in 2026, the only onboarding process your startup needs is `claude mcp add`
here's how to give Claude Code access to 600K humans to do tasks in the physical world
I have a similar Codex skill inspired by @mattpocockuk
at the end of a long running prompt it summarizes everything into a 1page HTML page
also uses Excalidraw for diagram generation
Claude Fable can run autonomously for days.
This is the single highest-leverage prompt I use to stay on top of it:
"Spin up a persistent HTML page. As you work, append clear, timestamped updates with screenshots/media so I can follow along."
Literally a 10x better experience.
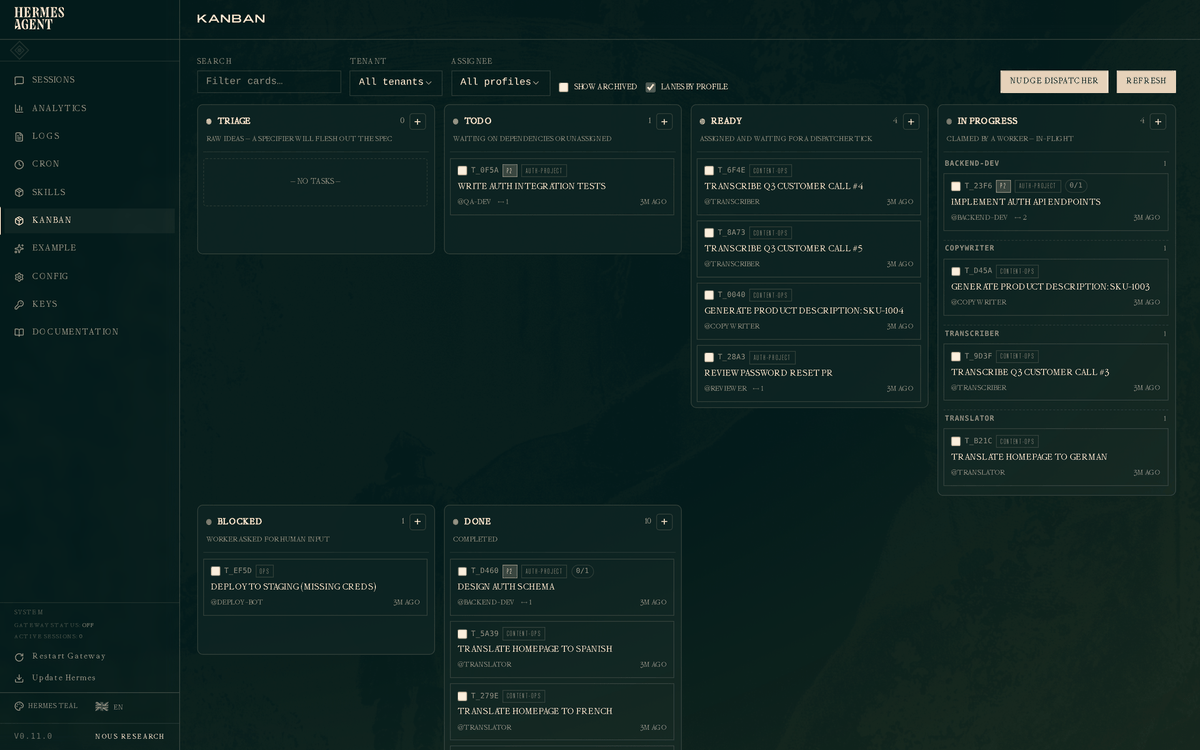
This works great in Hermes Agent, which can orchestrate a fleet of agents with varying models that you can "right-size" for the task.
This way you get the best model for each job, and extend your API usage to get the most out of every token
Start with Fable 5 then once you have a process down, convert it into a Skill, so future chats use subagents
This also works great in Cursor, Fable 5 can call Composer 2.5 or Sonnet subagents and which dramatically improves its context management
fable 5 burns tokens fast but write the prompt like this and it's totally workable.
"to save tokens, keep this main session (fable 5) on planning and frontend tasks, its visual output and ideas are worth the price. for backend and heavier implementation, write a clear spec and dispatch to codex (gpt-5.5 xhigh) with /goal to execute, my quota there sits unused anyway. you may keep the hardest parts in this session."
a frontend design prompt i've been testing that works well:
redesign {your page, e.g. pricing page} for this project. full creative freedom, but it has to be visually striking and interactive, with motion effects and a hidden easter egg. search 2026 design trends first and use them.
Introducing Boomer Evals - an eval that evaluates how typos and poorly formatted prompts affect accuracy in LLMs
I validated @steipete's approach with this question:
Do you really need perfectly edited prompts to get the best results out of LLMs?
I found that typos don't affect accuracy much, only on smaller models.
For the time you save fixing typos in your prompt, this cost is likely negligible for most prompts
Key findings
1. Typos don't move accuracy much
2. You pay for slop in tokens, not accuracy
3. Typos result in longer thinking processes. This can hurt context windows especially on smaller models.
Full report: https://t.co/Ea8LcPCbw6
Claude Fable can run autonomously for days.
This is the single highest-leverage prompt I use to stay on top of it:
"Spin up a persistent HTML page. As you work, append clear, timestamped updates with screenshots/media so I can follow along."
Literally a 10x better experience.
I can verify that this story is (probably) 100% true given that I met Otto IRL 2 days ago at a Cursor event at Cursor Cafe in Bangkok
He is a 12 year old founder (adorable, I know) but most importantly, serious and hungry to win.
He asked me a ton of questions about how to market his product, and what I thought about social media marketing
So for all the people commenting that this story is fake, you are wrong
And yes, he probably does have more users than you
A 12 yr old founder pitched me today
He raised.
Is currently in a reputable accelerator.
And used Apollo to get my #
He also probably has more users than you.
This is your sign to lock in.
Bruh if a 12 yr old can do it u can too.
A 12 yr old founder pitched me today
He raised.
Is currently in a reputable accelerator.
And used Apollo to get my #
He also probably has more users than you.
This is your sign to lock in.
Bruh if a 12 yr old can do it u can too.
@theo I'd be happy to pay the same but isn't to playbook subsidize the $200 plans, then make all their money off of Enterprise/API usage?
My bet is that Claude is gonna let us keep Fable access anyway, just a marketing stunt
Source https://t.co/1VdguQ9QY3
Recently, we purchased one of each Anthropic/OpenAI subscription plan and randomly ran long horizon coding tasks until we exhausted the weekly limit. It's widely believed that a $200/month plan maxes out at ~$2000/month worth of tokens (assuming API pricing). However, we found that the subscriptions are actually far more generous. (2/4)
We've always told startups to launch early, but I realized there's a powerful new reason to.
Before you launch, the speed you can build is now mainly limited by your imagination in what you tell AI.
After you launch, the AI can watch your users and make improvements on its own.
Cursor is on a generational run this week and their Compile conference is gonna be legendary
excited to meet all my fellow cursor lovers next week when i officially move to SF