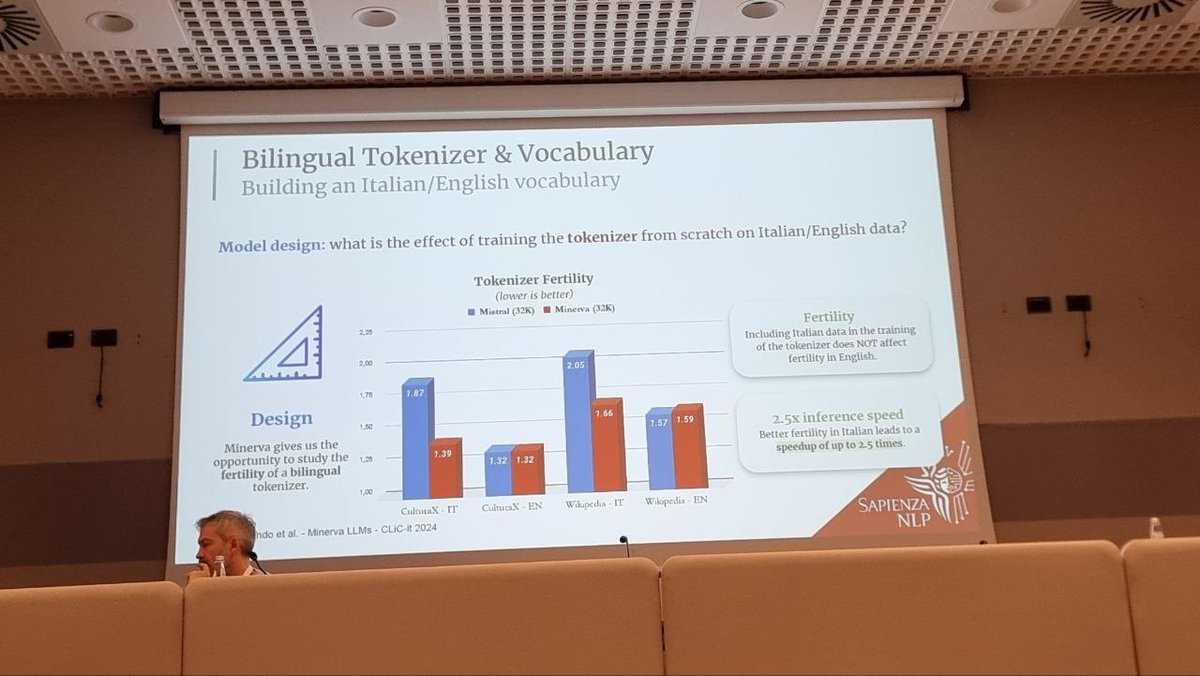
🚀Along with our presentation #CLiCit2024, we've just released the Minerva 7B Base and Instruct models on Hugging Face!
🤗https://t.co/e9lxJI1Wsg
🤗https://t.co/LR3p7TBpu2
All info here: 🖥 https://t.co/0BTSDcE4hX
Try the instruct model👉 https://t.co/R4Y4kTEfBK @CLiC_it_conf
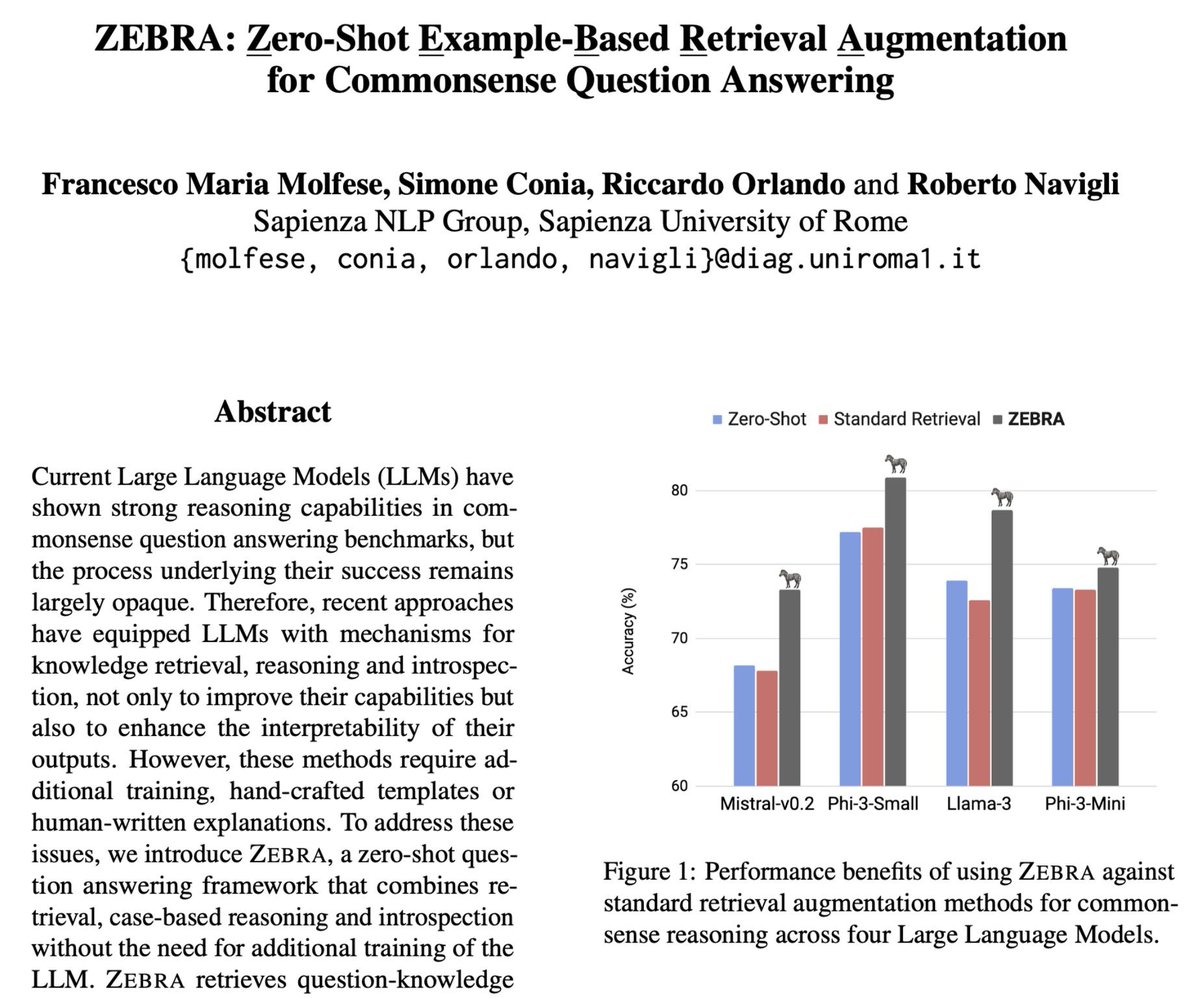
🎉 Exciting news! Our paper, "ZEBRA: Zero-Shot Example-Based Retrieval Augmentation for Commonsense Question Answering", has been accepted to #EMNLP2024!
✍️ Work conducted with @ConiaSimone, @RiccardoRicOrl and @RNavigli at @SapienzaNLP
👀 Paper, data and models coming soon!
👀 Exciting News! 👀
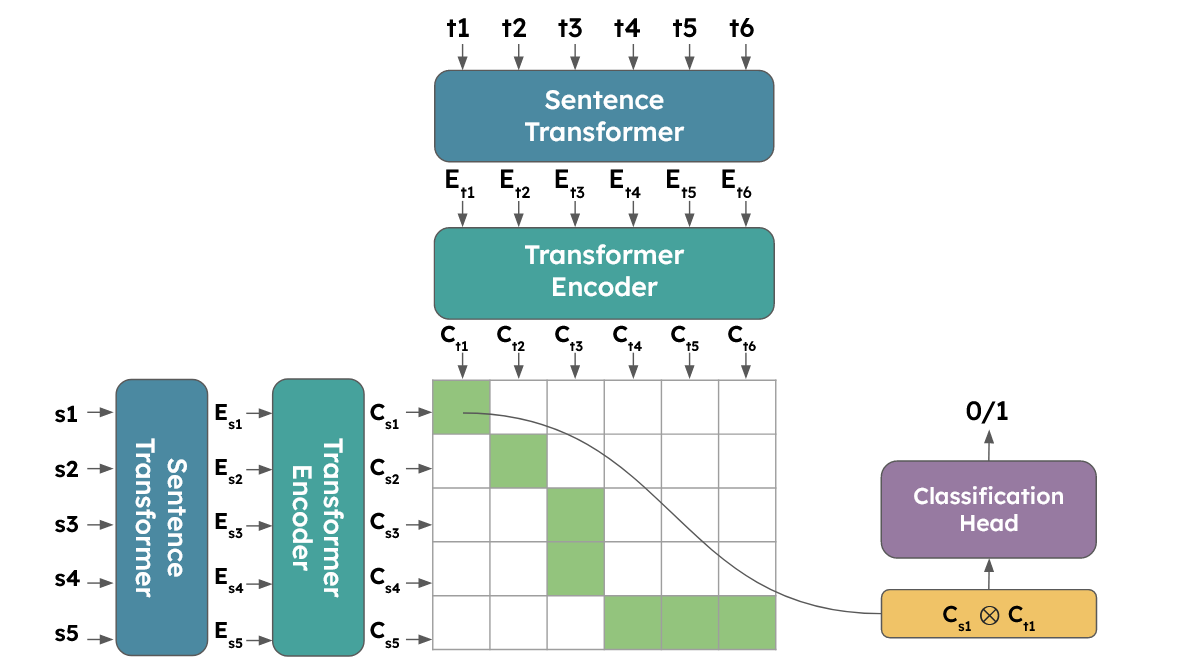
Happy to announce our latest research paper, “Retrieve, Read and LinK: Fast and Accurate Entity Linking and Relation Extraction on an Academic Budget”, will be presented at #ACL2024! 🚀
Try it out! https://t.co/xJzHlNfEzA
Thread below 👇
@ReviewAcl Are you going to remind reviewers of the short response period today? Since authors were encouraged to reply before the 28th, it would be good to remind reviewers today that only two days are left to reply.
Our paper "CroCoAlign: A Cross-Lingual, Context-Aware and Fully-Neural Sentence Alignment System for Long Texts," a joint work with @SapienzaNLP, has just been presented at #EACL24! See you there! 📝🌐 #NLP#NLProc#Research https://t.co/ywiBtXOG8C
Join us today at #EACL2024 for our presentation entitled “CroCoAlign: A Cross-Lingual, Context-Aware and Fully-Neural Sentence Alignment System for Long Texts” in the Sentence-level Semantics track! #NLProc
(Radisson Blu, Carlson Ballroom, 5th floor, Malta)
📢Happy to share that "Neuralign: A Context-Aware, Cross-Lingual and Fully-Neural Sentence Alignment System for Long Texts" has been accepted to #EACL2024 (main)
🫂Huge thanks to my co-authors @SBejgu@SimoneTedeschi_@ConiaSimone@RNavigli
📃More details coming soon! #NLProc
Our multilingual model for NER has more than 100K monthly downloads on @huggingface! 🤗 🎉
It's based on WikiNEuRal and it is trained on 9 languages jointly ✨
🔗 Model: https://t.co/oZs2IOjYeA
🔗 Dataset: https://t.co/XqPVH1e9Tb
🔗 Paper: https://t.co/twvzvzGxCE
#NLProc
I am very happy to present the multilingual expansion of REBEL at #ACL2023. This work has been a year-long effort to try and provide datasets and models that enable high-quality multilingual Relation Extraction on par with English.