New research from FAIR: Better & Faster Large Language Models via Multi-token Prediction
Research paper ➡️ https://t.co/Q36b6FUjDj
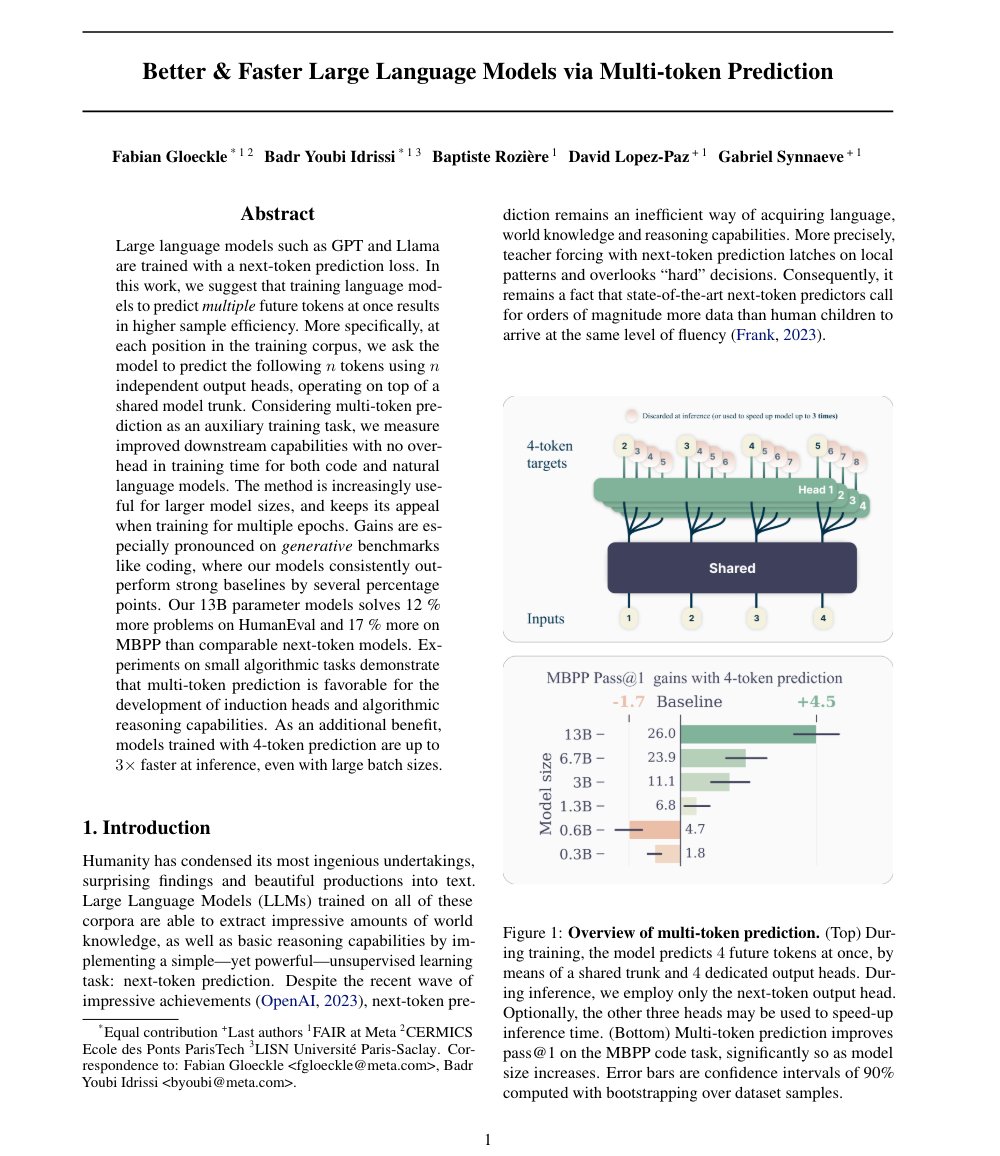
We show that replacing next token prediction tasks with multiple token prediction can result in substantially better code generation performance with the exact same training budget and data — while also increasing inference performance by 3x.
While similar approaches have previously been used in fine-tuning to improve inference speed, this research expands to pre-training for large models, showing notable behaviors and results at these scales.
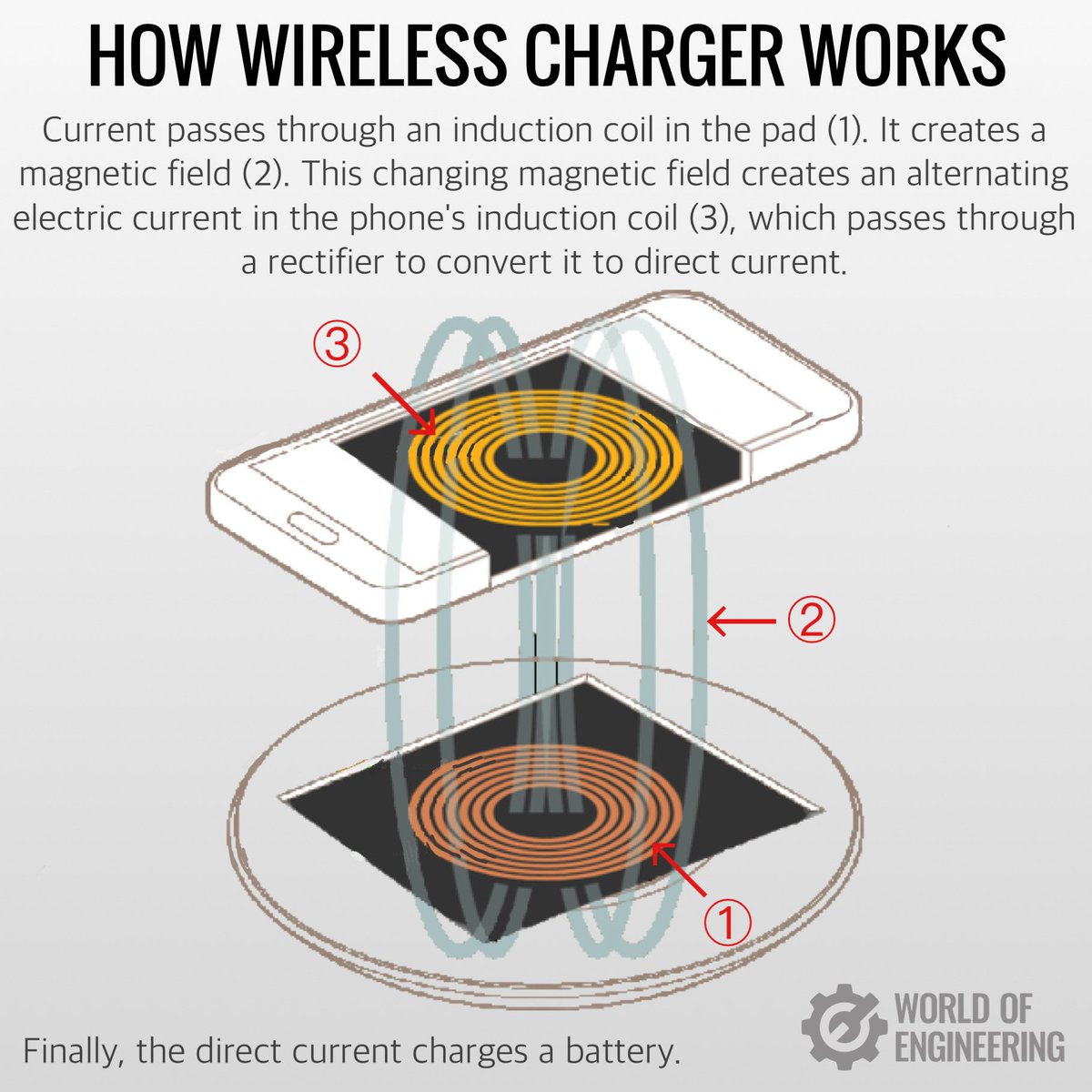
From @Aurimas_Gr >> #Infographic explains RAGs (Retrieval Augmented Generation) systems, including #VectorDB (Vector #Databases), #LLMs, #AI, #GenerativeAI
Source: https://t.co/d3UZ9a5BTI
Details (from source article):
𝟭: Split text corpus of the entire #KnowledgeBase into chunks - a chunk will represent a single piece of context available to be queried. Data of interest can be from multiple sources, e.g. Documentation in Confluence supplemented by PDF reports.
𝟮: Use the Embedding Model to transform each of the chunks into a vector embedding.
𝟯: Store all vector embeddings in a Vector Database.
𝟰: Save text that represents each of the embeddings separately together with the pointer to the embedding (we will need this later).
Next constructing the answer to user question/query:
𝟱: Embed a question/query you want to ask using the same Embedding Model that was used to embed the knowledge base itself.
𝟲: Use the resulting Vector Embedding to run a query against the index in the Vector Database. Choose how many vectors you want to retrieve from the Vector Database - it will equal the amount of context you will be retrieving and eventually using for answering the query question.
𝟳: Vector DB performs an Approximate Nearest Neighbour (ANN) search for the provided vector embedding against the index and returns previously chosen amount of context vectors. The procedure returns vectors that are most similar in a given Embedding/Latent space.
𝟴: Map the returned Vector Embeddings to the text chunks that represent them.
𝟵: Pass a question together with the retrieved context text chunks to the LLM via prompt. Instruct the LLM to only use the provided context to answer the given question. This does not mean that no Prompt Engineering will be needed - you will want to ensure that the answers returned by LLM fall into expected boundaries, e.g. if there is no data in the retrieved context that could be used make sure that no made up answer is provided.