Phoenix 🐦🔥 works zero-shot (out-of-the-box) on unseen cohorts, patients, organs, and tissues — no fine-tuning needed. This is the start of a real shift in how we'll use pathology archives. Hypothesis generation at this scale opens up questions we couldn't realistically ask before, especially in understudied tissues and subtypes.
Our paper is now on arXiv: https://t.co/lfRLCyLrCx
Besides all the details and discussions of the broader literature, it also contains lots other experiments that answer some of the questions we have already received. For example:
🎉 Our paper MJEPA has been accepted at #ECCV2026 !!
Huge thanks to my awesome collaborators @AdrienBardes, @michaelrabbat , Sumit Chopra @mattmucklm and Nicolas Ballas
Paper: https://t.co/PmcODf4qld
Code + checkpoints coming soon
See you at ECCV!
Can we predict future brain activity in a small vertebrate?🤔
We're releasing ZAPBench⚡️(#ICLR2025 spotlight): a benchmark to forecast activity in a whole vertebrate brain🧠 at single-cell resolution!🐟 70k+ neurons, 3 TB of data & extensive baselines. Connectome is coming!
🧵👇
An interesting part of CVPR was the TC PAMI meeting, followed by 3 proposals on how to improve CVPR:
1) @georgiagkioxari highlighted that award candidates are often industry papers, and proposed an "Academic best paper award"
2) @taiyasaki noted that CVPR best paper award winner did not provide code or weights, and proposed that awards would not be given to closed papers
3) @pjreddie noted that many institutions are funded by defense contracts, and proposed that CVPR would not accept papers by these institutions
When a quantized reasoning model fails, we usually assume it just lost the capability to solve the problem. But we surprisingly show that in up to 52% of failures, the quantized model actually reaches the correct answer but then does not commit to it. 🧵👇 1/8
🚨 𝗠𝗲𝗱𝗶𝗰𝗮𝗹 𝗔𝗜 𝗥𝗲𝘀𝗲𝗮𝗿𝗰𝗵 𝗔𝗹𝗲𝗿𝘁! 🚨
How can we improve 3D CT analysis by aligning vision and language at a finer, concept-level granularity, moving beyond global representations?
@Raidium presents 𝗝𝗼𝗹𝗶𝗮 with its 𝗖𝗼𝗻𝗤𝘂𝗲𝗿 𝗳𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸: a 3D CT foundation model leveraging concept-level vision-language alignment without spatial supervision.
By Julien Khlaut, @CharlesCorbiere , Baptiste Callard, Amaury Prat, Leo Butsanets, Antoine Saporta, Théo Danielou, Leo Machado, Korentin Le Floch, Tom Boeken, Pierre Manceron and @cdancette
Now you can watch and listen to the latest Medical AI papers daily on our YouTube and Spotify channels!
YouTube Explainer: https://t.co/TKeeTzsink
YouTube Shorts: https://t.co/MYhQUyWrpn
Spotify: https://t.co/r8IOqk05Zs
Here's why it's exciting: 👇🧵 1/9
#MedicalAI #Healthcare #CTImaging #VisionLanguage
[1/9]
Our survey "Hyperbolic Deep Learning in Computer Vision: A Survey" has been accepted to #IJCV!
The survey provides an organization of supervised and unsupervised hyperbolic literature.
Online now: https://t.co/pHbOZKWqeq
w/ @GhadimiAtigMina@mkellerressel@jeffhygu
@syeung10
🎉 Our dataset paper is now published in Scientific Data @NaturePortfolio!
🔗 https://t.co/E1YJJvR1AL
We present 40k+ expertly annotated single-cell blood images across 18 blood cell classes to support researchers in building robust AI tools for hematological diagnostics 🤖🩺
Thrilled to share that our paper, “Deep learning reveals antimicrobial peptides within prions,” is now published in @NatureMicrobiol@NaturePortfolio.
In this work, we used AI to ask an unexpected question: could proteins best known for their role in fatal neurodegenerative diseases also encode molecules that fight infection?
Prions and prion-like proteins are usually viewed through the lens of misfolding, aggregation, and disease. But biology is often more layered than our labels suggest. Our study shows that these proteins can contain encrypted antimicrobial peptides, which we call prionins.
This connection did not come out of nowhere. Previous studies had shown that certain amyloid-associated protein sequences, including amyloid-β and the cellular prion protein, can have antimicrobial or host-protective activity.
But until now, this had not been explored systematically across prion and prion-like proteins at scale.
Using our deep-learning platform APEX 1.1, we screened 19.3 million peptide fragments from 2,897 prion-related proteins. This search identified 1,179 candidate antimicrobial peptides, moving from scattered observations to a global AI-guided search across millions of possible protein fragments.
We then moved from prediction to experiment. Of 75 synthesized prionins, 59 inhibited at least one bacterial pathogen, including multidrug-resistant strains. Forty-two showed activity at 16 µM or lower against at least one pathogen.
Many prionins disrupted bacterial membranes, and a subset showed encouraging early selectivity, including minimal hemolysis and limited cytotoxicity. Two lead prionins also reduced Acinetobacter baumannii burden in a mouse skin-infection model, with efficacy comparable to polymyxin B in the model tested.
This is still early-stage work. We do not show that prionins are naturally released during infection or that they function physiologically in host defense, and these findings do not represent a treatment ready for patients.
But the study raises a provocative idea: proteins long viewed mainly as biological “villains” may also encode useful molecular functions.
More broadly, it shows how AI can become a discovery engine for biology: helping us search hidden molecular spaces, connect seemingly distant fields such as neurodegeneration and innate immunity, and uncover new starting points for medicine in places we might never have thought to look.
At a time when new antibiotics are urgently needed, expanding where we search matters.
Deeply grateful to @mdt_torres, Fangping Wan, and everyone who made this work possible, including @Penn, @CBE_Penn, @PennBioeng, @PennEngAI, @PennEngineers, @PennMedicine, @PennChemistry, @PennMicro, @PennPsych, and @PennSAS.
https://t.co/Teou3HbVOS
It surprised me that the platonic representation paper got so much discussion, but this paper didn't.
It's also one of the most severe academic burns I've seen in a while!
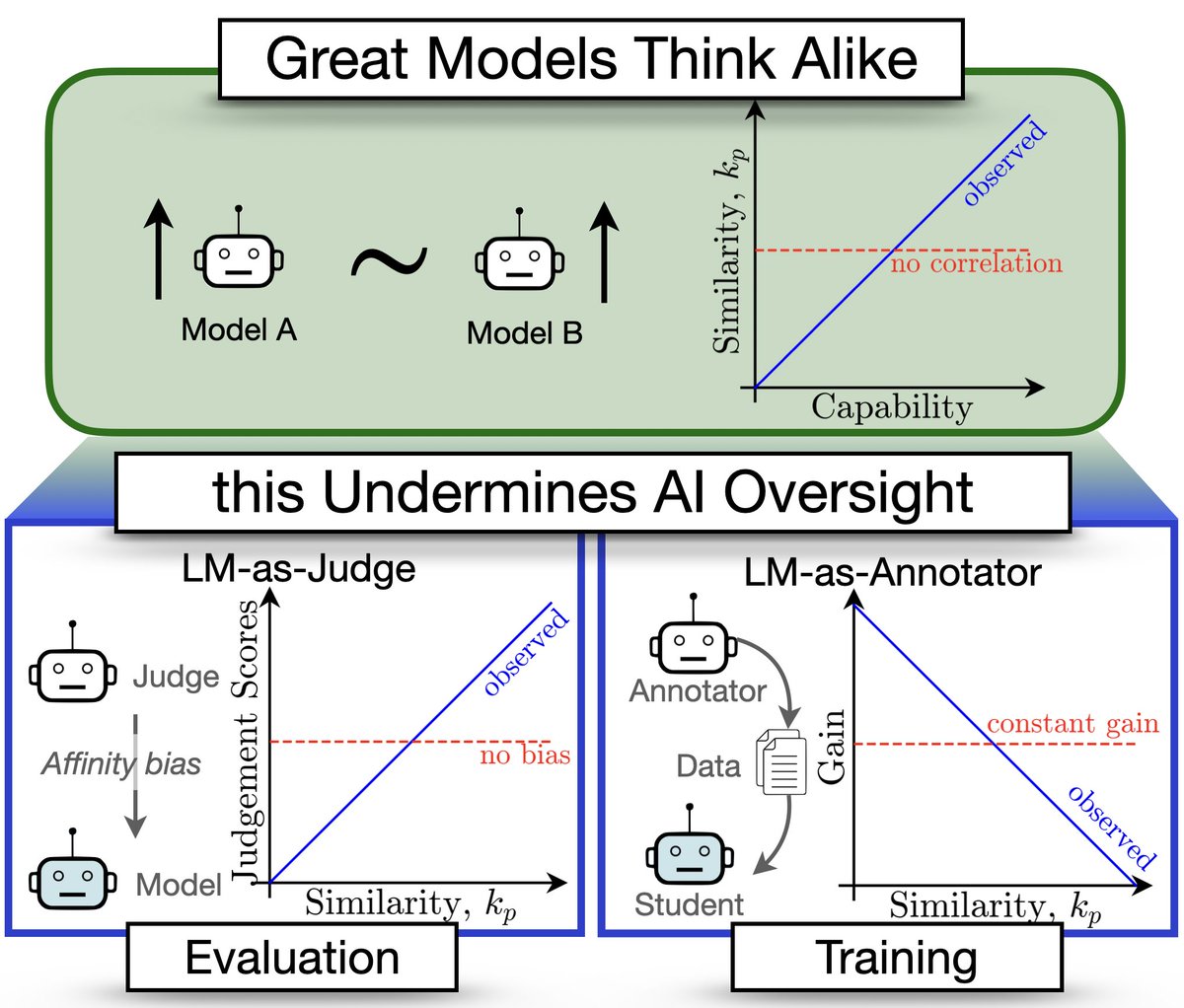
🚨Great Models Think Alike and this Undermines AI Oversight🚨
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇
Continual learning is bottlenecked by realistic evaluations
Introducing FutureSim, which replays real-world events in the temporal order they occurred
We benchmark frontier agents at updating predictions about how our world evolves, in native harnesses like Codex, Claude Code
📢New ICML 2026 position paper: "Explainability research should prioritize foundations over ad-hoc methods."
Despite countless explainability techniques (incl. feature attribution, concept-based methods, SAEs), explanations rarely influence real workflows. Why?
We believe this is due to an over-emphasis on producing new methods instead of confronting core foundational questions, like definitions, properties, evaluations and utility.
One example: despite 1000s of papers on SAEs, there is no rigorous, falsifiable definition of "concept", the very quantity it aims to discover. Without a definition, it is unclear what to evaluate, or how to quantify benefits.
In the absence of gold-standard evals, papers are forced to use proxy evals (like sparsity-reconstruction tradeoffs for SAEs) that have weak links to the underlying task. How to break this cycle?
The key idea is that clarity at any step: applications, evaluations, properties, or definition, helps define the other steps. They are all interdependent! Foundations doesn't necessarily mean epsilon-delta definitions, but greater clarity about goals.
What we can do now: While writing the next XAI paper, we can ask ourselves whether we can partly address some foundational questions: better definitions, gold-standard evals, or well-motivated use-cases. We present a 5-point checklist in the paper as a useful starting point.
Please read the paper for more detailed arguments and analysis!
This was a great multi-institutional collaboration with an incredible set of colleagues: @ML_Theorist@lesiasemenova NaveFrost @CyrusRashtchian@valentynepii@ShichangZhang@hima_lakkaraju@CynthiaRudin@jennwvaughan
Paper link: https://t.co/9afu9vYomP
(Personal) Reflections: https://t.co/7fkhUiPKUU
🤔When Does Closeness in Distribution Imply Representational Similarity?
Find it out --from an Identifiability perspective-- in our recent paper, published at @NeurIPSConf 🎉
https://t.co/VTuSJlKBX5
1/6🧵
My thesis is now online!
https://t.co/kdraSXMQLy
This is more than just a list of publications. I invested a lot of time and passion writing this thesis in hope that it will make for an interesting read.
Here's a summary of what you'll find in it.
Sharing initial exploration of the new Gemma4 model🔎
"Inspecting Visual and Audio Token Representations in Gemma4-12B"
https://t.co/uhp0EhHjbi
(Go explore the demo on vision and audio inputs!)
When Google released the model, I had some burning questions about the internal processing of different modalities. Especially after recently working on LatentLens (https://t.co/NX0EzOEzKs)
Specifically, I was curious what LatentLens and LogitLens can reveal across layers
Google recently released Gemma4 and this got people excited because the model is: a) encoder-free and b) trained from scratch on interleaved sequences of multimodal tokens (vision, audio, text).
This deviates from the mainstream paradigm of adapting LLMs for multimodality post-hoc, where e.g. CLIP or some audio encoder is plugged into the LLM.
Now with Gemma4, there is no clear distinction anymore between low-level processing in the perceptual encoders and more linguistic/abstract processing in the LLM.
So one would wonder:
At which layers do visual or audio tokens start looking like language?
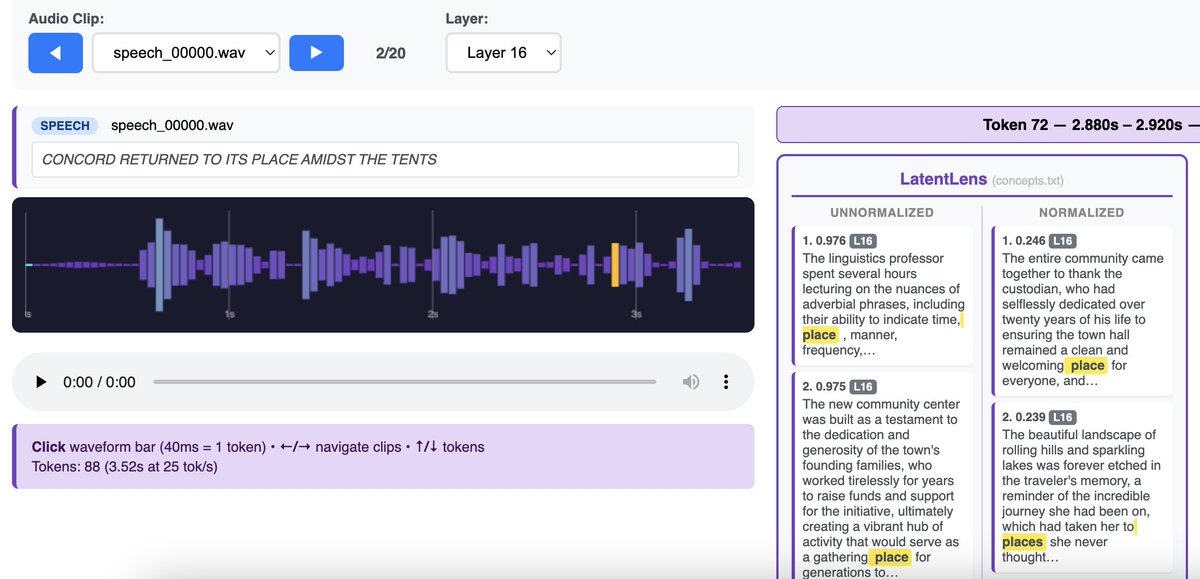
To what extent does LatentLens still work? (We know it worked really well within the post-hoc LLM paradigm)
Findings TLDR:
VISION
* visual tokens start being interpretable by layer 8-16 (Gemma4-12B has 47 layers)
* LatentLens peaks around layer 16, LogitLens takes over in later layers (~36-44)
AUDIO
* similar with audio tokens: LatentLens can show which layers are the first where audio tokens start resembling interpretable language, but Logit Lens better in late layers
* while speech is interpretable, other sounds (eg dog barking) are not
* strange finding on audio 🤔: LatentLens shows transcript words in the right sequence, just not anchored to the moment each word is spoken (exact timestamps), instead they are off-set by many tokens
Broader takeaways:
LatentLens and Logit Lens complement each other
The natively multimodal paradigm of Gemma4 could imply: now visual and audio inputs are less forced to be represented in a language-like way
Compared to our original LatentLens paper, we see much more evolution across layers happening (future work should dig deeper!) and in general more “strange” results
We put the paper online that provides further details (beyond my ICLR keynote) on the role of spontaneous symmetry breaking and Goldstone modes in deep learning. Enjoy! (w/ Nabil Iqbal, Thomas Andy Keller, Takeru Miyato and Yue Song.) https://t.co/wN8q7qhUaP
LoMa-R is our newest addition to the LoMa family. In our IMW paper at #CVPR26, we investigate rotation invariance in the sparse matching pipeline. The resulting model is robust to rotations, even matching star constellations, and achieves strong upright performance.

























![OpenlifesciAI's tweet photo. 🚨 𝗠𝗲𝗱𝗶𝗰𝗮𝗹 𝗔𝗜 𝗥𝗲𝘀𝗲𝗮𝗿𝗰𝗵 𝗔𝗹𝗲𝗿𝘁! 🚨
How can we improve 3D CT analysis by aligning vision and language at a finer, concept-level granularity, moving beyond global representations?
@Raidium presents 𝗝𝗼𝗹𝗶𝗮 with its 𝗖𝗼𝗻𝗤𝘂𝗲𝗿 𝗳𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸: a 3D CT foundation model leveraging concept-level vision-language alignment without spatial supervision.
By Julien Khlaut, @CharlesCorbiere , Baptiste Callard, Amaury Prat, Leo Butsanets, Antoine Saporta, Théo Danielou, Leo Machado, Korentin Le Floch, Tom Boeken, Pierre Manceron and @cdancette
Now you can watch and listen to the latest Medical AI papers daily on our YouTube and Spotify channels!
YouTube Explainer: https://t.co/TKeeTzsink
YouTube Shorts: https://t.co/MYhQUyWrpn
Spotify: https://t.co/r8IOqk05Zs
Here's why it's exciting: 👇🧵 1/9
#MedicalAI #Healthcare #CTImaging #VisionLanguage
[1/9]](https://pbs.twimg.com/media/HLrVWMrbgAAHpA0.jpg)