calculate the tip for a receipt)
✏️ Annotate: Draw arrows or bounding boxes to answer questions
Try via the Gemini API (AI Studio / Vertex) or via the Gemini App (rolling out to Thinking mode today).
Learn more→ https://t.co/JZtFU7fR05
Demo:
https://t.co/cXR9v1vwJo
cc: @IoanaBica95@anastasija56572@jalayrac@bcaine@eisenjulian@weichengkuo@phillip_lippe@xf1280@tulseedoshi@BiboXu@OfficialLoganK
Try 👁 Agentic Vision with Gemini 3 Flash in @GoogleAIStudio or Vertex AI. This new capability enables the model to effectively use code and reasoning to improve performance for common vision tasks.
See Agentic Vision in action: https://t.co/z0k9VG1YmQ
@marcosmarf27@OfficialLoganK can you help me better understand your entire pipeline better? what are "vision resources". Are you using another upstream system to do OCR? And are you feeding the OCR text and the PDF images into Gemini from there?
@deedydas@deedydas 👋 glad you’re a fan of the launch (I’m the Gemini multimodal vision PM) - feel free to DM if you have any feedback for the team on doc understanding
Gemini 3 Flash is insane at OCR.
It parses this extremely hard to read handwritten letter by Richard Feynman perfectly. It can do ~300 of these for $1.
What's crazy is Feynman addresses General Donald J. Kutyna as "Katyna" which Gemini gets. There is no "Meeting Katyna", the first part of the letter, in all of Google search!
@matidotlol@googleaidevs@OfficialLoganK Gemini Vision PM here! Let's chat (I'll DM you). can you share some queries+PDF examples. I'll have our team debug what's going on