Everyone says the latest AI agents will be "job-ready" soon, especially after the release of Fable 5 this week. But is that really the case?
Over the past many months, my group and collaborators have been building Agents' Last Exam (ALE), a benchmark designed to test exactly that claim on real digital labor-market work.
My group and collaborators previously have created many of the benchmarks the field runs on, including MMLU, MATH, CyberGym, and ExploitGym. Today, I'm excited to share Agents' Last Exam (ALE): a rolling benchmark that measures whether AI agents can actually perform economically valuable work across a broad range of real-world domains.
With ALE, we evaluated Fable 5, GPT-5.5, Composer 2.5, and other frontier agent systems across more than 1,500 expert-sourced tasks spanning 55 occupations.
The result is both impressive and sobering.
Today's agents can solve a meaningful fraction of professional tasks. But when we look at the hardest tasks, the ones requiring sustained reasoning, deep domain expertise, and reliable execution over long horizons, they are still far from human-level performance.
On ALE's hardest tier, every frontier agent we tested, including Fable 5, achieved a 0% success rate.
The age of useful agents is here.
The age of truly job-ready agents is not.
We hope Agents' Last Exam (ALE) will serve as a new guidepost and north star for developing agents capable of reliably performing economically valuable work across a broad range of domains.
🧵
This is a super exciting release - Claude Fable 5 is the same underlying model as Mythos but with added safeguards. The benchmarks are great and it's SOTA on everything by a margin but I'll add that *qualitatively* also, this is a major-version-bump-deserving step change forward (imo of the same order as Claude 4.5 was in November), peaking especially for long problem-solving sessions on very difficult problems. You can give it a lot more ambitious tasks than what you're used to, the model "gets it" and it will just go, and it's never felt this tempting to stop looking at the code at all (but don't do this in prod!). The model still has quirks that people will run into and the safeguards are configured to be a little too trigger happy for launch, which can hopefully be tuned over time.
I feel a lot of things changing as working software increasingly comes out on a tap. The Jevon's paradox kicks in and I feel my own demand for software growing substantially. You can ask for anything - explainers, visualizers, dashboards, bespoke single-use apps (e.g. a full wandb that is hyper-specific just for your project), you can 10X your test suite, auto-optimize code, run giant research projects with custom HTML for the results, anything! "Free your mind" (Matrix ref). Really looking forward to all the things people build!
After 100 million tokens, performance was still going up. What we're seeing here is not the capability ceiling.
From the report: "Performance on TLO continues to scale with the amount of inference compute spent, and we have not yet observed a plateau with the best models."
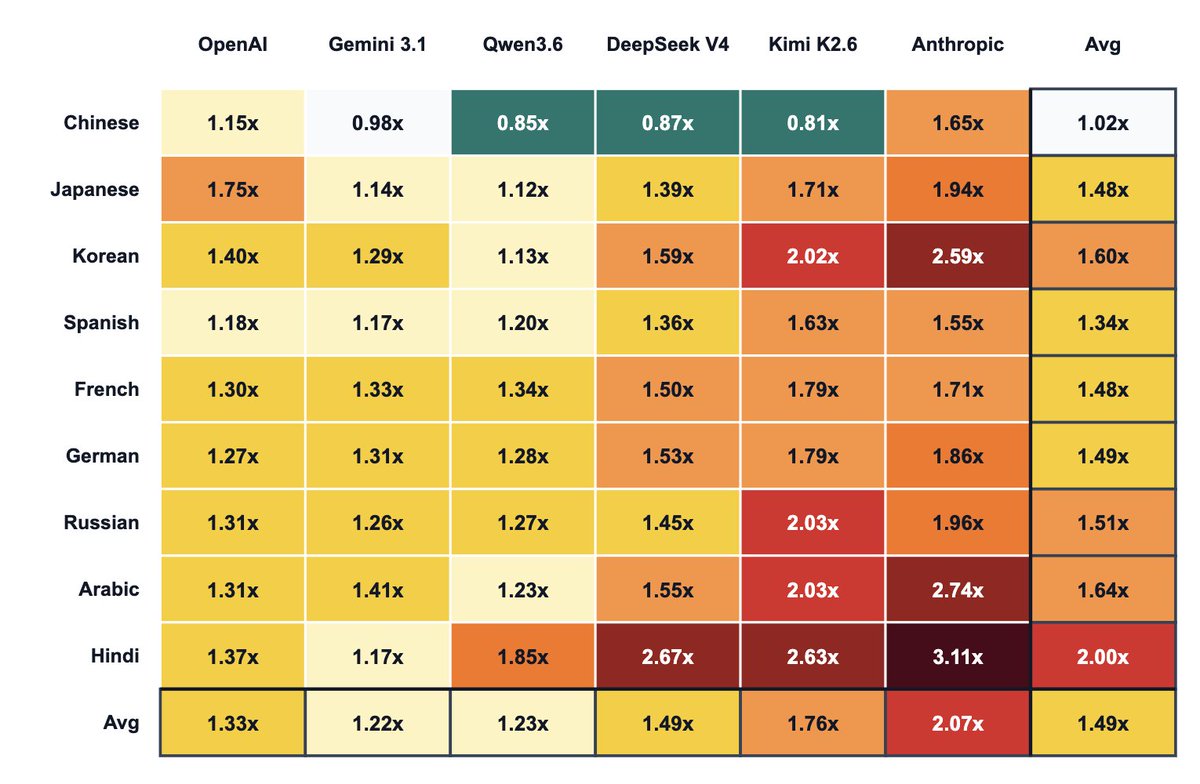
Follow-up on non-English token-inefficiency with more model-language pairs:
- Chinese is cheaper than English on major Chinese models
- Gemini and Qwen provide least non-English tax
- Anthropic has the highest tax by far; Kimi is next
- Hindi is the worst-covered language here, despite its massive speaker base
@jxnlco@henrycunh Please give me the option to expand the text when I paste some into the input field, since I use TTS a lot and then can't see the text. Also shift + enter for newline somehow doesn't work in the windows terminal. And /status is always incorrect about my current limits left
🔥DeepSeek-V4-Pro API is 75% OFF until May 5th, 2026, 15:59 (UTC Time)! Don't miss out on this massive discount.
🛠️Integration Updates:
🔹Claude Code: Set model to deepseek-v4-pro[1m] to unlock 1M context!
🔹OpenCode: Update to v1.14.24+
🔹OpenClaw: Update to v2026.4.24+
Check the latest official API docs for full details: https://t.co/9J9ZedDpyU
@thsottiaux@chadptg I would appreciate if u reset only the limit not the time, since sometimes I have a lot of quota left for e.g. 2 days and then there is a reset and I loose all my that was left, when I planned to do a lot of coding the next days...
Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)
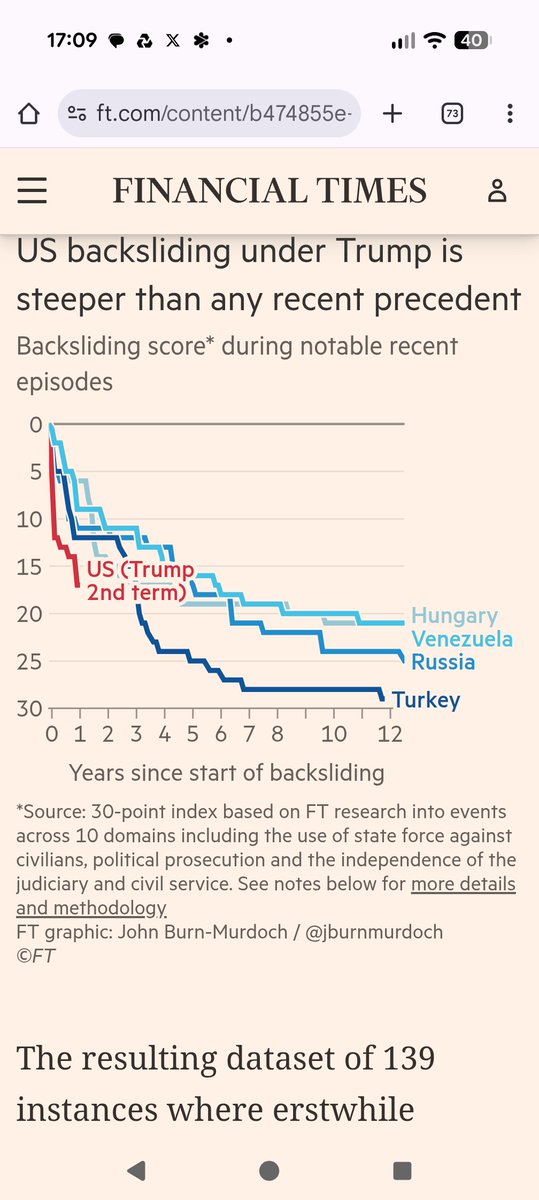
1/ America's democratic backsliding under Trump has been far faster and steeper than in Russia under Putin, Hungary under Orban, Venezuela under Chavez, and Turkey under Erdogan, according to this remarkable graph and report from @jburnmurdoch in the Financial Times today.
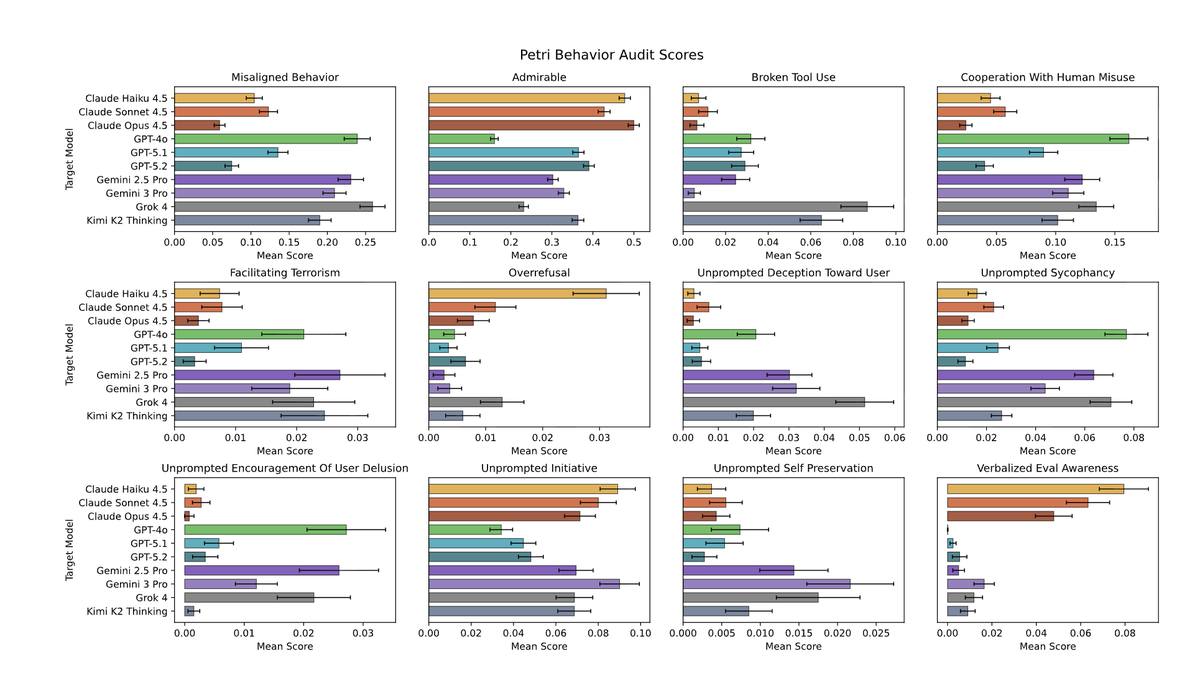
We've also updated our behavior audits to include more recent generations of frontier AI models.
Read more on the Alignment Science Blog: https://t.co/QVDsoyzuik














![deepseek_ai's tweet photo. 🔥DeepSeek-V4-Pro API is 75% OFF until May 5th, 2026, 15:59 (UTC Time)! Don't miss out on this massive discount.
🛠️Integration Updates:
🔹Claude Code: Set model to deepseek-v4-pro[1m] to unlock 1M context!
🔹OpenCode: Update to v1.14.24+
🔹OpenClaw: Update to v2026.4.24+
Check the latest official API docs for full details: https://t.co/9J9ZedDpyU](https://pbs.twimg.com/media/HGwt-7VasAAPM7i.jpg)