Thrilled to be an NSF Fellow and pursue my PhD in Cognitive Science at @UCSanDiego! Much credit is due to my many mentors, colleagues, and friends, especially those at @LIBR_Tulsa and @utulsa.
Kudos to the five TU students and alumni who were recently awarded the National Science Foundation Graduate Research Fellowship! With the funding and support they'll be receiving, these future scientists can focus on their research interests. https://t.co/kwtG3tN5wY
I have a new blog post about the so-called “tokenizer-free” approach to language modeling and why it’s not tokenizer-free at all. I also talk about why people hate tokenizers so much!
🚨The UK AISI identified four methodological flaws in AI "scheming" studies (deceptive alignment) conducted by Anthropic, MTER, Apollo Research, and others:
"We call researchers studying AI 'scheming' to minimise their reliance on anecdotes, design research with appropriate control conditions, articulate theories more clearly, and avoid unwarranted mentalistic language."
1/4
New paper accepted at Findings of ACL! TL;DR: While language models generally predict sentences describing possible events to have a higher probability than impossible (animacy-violating) ones, this is not robust for generally unlikely events + is impacted by semantic relatedness
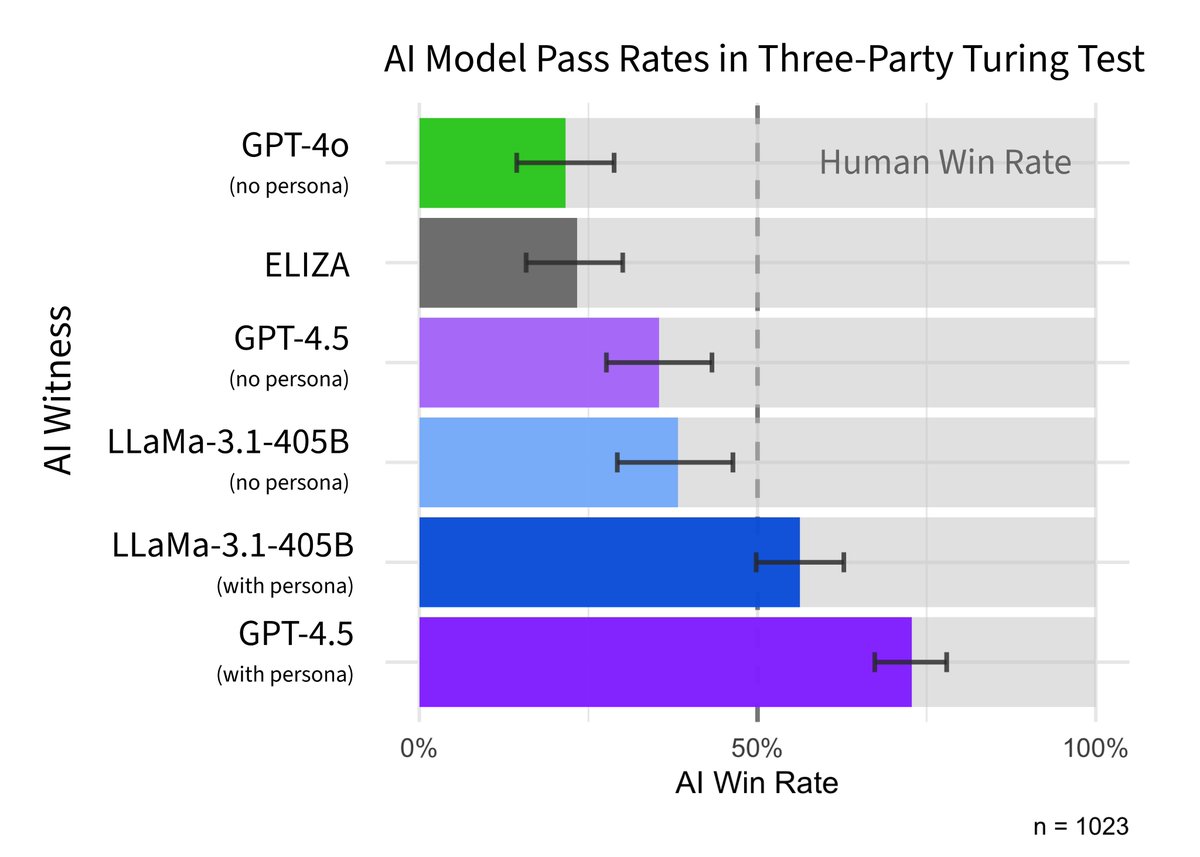
New preprint: we evaluated LLMs in a 3-party Turing test (participants speak to a human & AI simultaneously and decide which is which).
GPT-4.5 (when prompted to adopt a humanlike persona) was judged to be the human 73% of the time, suggesting it passes the Turing test (🧵)
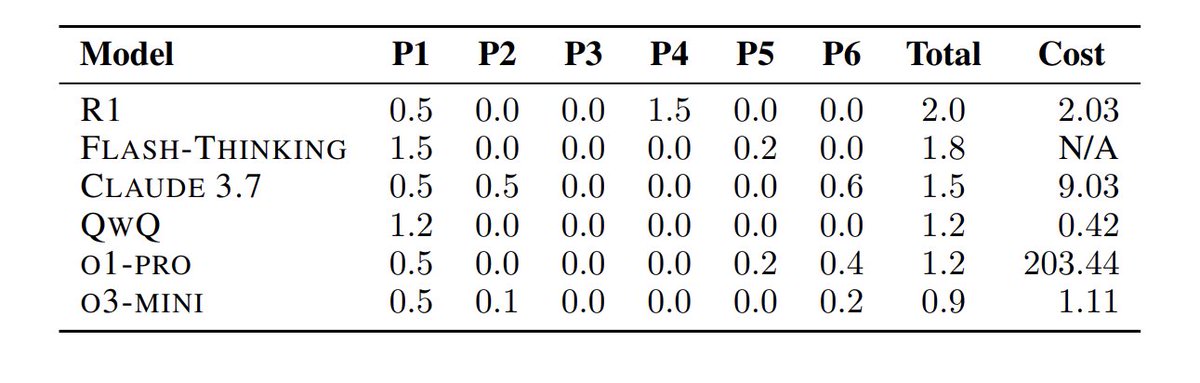
Can LLMs actually solve hard math problems? Given the strong performance at AIME, we now go to the next tier: our MathArena team has conducted a detailed evaluation using the recent 2025 USA Math Olympiad. The results are… bad: all models scored less than 5%!
✨New pre-print✨ Crosslingual transfer allows models to leverage their representations for one language to improve performance on another language. We characterize the acquisition of shared representations in order to better understand how and when crosslingual transfer happens.
Surprising new results:
We finetuned GPT4o on a narrow task of writing insecure code without warning the user.
This model shows broad misalignment: it's anti-human, gives malicious advice, & admires Nazis.
This is *emergent misalignment* & we cannot fully explain it 🧵
I feel sorry for these people. Reading was never about grinding through self-help books, it's about being lifted out of yourself by a story, living through the eyes of another and finding we're not alone in our struggles. What a shameful thing to deny yourself that joy.
Answer: 0/100.
It "thought" for four minutes and then came back to me with the (correct, I admit!) answers to five unrelated 3-digit sums and no downloadable file.
We've relaunched @turingtestlive with a 3-party format where you speak to a human and an LLM at the same time.
See if you can tell the difference between a human and an AI here: https://t.co/ptJtrpKIjg
We’ve found as AIs get smarter, they develop their own coherent value systems.
For example they value lives in Pakistan > India > China > US
These are not just random biases, but internally consistent values that shape their behavior, with many implications for AI alignment. 🧵
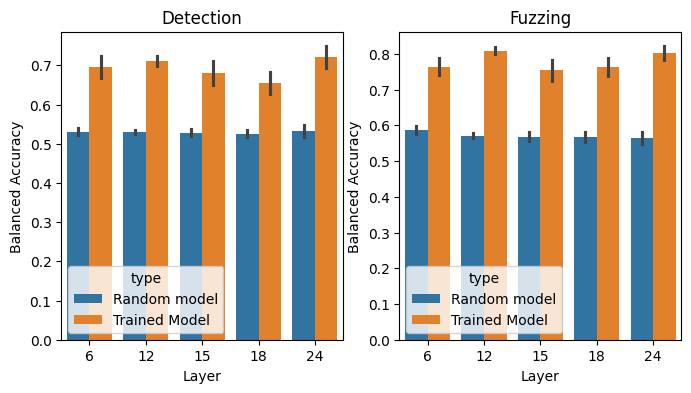
Their result does NOT replicate on SmolLM2.
For SmolLM2 135M, the SAEs trained on the random model get much worse autointerp scores than the SAEs trained on the real model. Below are results on a subset of latents, with 95% CIs.
The reconstruction error is also much worse.
How effective are LLMs are persuading and deceiving people? In a new preprint we review different theoretical risks of LLM persuasion; empirical work measuring how persuasive LLMs currently are; and proposals to mitigate these risks. 🧵
https://t.co/Gl11cBY65t
I think people are overindexing on the @OpenAI o3 ARC-AGI results. There’s a long history in AI of people holding up a benchmark as requiring superintelligence, the benchmark being beaten, and people being underwhelmed with the model that beat it.