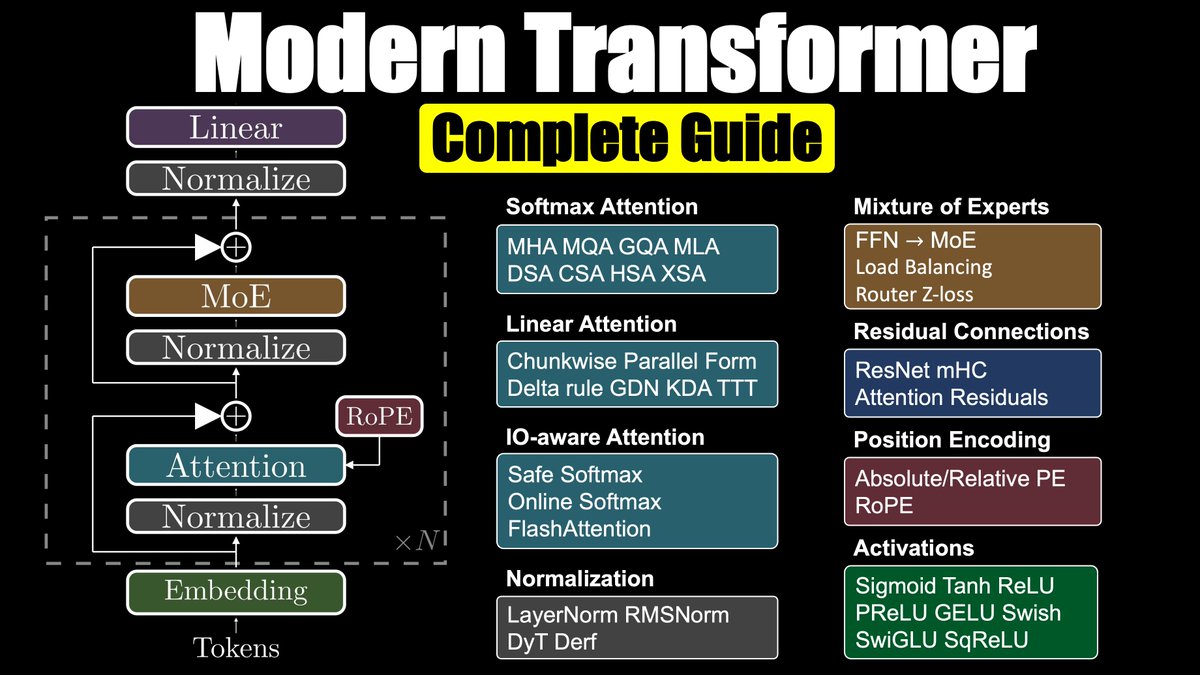
Modern Transformer - Complete Guide
Interested in learning the recent advances in transformers?
After 13 videos, I've finally completed this series!
🥳🥳🥳
Check out the course here:
https://t.co/CsujxlWigC
Love Jie’s vision. I recently come up with an analogy. Self-evolution in AI deployment is like passive income for humans. And a good environment is like a good income resource.
Recent thoughts:
The Shift to Long-Horizon Tasks
The most likely breakthrough this year will be in long-horizon tasks. We are moving toward a stage where Large Language Models (LLMs) learn to complete extended, complex missions by interacting with Agent environments. This is perhaps where the true value of LLMs lies. Take cybersecurity as an example: imagine a model that continuously hunts for software bugs and vulnerabilities. While it sounds like a search process, it’s actually the model learning the high-level intuition and methodology of a professional hacker. Unlike humans, AI can run 24/7 without fatigue. It could potentially find exploits at a much higher frequwill ency and claim bounties on platforms like HackerOne or BugCrowd. It sounds fun, but fundamentally, it's a revolution that displaces the hacker. If even hackers are being "disrupted," one can only imagine the impact on general programmers.
From One-Person to None-Person Companies
Building on long-horizon capabilities, Autonomous Agent Systems (AAS) will inevitably become the next frontier. Last year, we were discussing the rise of the "One Person Company" (OPC). I didn't expect us to move so quickly toward the "None Person Company" (NPC). It’s an ironic twist—we might all end up as NPCs in this new ecosystem.
Engineering the Impossible: Memory and Learning
To realize the vision above, we must solve three technical pillars: Memory, Continual Learning, and Self-Judging.
I used to think these would require massive paradigm shifts and years of research. However, the pressure from both the technical and application sides is so intense that we are seeing these capabilities emerge through ingenious engineering "tricks":
Memory: Long context windows (1M+) and RAG have significantly bridged the gap.
Continual Learning: While true continual learning remains difficult, the release cycles are shrinking. Global models are updated monthly; domestic models are catching up. If we reach weekly updates by next year, it will effectively function as continual learning.
Self-Judging: This remains the most elusive, yet models like Opus 4.7 are already demonstrating early self-correction and judgment capabilities.
The Self-Evolving Endgame
The most difficult—and most promising—path is Self-Evolution. The current wave is incredibly fierce. I suspect that models like Claude may have already achieved a baseline for self-training: writing their own code, cleaning their own data, generating synthetic data, and then training on it. It might "waste" some compute, but it saves the most precious resources: human labor and time. In the LLM era, speed is everything. Rapid iteration is what creates the cognitive gap between leaders and followers. Claude’s rumored 2-million-chip cluster for next year is likely dedicated to exactly this: autonomous model self-training.
Technical Summary:
1M Context: Necessary baseline.
Memory & Continual Learning: Prerequisites, likely solved first via "tricky" engineering.
Harnessing Environments: The breakthrough point.
Self-Judging: The tipping point.
Full Self-Training: The endgame.
Redefining AGI and the Industry
If this is the road to AGI, then AGI’s definition should be the sum of all human collective intelligence, not just an individual’s intelligence. It must possess the creative capacity to produce something as profound as the "Theory of Relativity"—meeting the bar set by Hassabis.
During this transition, every APP will need to be reconstructed as AI-native. In fact, we might move past the concept of APPs entirely. The most significant challenge will be the reconstruction of the operating system itself. In the future, you won’t see a traditional desktop; you will see an LLM OS, where applications are "generated on demand." This challenges the 80-year-old Von Neumann architecture and represents a total upheaval of the computer science industry.
The Irreversible Wave
From completing long-horizon tasks to fully autonomous operations, every sector—Security, Finance, Law, E-commerce—will be reshaped. Many friends have reached out lately, asking how to transform their enterprises to keep pace with AI. But few truly realize that this irreversible process has already begun. As this massive technical wave hits, we must be prepared to act, but we must also start thinking seriously about how to regulate it.
The data science revolution is here now.
TabPFN-3 is live, taking tabular foundation models to enterprise scale 🤩
1M training rows on a single H100. No training. No tuning. Load and predict.
🧵 1/5
#tabpfn#tabularfoundationmodels#priorlabs
📢 Diffusion-based LLM paper accepted to #ICML2026 🥳
Diffusion LLMs promise parallel & bidirectional generation, but fully non-autoregressive decoding still struggles in practice.
We analyzed why NAR fails, and show how minimal interventions can substantially improve it!
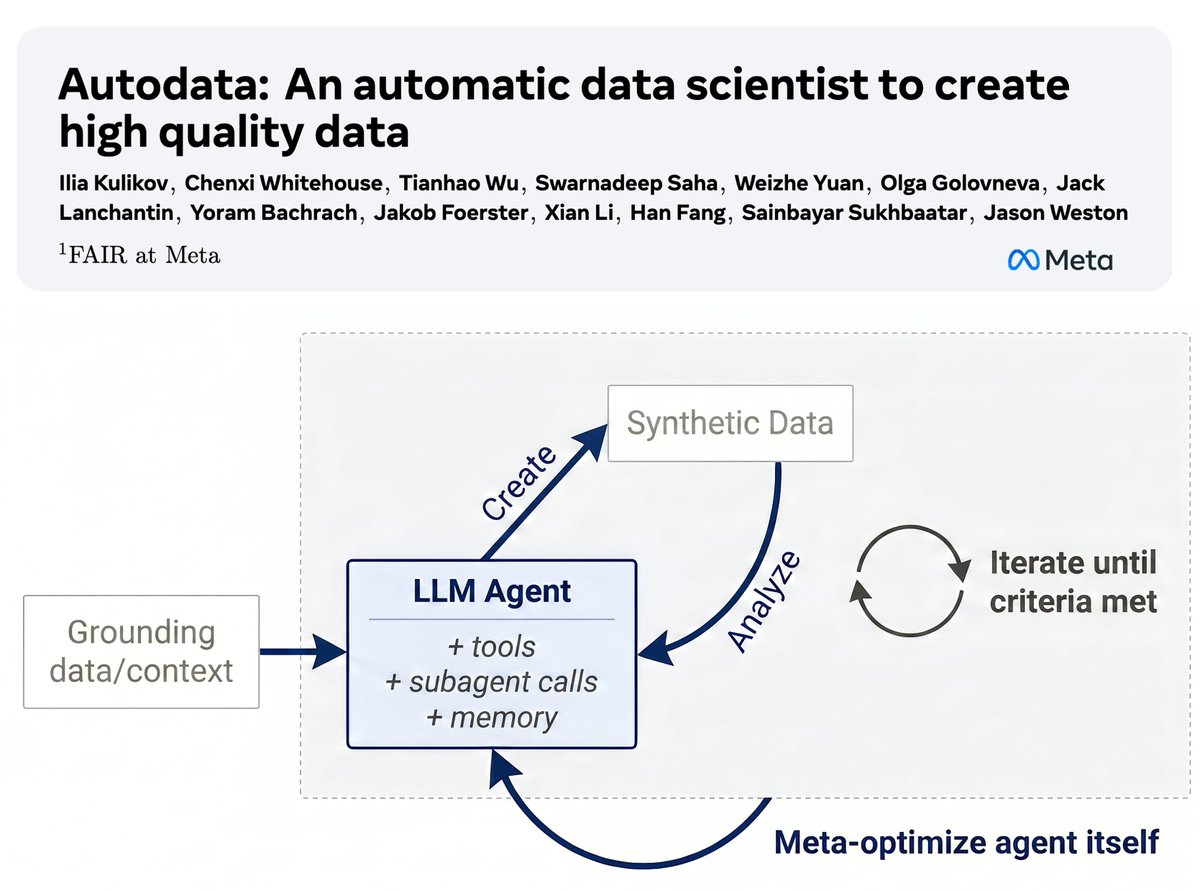
💎Autodata: an agentic data scientist to create high quality data✨
We introduce a method for building agents that create high-quality training & evaluation data.
Key idea: agentic data creation provides a way to *convert increased inference compute into higher quality model training*.
We show how to train (meta-optimize) such a data scientist agent, so that it can create even stronger data.
Our initial study with a specific practical implementation, Agentic Self-Instruct, shows strong gains on scientific reasoning problems compared to classical synthetic dataset creation methods.
Overall, we believe this direction has the potential to change how we build AI data!
Read more in the blog post: https://t.co/vjPvnTYfJx
Hi Will, it's a super cool blog! I love and agree with most of the insights, especially on viewing the teacher in on-policy distillation as an optimization problem. But I have one question: why is the concrete and biased gradient in OPSD an issue? Can we just increase the batch size to get concrete but stable optimization?
Super cool blog! I love and agree with most of the insights, especially on viewing the teacher in on-policy distillation as an optimization problem. But I have one question: why is the concrete and biased gradient in OPSD an issue? Can we just increase the batch size to get concrete but stable optimization?
Agree! And I think it’s easier to balance multiple domains. You can “overfit” each domain with own special model to some extend and then distill them into one model and control the training based on the unified model’s performance gap with each special model, similar to model merging.
Agree! And I think it’s easier to balance multiple domains. You can “overfit” each domain with own special model to some extend and then distill them into one model and control the training based on the unified model’s performance gap with each special model, similar to model merging.
Feel this might be the future. Training domain-specific models via RL and then on-policy distill them into a unified model. I think it’s more stable than directly training the model on various domains and environments?
post-training/RL details of deepseek-v4:
i) they replace the mixed RL stage used in deepseek v3.2 with on-policy distillation. they still use RL but RL is mainly used to create strong domain specialists first. then they consolidate those specialists into one final model through OPD.
ii) for each domain they start with supervised fine-tuning on high-quality domain-specific data. after that they run RL using GRPO guided by domain-specific prompts and reward signals. the paper does not provide all reward formulas but the important structural point is that each specialist gets its own domain-conditioned reward distribution.
iii) deepseek-V4 supports three explicit reasoning modes: non-think, think high & think max. they trained distinct specialist models under different RL configurations to support different reasoning capacities. for each mode they apply different length penalties and context windows during RL training which changes the model’s output reasoning length.
iv) one of the more interesting parts is for hard-to-verify tasks they say they discard conventional scalar reward models and instead use a Generative Reward Model or GRM. they curate rubric-guided RL data and use a GRM to evaluate policy trajectories. crucially they apply RL optimization directly to the GRM itself and the actor network natively functions as the GRM (that means the same model family is learning both generation and evaluation...i guess this is closer to LLM-as-judge trained with RL...implicitly moving from reward-as-score to reward-as-deliberative-evaluation).
v) deepseek-v4 treats long-horizon tool use as a state-retention problem...instead of flushing reasoning after every user/tool boundary it preserves the full reasoning trace across agentic tool conversations, making context management part of the trained policy interface.
vi) also it collapses auxiliary routing decisions search/no-search, query generation, domain classification, URL reading, etc. into special tokens appended to the main model context...reusing the existing KV cache instead of paying redundant prefill for separate router/controller models.
vii) deepseek-v4 uses full-vocabulary logit distillation. that means instead of only comparing teacher and student on the sampled token they compare the full probability distribution over the vocabulary at each position.
viii) for agentic post-training and evaluation, deepseek builds DeepSeek Elastic Compute (DSec). it is a production-grade sandbox platform with three rust components: a) apiserver b) edge c) watcher...these communicate through custom RPC and scale over deepseek’s 3FS distributed filesystem...the paper says a single DSec cluster manages hundreds of thousands of concurrent sandbox instances...also for each sandbox DSec keeps a globally ordered trajectory log recording every command and result.
ix) the paper does not go in full details of async-rl...it focuses more on fault-tolerant asynchronous execution than on off-policy correction under stale rollouts (also on RL/OPD execution). it does not fully reveal the behavior-policy staleness semantics of the RL/OPD loop.
Static models won’t win against dynamic environments.
Adaptable AI will.
Systems that learn during use, not after the fact, are the ones that scale.
Everything else falls behind.
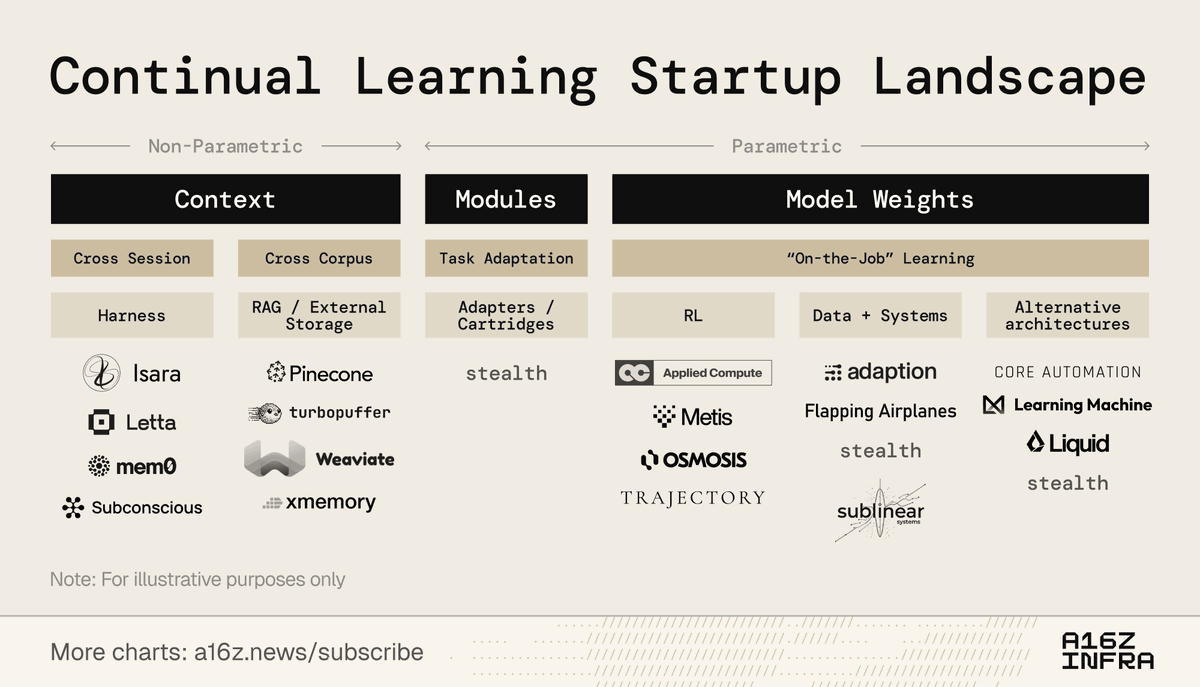
@a16z mapped who's building on that. @adaption is in it.
Excited to share that I’ll be heading to #ICLR2026 in Rio 🇧🇷!
I’ll be presenting two papers related to evaluating risks in computer-use agents (CUAs), centered on:
Agent Security (RedTeamCUA, Main Conference Oral):
We introduce a framework for realistic, controlled adversarial testing of CUAs with a hybrid Web-OS sandbox, revealing consistent vulnerabilities in frontier CUAs to indirect prompt injection across Web-OS attack pathways.
Agent Safety (AutoElicit, AIWILD Workshop Spotlight):
We develop the first agentic framework for automatically eliciting unintended behaviors from realistic CUA contexts, proactively surfacing unsafe behaviors that emerge inadvertently from benign inputs.
As agents become more capable, rigorously evaluating both security and safety risks is essential for real-world deployment.
Looking forward to sharing and discussing in Rio - more details below 👇
My new reflection: Language, Curiosity, and Life.
It is my attempt to put into words what has mattered most to me: language, family, curiosity, music, work, illness, and gratitude.
This is not a goodbye. I hope the conversation continues.
https://t.co/0i0N3GrteM
Dear Friends, this is Masato's wife Lynn typing. It is with a heavy heart that I share that Masato passed away peacefully yesterday. Thank you for keeping him in your thoughts. You can follow this page for memorial details: https://t.co/0Fgqa1RCaE
What if computer-use agents could do real work?
We built Gym-Anything: a framework that turns any software into a computer-use agent environment.
We used it to create CUA-World: 200+ real software, 10,000+ tasks and environments, across all major occupation groups, from medical imaging to financial trading.
🧵
@gabriberton I view this as a form of test-time scaling or training. It works by enhancing the task-related distribution. But I guess you would need to reset the weights to use the model for other tasks. It is still very useful if we want task-specific models.
@gabriberton I view this as a form of test-time scaling or training. It works by enhancing the task-related distribution. But I guess you would need to reset the weights to use the model for other tasks. It is still very useful if we want task-specific models.