The number of applications to the Builders Program is staggering, and the pipeline keeps growing.
Our launchpad opens SERV Reasoning to all web3 builders who launch tokens in the eco.
The most novel projects are selected for the Builders Program and spotlighted.
Next in line: Homecooked, an AI-powered app entering a multi-billion-dollar food-tech market, built on SERV.
5% of every launch is reserved for SERV stakers. Staking program coming soon.
Time to cook.
Destination is clear: SERV as the reasoning layer enterprise agents can actually run on.
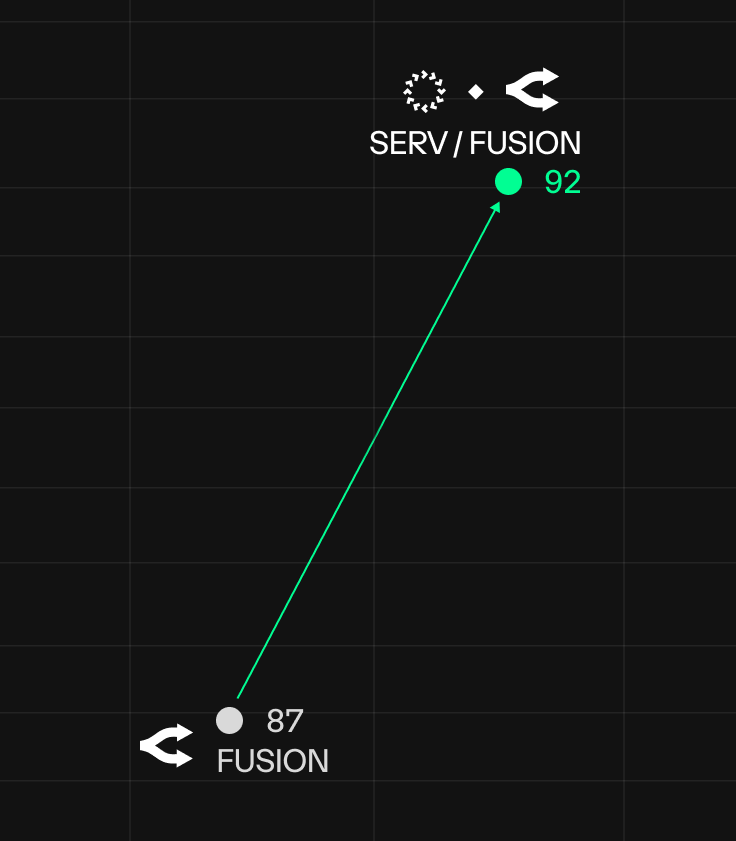
Stats show why all roads lead to SERV: on our preliminary benchmark, combining OpenRouter Fusion with SERV Reasoning led to a ~38% reduction in failures (13→8).
Fusion seems to be suited for deep research tasks rather than agentic work, and struggles with what production agents need most: reliable JSON outputs.
Even the biggest companies don't have answers for problems we're already solving. It shows why SERV is on the way to becoming a staple name in conversations shaping the future of the agentic economy.
Deeper Fusion benchmarks and results underway.
A year ago I mapped where AI space was going: reliability as the moat, security maturing, regulation landing, enterprise going mainstream.
Today US gov pulled Claude Fable offline over a jailbreak. The article kinda reads like a checklist.
Next up: trust + cost layer
The US government pulled Claude Fable today.
Good news is, you don’t need frontier models for production-grade agents.
With SERV, open-source LLMs like DeepSeek-v4 outperform Claude Fable at up to 90x cost savings.
The decentralised future is bright.
SERV is inevitable.
NVIDIA shipped a new frontier model - Nemotron 3 Ultra, and we have already integrated it with the SERV Reasoning engine.
The base model scored 79.61 on our standard DeFi benchmark. Armed with SERV, it jumped to 90.78.
Thats +11.17 points gain.
SERV makes all models smarter.
Several SERV Reasoning-armed agents just beat Anthropic's Fable, one of the strongest LLMs ever built, at up to 90x lower cost.
That result comes from using SERV Reasoning with DeepSeek-v4-Flash on our DeFi benchmark. Thanks to the SERV engine, agents running on smaller models perform better than those using frontier, expensive ones.
Here is more information about the benchmark behind that result, what it tests and why it is built the way it is.
Why a DeFi benchmark
Autonomous trading is one of the harshest tests of machine reasoning.
An agent reads live market state, portfolio state, and a strict risk policy, then has to commit to one of four actions: BUY, SELL, HOLD, or BLOCK. A wrong decision costs real money.
No room for reasoning sounds smart but lands on the wrong trade, which makes it the ideal domain for measuring whether a model actually follows rules under pressure rather than just explaining them well.
What the scenarios target
Each scenario combines a market snapshot, portfolio size, trading signal, and a fixed risk policy, and falls into one of three families:
- clear constraint violations the agent must refuse
- ambiguous setups where everything looks tradeable but the conditions say wait
- valid trades where the agent must size the position correctly within caps
This mirrors how trading agents actually fail in production. Rarely on the obvious cases, almost always on the judgment calls.
How it is scored
The benchmark follows the same conventions as the agentic evals in the latest frontier model reports, including τ²-bench and Terminal-Bench:
- outcome-verified scoring, where code checks the final decision against the risk policy, with no LLM judges
- identical prompt, scenarios, and settings for every model
- zero-shot, with no scaffolding, no retries, and no few-shot examples
- repeated runs per scenario, so consistency is measured alongside accuracy
- cost computed from real token usage at list prices, per run
Why this is exactly where reasoning matters
This task has the three properties structured reasoning is built for: hierarchical rules, multiple data sources that must be reconciled, and a verifiable correct answer.
SERV's bounded reasoning keeps a model moving through that hierarchy step by step, instead of letting it talk itself into a bad trade.
That is why SERV-routed models clear the same quality bar as flagship models at a fraction of the cost, and why the gap shows up most on the judgment calls.
SERV Reasoning Private Beta is accelerating and a new batch of builders is coming on board, pulling the next ones in.
The pattern holds:
• Lower costs
• 100% reliability
• Faster than their old stack
Here are a few recent additions to the program.
-> Apply to join now 👇
SERV Reasoning rollout is moving faster than anticipated.
We have been swamped with interest from agent builders and enterprises hoping to embed the reasoning into their agents.
Where we are right now:
Phase 1 (done): Private beta rolling out to selected teams.
Phase 2 (next up): Public API, self-serve onboarding.
Phase 3: SERV-native fine-tuned models
Phase 4: Purpose-built SERV model from scratch
Phase 5: maLLM - morpheme-aware LLM
Every team gives us feedback on how SERV Reasoning performs against real-world problems.
This is the first step.
Together with NEOL, we’ve begun deploying SERV Reasoning into real government-grade AI workloads, already live with the UAE government.
NEOL uses AI agents to surface the right people, relationships, and institutional knowledge for governments and large institutions making high-stakes decisions.
For that to work, “usually right” isn’t enough.
The agent needs to be reliable, reproducible, and auditable.
SERV Reasoning enabled NEOL to move from brittle prompt-based agents to structured reasoning graphs their team can inspect, test, and improve systematically, reaching 100% accuracy on key production agents.
That matters because when a government client asks why a certain person was recommended, NEOL can now point to the reasoning structure behind the decision.
Not a black box.
Not a guess.
A traceable decision process.
This is the beginning of something much larger.
Every enterprise, government, and public institution trying to deploy AI into serious workflows will run into the same wall: agents that are too unreliable, too opaque, and too difficult to audit.
That is exactly the wall SERV Reasoning was built to break through.
Our aim is to keep expanding what we unlock with NEOL, deepen the relationship across more institutional use cases, and bring this same reasoning infrastructure to the enterprises and governments that need AI they can actually trust in production.
The future of institutional AI cannot run on todays infra, it needs specialized AI reasoning that can be tested, audited, reproduced, and trusted.
That is the institutional gap SERV is plugging.
You guys know I’m a ethereum:0x40e3d1a4b2c47d9aa61261f5606136ef73e28042 maxi.
Hell I even coined the motto “Never Sell $SERV”.
That being said, in my search to have exposure to every facet of Ai in my company balance sheet, I’ve been digging into new sectors and aspects of Ai.
$SERV gives me great exposure to cost and reliability, but what about security and privacy.
Well after hours and hours of research, I think I’ve found the exposure to those areas of Ai with massive growth potential.
This project has an absolute cracked and award winning Dev. A super powered team, and has even quietly built out a strong ass community.
They’ve already started pitching security and privacy to large enterprises and I have no doubt this will project will accelerate.
Add super fair tokenomics and massive revenue growth potential, I see no reasons billions aren’t possible!
So I’m creating a second wallet and moving size into this project! I hope you guys dig in and do the same!
I believe this is massive.
Project link in the comments!
New feature: Prompt Guard
Every builder knows prompt injection is a big threat to production agents.
That's why we are introducing Prompt Guard, which solves the problem for every user by default.
• 3 layers of defense by default
• 256 attack vectors tested, zero leaks, zero false positives
The next era of AI infrastructure comes with security baked in as default. SERV is already shipping it.
With the early success of SERV Reasoning in private beta, we are accelerating adoption across two strategic domains.
Larger institutions. Global scale.
This week, our leadership team is in Nairobi meeting with some of the largest banks in the region. Conversations are taking place inside executive boardrooms at Tier 1 institutions with over $7 billion in collective assets under management, with heads of corporate credit, IT, and risk among the participants.
East Africa is the fastest-growing credit market in the world, and Kenya sits at the center of it. As banks across emerging markets look to adopt AI, the opportunity is clear. Major bottlenecks and outdated processes are waiting to be solved, and the institutions that solve them will define how credit operates in the next decade.
For financial institutions, AI adoption only happens when the technology clears a specific bar. Auditable outputs. Reliable performance. Sustainable cost. Most previous attempts at AI integration in this space have stalled on one of those three, often on all of them.
SERV Reasoning was built for exactly this category of buyer. The institutions that cannot afford to be wrong on reliability, cannot afford to be wrong on cost, and require auditability at every step.
Product is only one side of enterprise adoption. Distribution is the other. In financial services, particularly in emerging markets, sales cycles are long, trust is earned through relationships, and adoption depends on being in the right rooms with the right stakeholders.
This is why being on the ground matters. SERV is being positioned not just as a product but as the reasoning layer the next generation of global financial institutions will run on.
The infrastructure layer for enterprise AI is being built in the rooms where the decisions get made.
Another piece of the SERV stack just got externally validated.
Raison won both Jury & Audience awards at Cambridge Innovation Center’s Agentic AI Revolution event.
Built by our CTO @dashersw, it’s an advanced prompt management layer used by SERV and our enterprise customers.
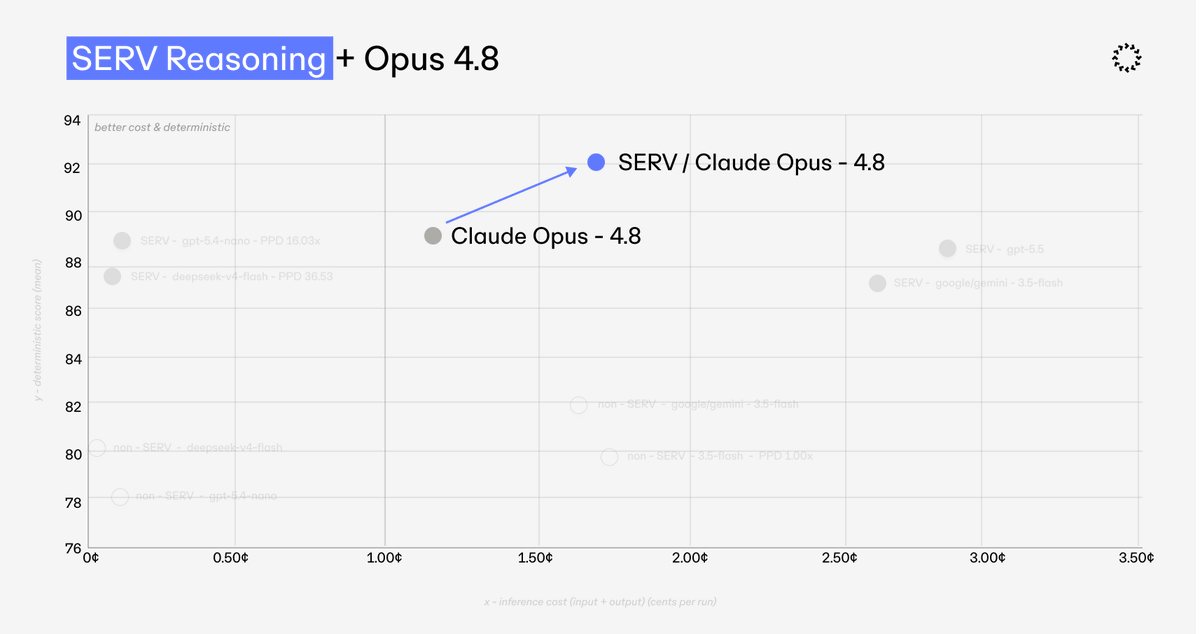
Claude 4.8 just went live and it's now integrated with SERV Reasoning.
Smarter and more reliable - making it ready for enterprise use.
Armed with SERV, it scores 92.56 on our DeFi benchmark.
Now available to Private Beta builders.
Wow. Agents running on Claude, Gemini, OpenAI are reliable only 20-30% of the time, according to CHI-Bench from actAVA.
But - you don't need better models. You need better reasoning. Once you arm them with SERV, reliability jumps instantly to 90-100%!
https://t.co/YY8YB3bJEn