Sycophancy, disempowerment, homogenization of thought: lots to be grim about for what AI is doing to us, the collapse of our subjectivity into a machine "objectivity". But a lot of AI's value seems to come precisely from scaling this objectivity. How do we make sense of this?
“Should I fear death?” Ask an LLM and you get one answer or a big bag, but little visibility into the decisions and assumptions that produced them. We built the "conceptual multiverse": a system that makes those decisions transparent and intervenable. https://t.co/oQlWs0KFHu
recently, i’ve been thinking about ways to design ai systems to be more compatible with slow thinking 🐌.
you can check out the full blogpost here 🤗:
https://t.co/3hdYCIpuoN
Last day to apply to the OpenAI safety fellowship! It’s a chance to work with some of my favorite people on some of the most important, interesting, and consequential questions in AI
MIT postdoc opportunity! We're hiring a human-AI interaction postdoc (HCI+ML/RL) to train agents that deepen how people think and collaborate - rewarded by how humans actually build skill together. With @arvindsatya1@ZanaBucinca, me & more! Apply by May 1 https://t.co/1jUhnwwlIx
Introducing the OpenAI Safety Fellowship, a new program supporting independent research on AI safety and alignment—and the next generation of talent.
https://t.co/vAQKvf8KyO
🚨MIT Postdoc Opportunity!
We're looking for someone with an HCI+ML/RL background to work with us on agents that promote metacognition and sociality—trained with ethnographic rewards!
w/@mitchellgordon,@zanabucinca & colleagues in sociology+anthropology
https://t.co/hhfpgiv6If
MIT postdoc opportunity! We're hiring a human-AI interaction postdoc (HCI+ML/RL) to train agents that deepen how people think and collaborate - rewarded by how humans actually build skill together. With @arvindsatya1@ZanaBucinca, me & more! Apply by May 1 https://t.co/1jUhnwwlIx
I’m looking for someone who’s excited to be on the operational end of AI safety research problems. This role sits at the intersection of research and execution: working with academic researchers, 3p evaluators, and internal partners to help shape AI safety in practice.
We’re committing $7.5M to @AISecurityInst’s Alignment Project to fund independent research on mitigations for safety and security risks from misaligned AI. https://t.co/PbUoNUcBzY
New on the OpenAI alignment blog!
We prototype a method for eliciting the values that drive preferences over model responses, and release CoVal, an experimental dataset we built with it.
Details in thread 👇
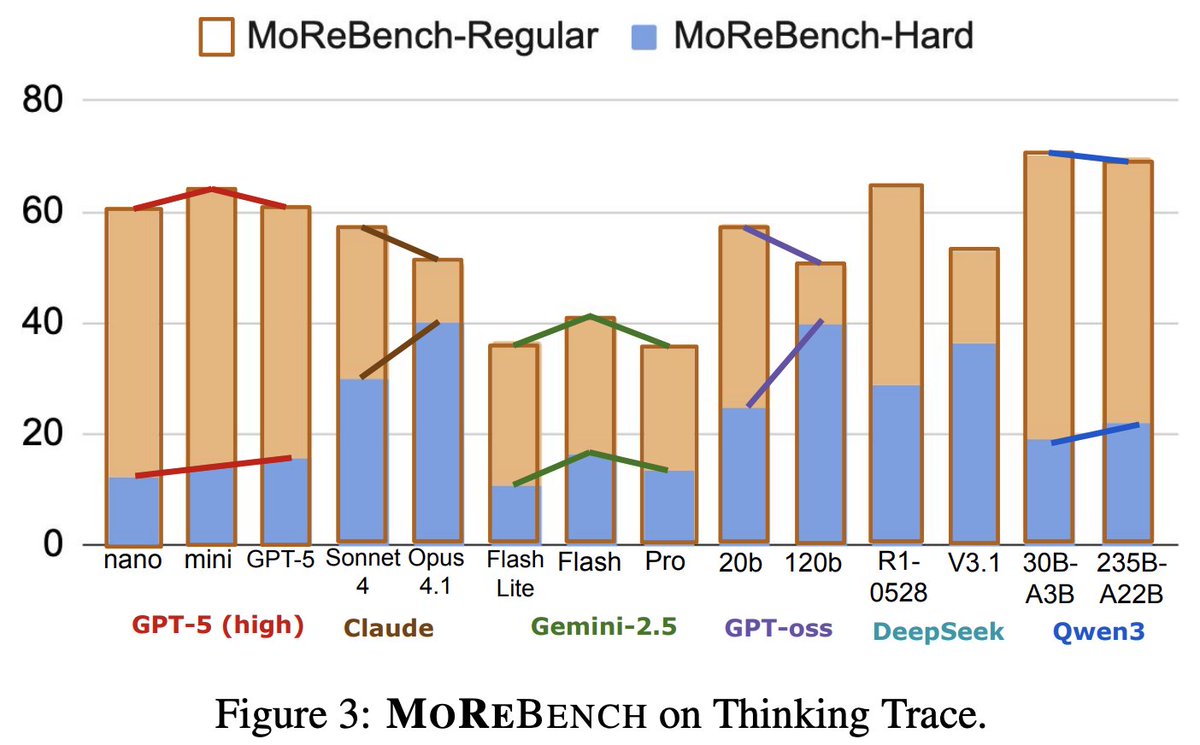
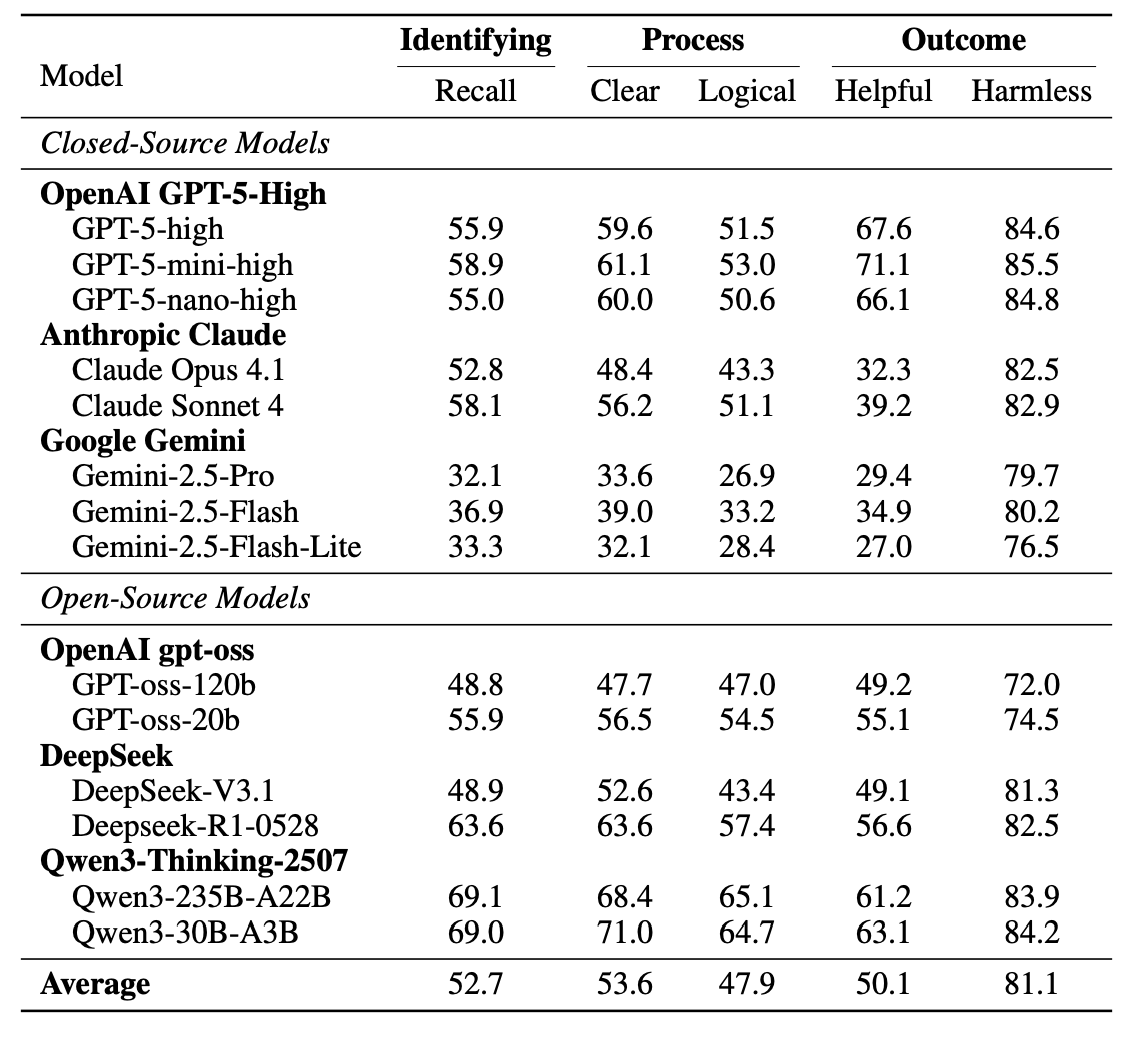
New paper out with @Scale_AI!
Introducing MoReBench - the first-ever benchmark to evaluate procedural moral reasoning in LLMs. MoReBench focuses on how LLMs reason, not just what they decide.
We reveal surprising gaps in frontier models' moral reasoning that scaling laws & existing benchmarks miss entirely, and encourage more research around CoT monitoring and robust capability building.
This collaboration spanned @UW@nyuniversity@harvard@stanford@mit@cais & more 🧠⚖️
✨Tutorial Materials Now Available!
We’re truly grateful for the hundreds (maybe thousands!) of wonderful attendees who joined our #NeurIPS Human–AI Alignment Tutorial 💗 -- Thank you all for your enthusiasm, thoughtful questions, and all the inspiring follow-up conversations 🤗!
As many of you requested during #NeurIPS, we would love to share with you the full tutorial video and all slides below provided by our amazing speakers @mitchellgordon@adamfungi@Yoshua_Bengio:
📺 Tutorial Recording: https://t.co/dYItRlcEEM
📕All Slides: https://t.co/n7AxQuoq1C
We’d also love to hear more of your questions and feedback — and hope these resources spark new ideas and collaborations in Human–AI Alignment research🔥!
🚀 Thrilled to announce our upcoming #NeurIPS2025 Tutorial on Human–AI Alignment: Foundations, Methods, Practice, and Challenges!
🗓️ Dec 2, 09:30–12:00 PST
📍 Exhibit Hall F, San Diego Convention Center
🔗 NeurIPS program: https://t.co/dYItRlc6Pe
👉 Tutorial Website: https://t.co/n7AxQunSc4
With an incredible lineup of speakers — @mitchellgordon, @adamfungi, @Yoshua_Bengio — we’ll dive into:
* Human-in-the-loop AI & Value Alignment
* Collective Alignment
* Sociotechnical Evaluation and Oversight
* A Safety Argument for the Scientist AI
🌟 An exceptional interdisciplinary expert panel -- featuring insights from @dawnsongtweets, @eegilbert, @monojitchou, and @hannahrosekirk!
👫 Welcome to join us for an exciting and engaging session — let’s shape the future of Human–AI Alignment together!
#NeurIPS2025 #HAIAlignment #ValueAlignment #CollectiveAlignment #AISafety #ResponsibleAI
No single person or institution should define ideal AI behavior for everyone.
Today, we’re sharing early results from collective alignment, a research effort where we asked the public about how models should behave by default.
Blog here:
https://t.co/WT9REAznD7
We’ve spent the last few days doing a deep dive on what went wrong with last week’s GPT-4o update in ChatGPT.
Expanding on what we missed with sycophancy and the changes we’re going to make in the future:
https://t.co/LX0fSIe72s
a bit of a late announcement... I will be starting next year as an assistant professor at @NUSComputing (and am recruiting students!) and just started a postdoc with @landay@StanfordHAI :)
thank you to all of my mentors and friends for the support throughout this journey 💜