Four of our industrial #PhD students, @SBejgu, @PereLluisHC, @alescire94 and @SimoneTedeschi_, were awarded their #PhD in #AI last Friday with the best grades (and two cum laude)! Congrats all! 👏 🎉 With @RNavigli, their advisor and Babelscape's scientific director, in the photo
@rohanpaul_ai Thank you for highlighting our work! 🙌
You can explore the training and evaluation datasets on Hugging Face here: https://t.co/cuitPI7SGl.
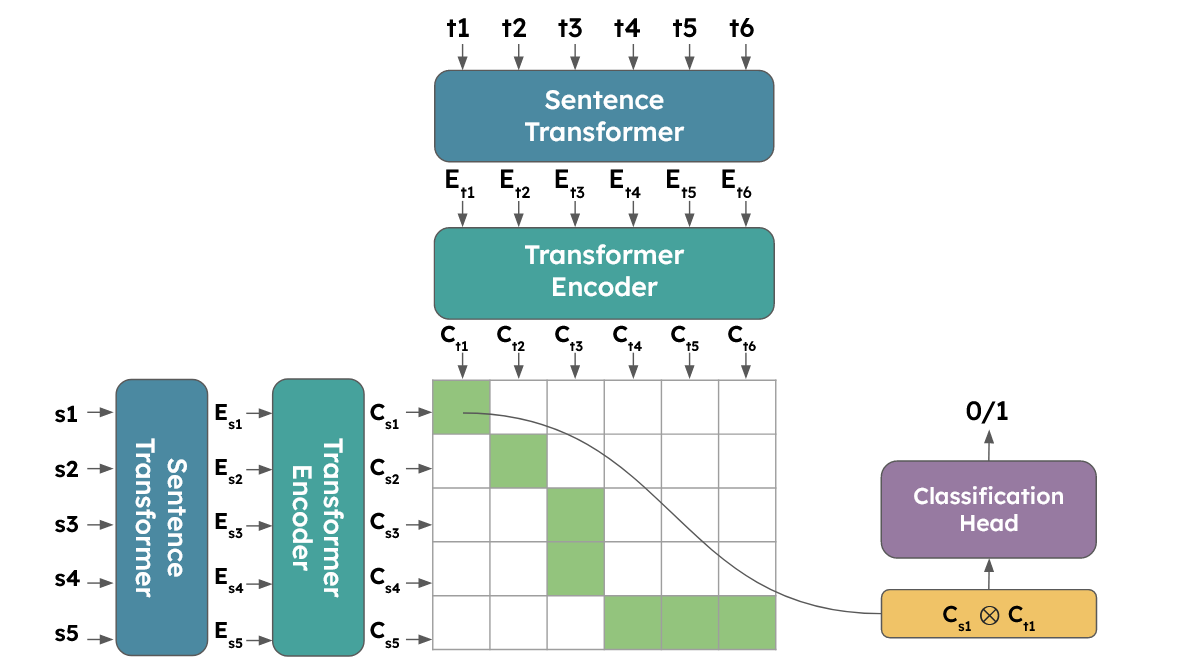
Want to know if an AI is lying? LLM-OASIS helps detect factual accuracy in AI outputs with 81k training examples.
LLM-OASIS introduces the largest dataset for training factuality evaluators, created by extracting and falsifying information from Wikipedia articles. This enables end-to-end verification of AI-generated text accuracy.
-----
🤔 Original Problem:
LLMs still produce hallucinations in their outputs. Existing factuality evaluation resources are limited by being task-specific, small in size, or focused only on simple claim verification.
-----
🔧 Solution in this Paper:
→ LLM-OASIS extracts claims from Wikipedia passages using an LLM-based pipeline.
→ The system falsifies selected claims by introducing subtle but critical factual errors.
→ It generates pairs of factual and unfactual texts based on the original and modified claims.
→ The dataset covers 81k Wikipedia pages with 681k claims for training factuality evaluators.
-----
💡 Key Insights:
→ Task-agnostic factuality evaluation is possible with a large-scale synthetic dataset
→ Wikipedia provides reliable source material for generating factual/unfactual pairs
→ Human validation confirms high quality of automated data generation (90%+ accuracy)
-----
📊 Results:
→ GPT-4 achieves 60% accuracy on end-to-end factuality evaluation
→ 68% accuracy with Retrieval Augmented Generation
→ Human validation shows 96.78% accuracy for claim extraction
→ Dataset creation pipeline maintains 89-98% accuracy across all steps
✨ Meet #ResiDual, a novel perspective on the alignment of multimodal latent spaces!
Think of it as a spectral "panning for gold" along the residual stream. It improves text-image alignment by simply amplifying task-related directions! 🌌🔍
https://t.co/UuXoYBBsT5
[1/6]
✨Tired of verifying #AI-generated info?😵
🔎Meet Vera, our #LLM-based fact-checker using trusted sources from the Web or your knowledge base.
💥Check out the live demo at Rome #MakerFaire2024 (Oct 25-27)!
More info 👉: https://t.co/OxrZ63rIbK
#FactChecking#Misinformation
🔵🔴When do distinct learning processes learn similar representations?
Detecting patterns and conditions for this to happen is an open direction: a thread🧵
Working on this topic? Submit at: https://t.co/TjAbJcpAFk
DEADLINE: 20 Sept
See you at @NeurIPSConf! 🔵🔴
[1/N]
Exciting strides in text summarization with LLMs 🚀but verifying their factual accuracy is still an open challenge 🤔 We introduce FENICE, a factuality-oriented metric for summarization with a strong focus on interpretability🔍https://t.co/jjEI6lbxzG
#NLProc#LLMs#Factuality
📢Happy to share that "Neuralign: A Context-Aware, Cross-Lingual and Fully-Neural Sentence Alignment System for Long Texts" has been accepted to #EACL2024 (main)
🫂Huge thanks to my co-authors @SBejgu@SimoneTedeschi_@ConiaSimone@RNavigli
📃More details coming soon! #NLProc
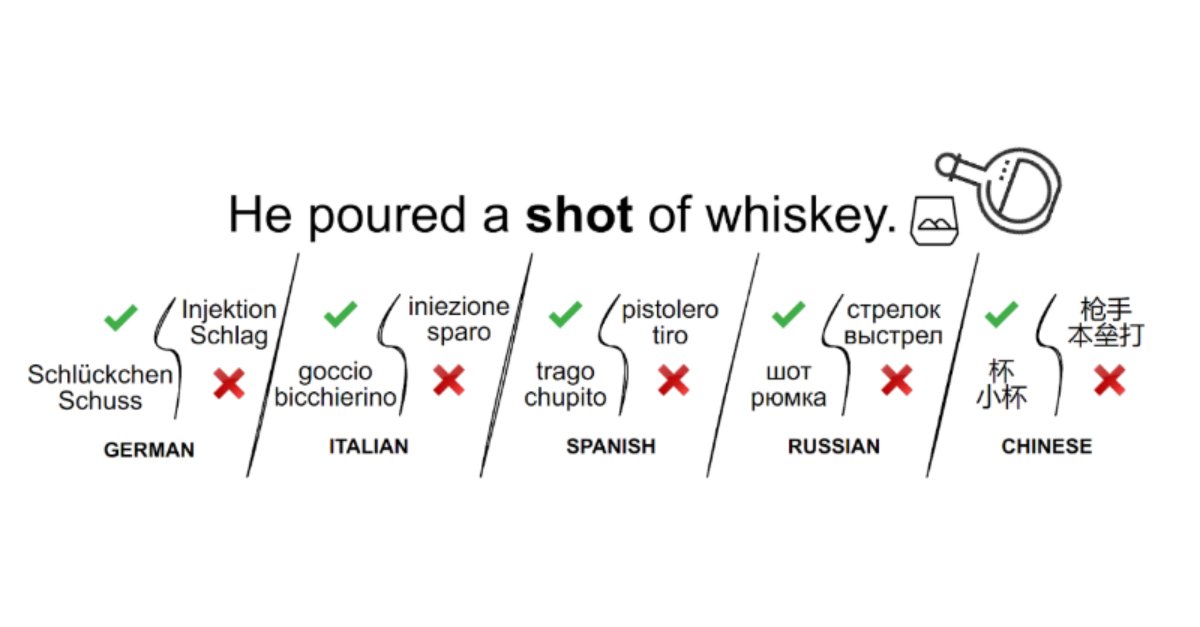
How to Mitigate Hallucinations in Large Language Models (#LLMs)?🤔
In this new @Medium article, I review the most recent research on mitigating hallucinations, and explain the main methods that are used to address this issue.
📑 https://t.co/R5c8JViYbg
#AI#NLP#GPT4#LLM
📢 It looks like relative representations are here to stay!
I'm beyond thrilled to announce that our work has been selected as one of the notable top 5% (oral) papers at #iclr23 ! 🥳
https://t.co/nlZBiaIMHZ
[1/5]
The Rome Workshop on 10 Years of #BabelNet & Multilingual Neurosymbolic Natural Language Understanding was a great success, with productive in-person discussions, amazing talks & >100 online participants! Thanks!
@ERC_Research@Babelscape@SapienzaNLP@SapienzaRoma@WikiResearch
Empower your natural language applications with WordAtlas!
#WordAtlas is the next-generation multilingual knowledge graph. What makes it special is its linkage between words and concepts in hundreds of languages.
https://t.co/hIWZaCB6EP
Classy is a @PyTorch-based library for the fast prototyping and sharing of deep neural network models.
It wraps the best libraries like PyTorch Lightning, Transformers, @streamlit and offers them to users with a simple CLI interface.
Try it here: https://t.co/BM6nXI1aUc


















![ValeMaiorca's tweet photo. ✨ Meet #ResiDual, a novel perspective on the alignment of multimodal latent spaces!
Think of it as a spectral "panning for gold" along the residual stream. It improves text-image alignment by simply amplifying task-related directions! 🌌🔍
https://t.co/UuXoYBBsT5
[1/6] https://t.co/z75Vd7iQYs](https://pbs.twimg.com/media/GbirFHEXcAALYcg.jpg)




![unireps's tweet photo. 🔵🔴When do distinct learning processes learn similar representations?
Detecting patterns and conditions for this to happen is an open direction: a thread🧵
Working on this topic? Submit at: https://t.co/TjAbJcpAFk
DEADLINE: 20 Sept
See you at @NeurIPSConf! 🔵🔴
[1/N] https://t.co/9oTc1qdZuh](https://pbs.twimg.com/media/GW879ZLWsAAT1bP.jpg)