@chetan_ Just to be clear, we can and are doing significantly more than pick and place with the scenes/assets created here. That's always been an emphasis for me.
I've been saying for years that the biggest challenge for simulation in robotics is not actually the physics engine (although you do have to get that right). The real challenge is capturing the *diversity* of the real world. There was no doubt that generative AI had the potential to change that, but it's still amazing to see it take shape.
Watching Nick's incredibly fast progress has convinced me that content generation might not actually be a bottleneck anymore. This is a beautiful combination of hardened tools for e.g. low-level mesh processing with the latest tools for generative asset creation, wrapped in a powerful agentic workflow. Please do give it a try and share your feedback.
Meet SceneSmith: An agentic system that generates entire simulation-ready environments from a single text prompt.
VLM agents collaborate to build scenes with dozens of objects per room, articulated furniture, and full physics properties.
We believe environment generation is no longer the bottleneck for scalable robot training and evaluation in simulation.
Website: https://t.co/UZklSkJe9V
👇🧵(1/8)
@JeremySMorgan3 We're working on and eagerly watching all of the progress in real2sim. I do think capturing particular scenes (e.g. the robot failed at a task in the field, and you want to reconstruct that in sim) is going to be very high value when we really get it right.
It's a good question. We have articulated objects.. typically the only actuated object in the scene is the robot, which we insert manually (and you want to connect that to your control stack, etc, too).
We've found that the basic friction parameters are pretty good, but I agree that this could be a nice way to further increase the fidelity.
RL training in sim has been incredibly powerful for locomotion, because it turned out that training on a handful of terrains was sufficient to generalize to the real world.
We haven't seen the same for manipulation. Open-world manipulation has, instead, been leaning on real world data collection (and imitation learning). The main reason for this, I would argue, is because we haven't captured the diversity of the manipulation problem in our simulators yet.
It's still possible that we could find a minimal set of scenarios that capture the full complexity of the dexterity of manipulation, but manipulation also requires world knowledge (e.g. pick up the mugs from the handles, etc) so you have to get that from somewhere too -- strong multimodal base models and/or imitation. Assets + physics engines are not enough.
My personal journey on this has been in Drake (https://t.co/xIwJ1HAbJD).
First step: The assets have to be good. Garbage in, garbage out. (People under estimate how low quality most assets are... even the models you get straight from robot manufacturers.)
Second step: Get the physics engine right. We've been pounding on getting better contact models (e.g. Drake's hydroelastic contact model) and stronger and stronger numerical methods for contact simulation in Drake. Alejandro's papers are a great summary of that work: https://t.co/dTgiqS2wrD
Introducing Large Video Planner (LVP-14B) — a robot foundation model that actually generalizes. LVP is built on video gen, not VLA. As my final work at @MIT, LVP has all its eval tasks proposed by third parties as a maximum stress test, but it excels!🤗
https://t.co/wjD54YFK3k
TRI's latest Large Behavior Model (LBM) paper landed on arxiv last night! Check out our project website: https://t.co/AV2cmfeX40
One of our main goals for this paper was to put out a very careful and thorough study on the topic to help people understand the state of the technology, and to share a lot of details for how we're achieving it.
https://t.co/EVFLJAY6Zu
This was a massive effort by the entire team, with a number of individuals really pouring their hearts into this paper. The paper is packed full of (too many?) details. Your comments and feedback would be very welcome.
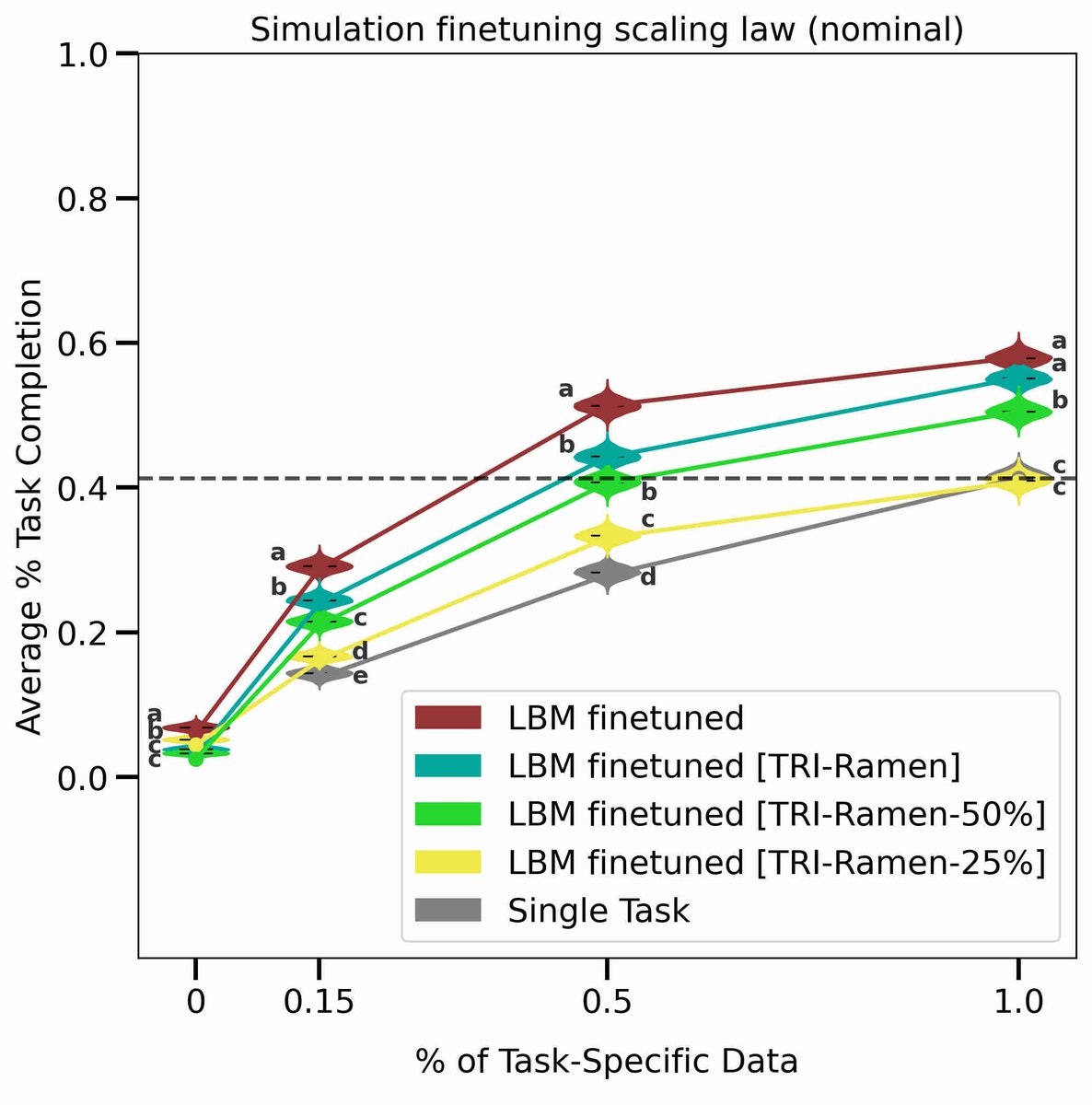
Probably my favorite plot from the paper, which sums it all up, is this one.
The plot compares performance using different amounts of pretraining data used before training a new task: 0% (aka single task), 25, 50, or 100% of TRI’s data, then 100% of TRI’s data + all of the open-source robot data (the red line) that we’ve curated. It’s just awesome that the distributions over task completion are so tight and that trends as we increase data are so consistent. The results show clearly that with pretraining, we can train a novel skill with substantially less data or use the same amount of data and get much better task performance. And the benefits appear to continue with more data.
Very proud of Nicholas, who recently shared https://t.co/JH2CL4Kfgh (for physics-quality assets from a small amount of interaction with a robot) and is now following up with his work on scene-level generation.
Want to scale robot data with simulation, but don’t know how to get large numbers of realistic, diverse, and task-relevant scenes?
Our solution:
➊ Pretrain on broad procedural scene data
➋ Steer generation toward downstream objectives
🌐 https://t.co/QQPxzIh8mB
🧵1/8
In my mind, it's a bit like a biology paper that is focused on a particular animal model. I hope we'll learn more quickly from each other if we can make precise, substantiated claims about particular setups, so that as a field we can assemble those claims into a coherent picture.
Learning from both sim+real data could scale robot imitation learning. But what are the scaling laws & principles of sim+real cotraining?
We study this in the first focused analysis of sim+real cotraining spanning 250+ policies & 40k+ evals https://t.co/hMc56Hj2K9 (1/6)
Side note: I'm proud of the title of this paper, which we intentionally made pretty narrow/specific. I think that some of the most important work that we have to do as a field right now is careful empirical work to interrogate the properties of these models that we're creating.
One of the most interesting take-aways for me is that "high-performing policies need to know whether they are executing in sim or in real." A number of implications flow from that, including that sim+real cotraining can decrease performance if the visual gap is too small.