🎉 Congrats to @ziqiao_ma on receiving the Towner Prize for Outstanding PhD Research! 🏆 His work in grounded language, embodied AI, and human-AI interaction is pushing the field forward.
Full story: https://t.co/6m9KSnLMrv
#AI#MachineLearning#UMich#CSE
Robot memory methods are growing fast, but systematic evaluation is largely lacking. 📉
Introducing RoboMME: a new benchmark for memory-augmented robotic manipulation! 🤖🧠
Featuring 16 tasks across temporal, spatial, object, and procedural memory
🔗 https://t.co/4ELtnhDwrt
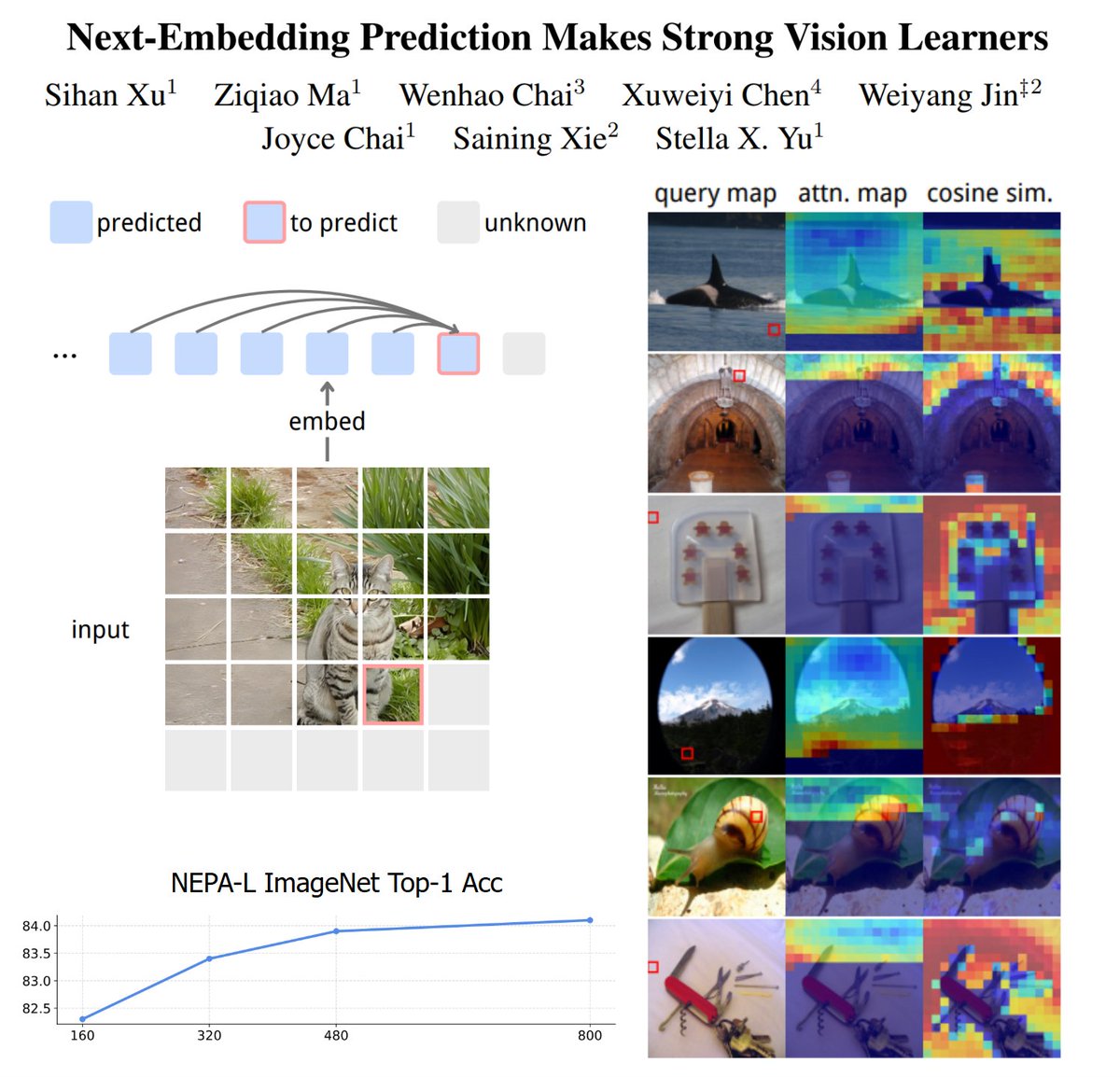
NEPA: Next-Embedding Predictive Autoregression
A simple objective for visual SSL and generative pretraining. Instead of reconstructing pixels or predicting discrete tokens, we train an autoregressive model to predict the next embedding given all previous embeddings.
Key ideas:
- One self-supervised signal: cosine-style next-embedding prediction
- Autoregression runs directly on the embeddings from a native encoder (no offline encoder)
- No pixel decoder (and loss), no contrastive pairs, no task-specific heads, no random masks
Scales into modern ViT backbones and stays competitive after supervised fine-tuning:
- ImageNet-1K (Base 83.8%; Large 85.3%)
- ADE20K
Fully open-sourced with reproducibility verified:
- Homepage: https://t.co/9SoEshkeiO
- Paper: https://t.co/gwILijFBDQ
- Code: https://t.co/GaAWvK4tQT
- Weights: https://t.co/pTNAMtVPwf
This work is led by @6SihanXu and advised by @SLED_AI, @sainingxie, and Stella X. Yu. Contributors: me, @wenhaocha1, @ChenXuweiyi, and @JinWeiyang18434.
The first workshop on Computational Developmental Linguistics, collocated with ACL 2026, is welcoming submissions! Topics of interest include but are not limited to computational methods for developmental linguistics and language model learning dynamics.
Program details below:
Here's how to babysit a language model from scratch!
Research by @ziqiao_ma, Zekun Wang & Joyce Chai shows that interactive language learning with teacher demonstrations and student trials, can facilitate efficient word learning in language models:
https://t.co/nmhheDXjIa
🚨 Excited to share SketchVerify — a framework that scales trajectory planning for video generation.
➡️ Sketch-level motion previews let us search dozens of trajectory candidates instantly — without paying the cost of the time-consuming diffusion process.
➡️ A multimodal physics+instruction verifier filters out bad trajectories, so only the best trajectory plan makes it to generation.
➡️ The final videos show far more natural, physically-coherent motion, achieved through fast, scalable test-time planning.
🧵[1/6]
Will be at #NeurIPS2025 (San Diego) Dec 1-9, then in the Bay Area until the 14th. Hmu if you wanna grab coffee and talk about totally random stuff.
Thread with a few things I’m excited about.
P.S. 4 NeurIPS papers all started pre-May 2024 and took ~1 year of polishing...so proud of the team!
Still wrapping up a few reality-check experiments and polishing the tutorial structure ... but we're excited!
P.S. Sadly the ARC-AGI team can't join the tutorial panel this time due to conflict of schedule, but they’ll be with us at the @LAW2025_NeurIPS later in the NeurIPS program. Stay tuned :)
I’ve always wanted to write an open-notebook research blog to (i) show the chain of thought behind how we formed hypotheses, designed experiments, and articulated findings, and (ii) lay out all the intermediate results that did not make it into the final paper, including negative ones that we believe others will find interesting.
https://t.co/h7jb0Kr03w
So @fredahshi and I wrote about grounding, a topic that sparks a lot of debate, both in VLM engineering and in linguistics and philosophy. Our latest work shows from a mechanistic interpretability perspective that symbol grounding can naturally emerge from mid-layer aggregate heads, without requiring fine-grained supervision or any special architectural inductive bias.
Feel free to check it out. We tried to find a balance between open-notebook transparency and readability. It looks best on desktop since I gave up on engineering that CSS file.😅
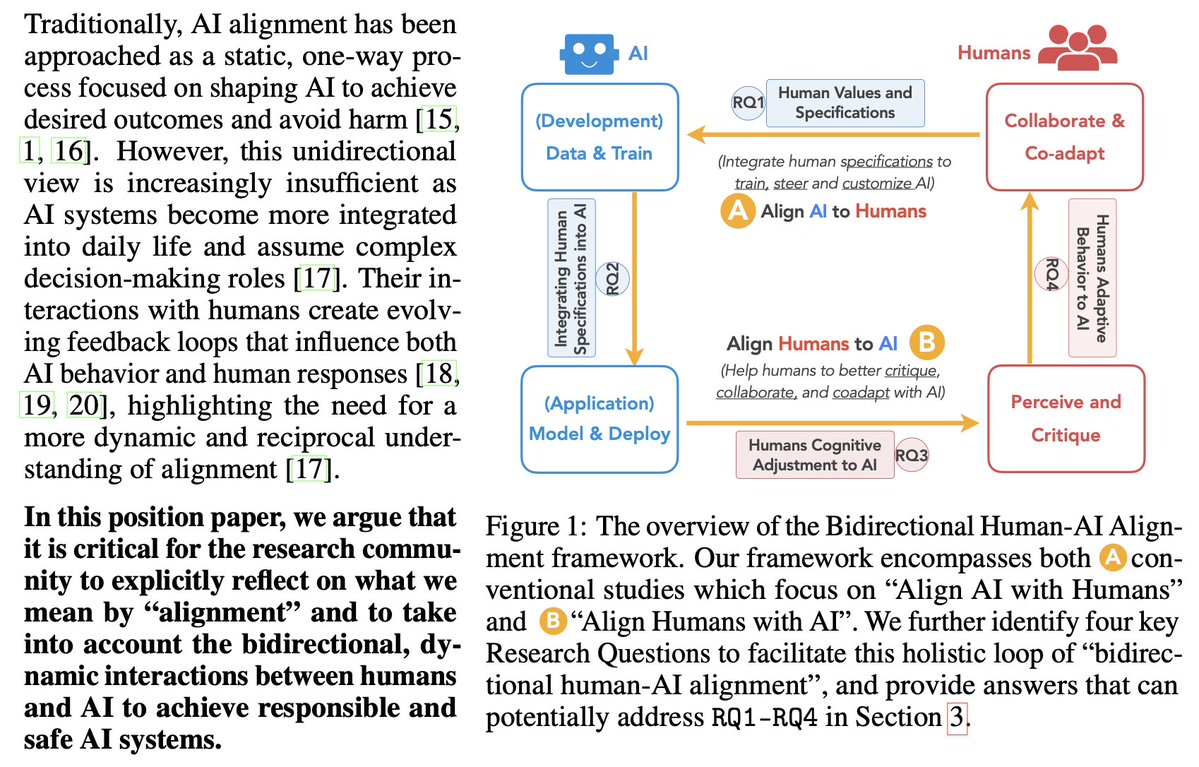
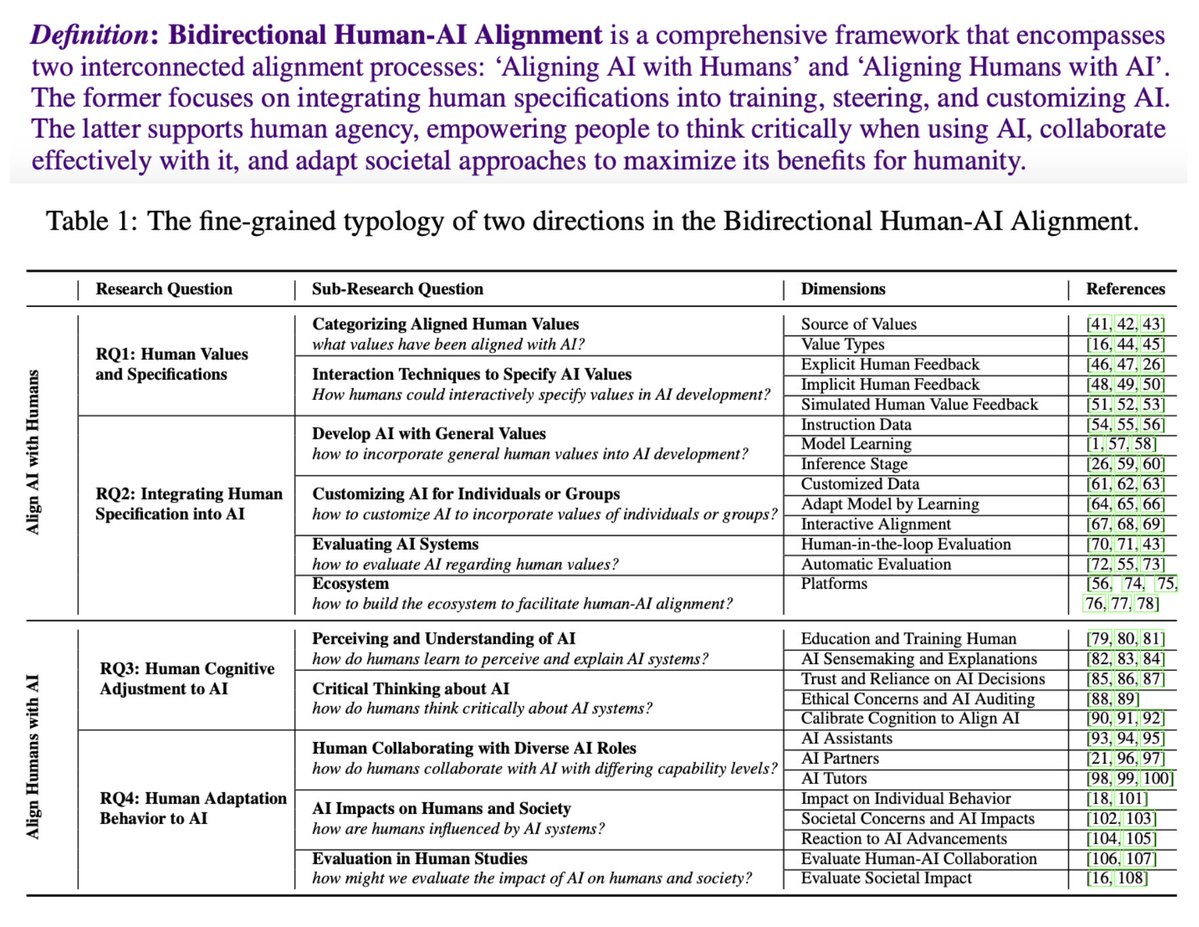
Thrilled to share that our paper “Towards Bidirectional Human-AI Alignment” has been accepted to #NeurIPS2025 (Position Track)! 🎉
👫<>🤖We argue for an explicit reflection on what we mean by “alignment”, and to take into account the bidirectional, dynamic interactions between humans and AI to achieve truly responsible and safe AI systems.
🧠+ if you’re generally interested in “alignment”, don’t miss our #NeurIPS2025 Tutorial on “Human-AI Alignment: Foundations, Methods, Practice, and Challenges” , with amazing @mitchellgordon & @adamfungi — more details coming soon!
- 💎 NeurIPS 2025 Position Paper: https://t.co/VAATH8nDJS
- 📚 NeurIPS 2025 Tutorial: https://t.co/dPsfUKjT1y
💗 Huge thanks to our incredible co-authors — this was our 3rd resubmission — your persistent support and encouragement made it happen! Big thanks to everyone in our ICLR & CHI 2025 BiAlign workshops — your enthusiasm keeps us believing we’re doing something right for our community.🙏
☕️👯♀️I’m attending #COLM2025 at Montreal this week, happy to chat more if you’re around! Also, we (w/ multiple co-authors) will present our #BiAlign paper in-person @SanDiego -- catch us at #NeurIPS2025, we’d love to hear your thoughts and join discussions!
Excited to share 2 papers from SLED at #COLM2025:
- Bootstrapping Visual Assistant Modeling with Situated Interaction Simulation.
- Vision-Language Models Are Not Pragmatically Competent in Referring Expression Generation.
Come talk to us at the poster sessions!
Over the past few months, I’ve heard the same complaint from nearly every collaborator working on computational cogsci + behavioral and mechanistic interpretability:
“Open-source VLMs are a pain to run, let alone analyze.”
We finally decided to do something about it (thanks @fredahshi@jzhou_jz for initiating and co-leading this).
VLM-Lens (to appear in #EMNLP2025 demo) is a toolkit for systematically analyzing and interpreting open-source VLMs.
[Code] https://t.co/r6nQLWBYzg
[Paper] https://t.co/52mBTBufS7
VLM-Lens abstracts away model-specific complexity and gives you fine-grained access to any internal representation across 16 VLMs and their 30+ variants. It is built on these simple principles:
1. Unified access: consistent API across all models
2. YAML-configurable: minimal model-specific code needed
3. Extensible: add new models in a few lines
4. Interpretability-ready: plug into probes, PCA (more under dev)
Let’s make VLM research a little easier to see through. :)
Thanks @_akhaliq for sharing our work!
Aim and Grasp! AimBot introduces a new design to leverage visual cues for robots - similar to scope reticles in shooting games.
Let's equip your VLA models with low-cost visual augmentation for better manipulation!
https://t.co/bSXPzml51B
Thanks @_akhaliq for posting our work! And I'm happy to share that AimBot 🎯 is accepted to CoRL 2025 @corl_conf! See you in Seoul!
Project webpage: https://t.co/9YR9ialqNw
Thanks to my amazing co-lead @YinpeiD, co-authors, and our advisors @NimaFazeli7, @SLED_AI
Excited to announce the #NeurIPS2025 Workshop on Bridging Language, Agent, and World Models for Reasoning and Planning (LAW)
https://t.co/RTA0xqsknf
The LAW 2025 workshop brings together Language models, Agent models, and World models (L-A-W). It aims to spark bold conversations around whether LLMs possess internal world models, how we can build more grounded and generalizable agents, and what it takes to go beyond today’s capabilities.
Huge thanks to our amazing co-organizers and speakers, and to @LambdaAPI for generously sponsoring us! Join us at LAW 2025 as we chart the future of AI systems that can reason, act, and adapt in complex, ever-changing environments.
Excited to be in Vienna for #ACL2025! We will present 1 poster and 1 oral. Come say hi if you're around! 👋
📌Poster (Tutoring Agents)
🗓️Monday, July 28 18:00–19:30 | 📍Hall 4/5 (Session 5)
📌Oral (Safety Mechanisms)
🗓️Wednesday, July 30 09:00–10:30 |📍Room 1.85 (Session 11)
























![ziqiao_ma's tweet photo. Over the past few months, I’ve heard the same complaint from nearly every collaborator working on computational cogsci + behavioral and mechanistic interpretability:
“Open-source VLMs are a pain to run, let alone analyze.”
We finally decided to do something about it (thanks @fredahshi @jzhou_jz for initiating and co-leading this).
VLM-Lens (to appear in #EMNLP2025 demo) is a toolkit for systematically analyzing and interpreting open-source VLMs.
[Code] https://t.co/r6nQLWBYzg
[Paper] https://t.co/52mBTBufS7
VLM-Lens abstracts away model-specific complexity and gives you fine-grained access to any internal representation across 16 VLMs and their 30+ variants. It is built on these simple principles:
1. Unified access: consistent API across all models
2. YAML-configurable: minimal model-specific code needed
3. Extensible: add new models in a few lines
4. Interpretability-ready: plug into probes, PCA (more under dev)
Let’s make VLM research a little easier to see through. :)](https://pbs.twimg.com/media/G2W1GKWXoAAuy32.jpg)































