How should we evaluate LLMs in medicine given increasing benchmark saturation? Is simulation meaningful? Does LLM performance on standardized exams still contain signal?
We explore in the new @NEJM_AI and argue that when it comes to benchmarks, humans are (still) the only way
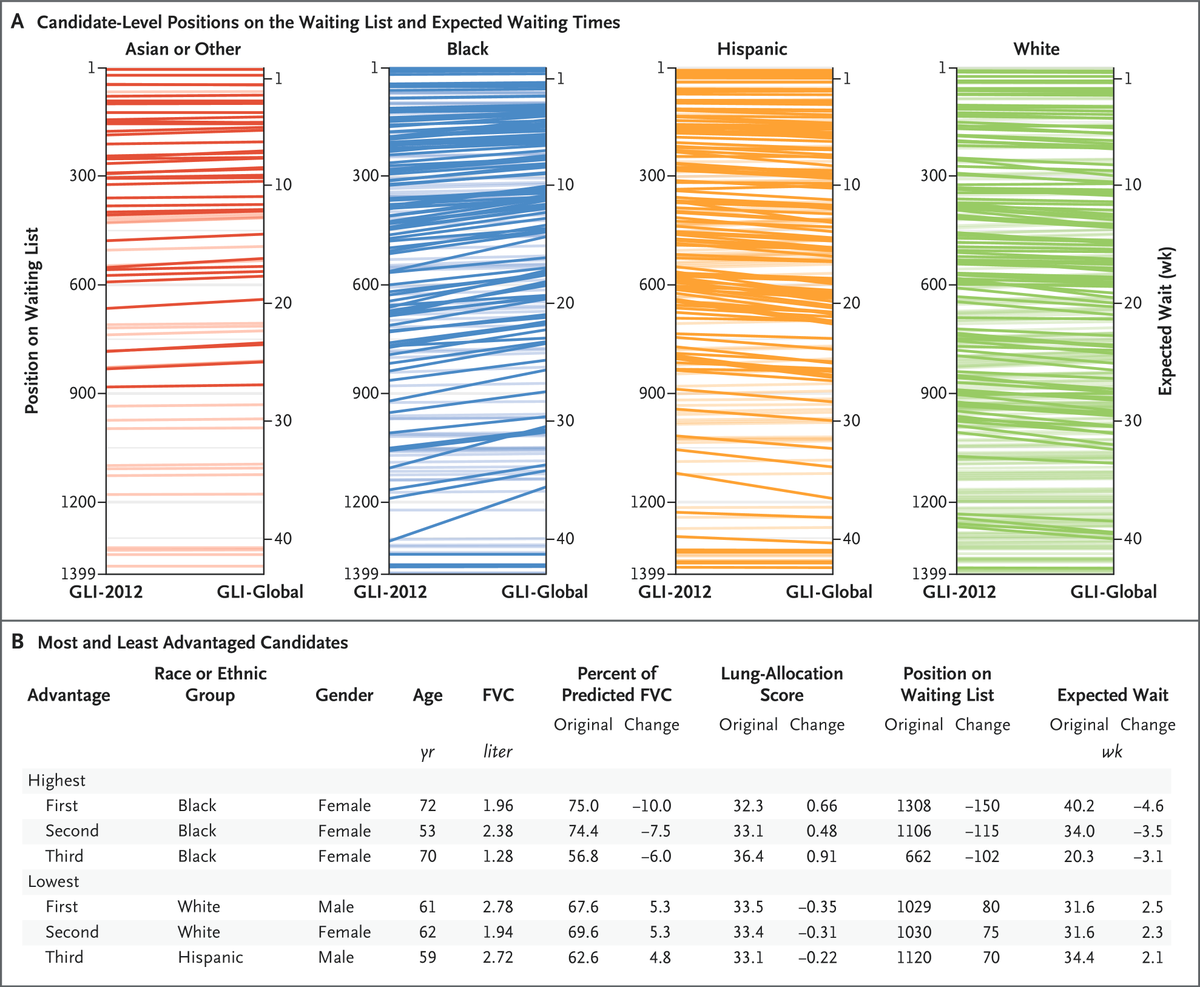
Special Article: Implications of Race Adjustment in Lung-Function Equations https://t.co/uQ83ohdbbd
Editorial: Beyond Diagnostics — Removing Race from Lung-Function Test Interpretation https://t.co/DTrbUi2OeR
#ATS2024@atscommunity
Question:
How are observational studies that explicitly aim to emulate a target trial reported?
Answer:
Not well - reporting could have been more consistent and complete for many studies.
https://t.co/6UWRkjkKp4
@_MiguelHernan
The @NEJM is getting serious about covering #AI in medicine with a new series and journal. A #GPT4 preview, review and editorial today
This important advance is covered in-depth in a new book
https://t.co/hGyrJt4yt7
Introducing the Library of Guidance for Health Scientists (LIGHTS)
A Living Database for Methods Guidance:https://t.co/6NOYQTXsAg
https://t.co/hmOrBVNCPM
Taking over for @Pottegard
Paper #18: We talk about target trials often, but many of these principles have a long-standing history. @LundJenny walks through the bases for active-comparator/new-user design and how to implement a study #pharmepi
https://t.co/HyDwfU6Hdb
Today's #GEMRIP features scientifically fearless trainees and their investigations of:
1) guaranteed income on health outcomes (@EpiHoodScholar)
2) #COVID booster uptake (Victoria Scott)
3) the impact of under-ascertained #mortality on inference (Sita Lujintanon)
🤩🤩🤩
Our February issue is out‼️
Read the selection of the month:
➡️AI model to predict #HCC risk in patients with chronic #HBV
And much more at👉https://t.co/xf1McKErDX
#LiverTwitter
@tomhemmingk Protecting the next generation of Europeans against liver disease: findings & recommendations from the @EASLNews-Lancet Commission 👇 https://t.co/lJ3iwBgqSw