Anthropic is down again. OpenAI is burning $1.70 for every dollar it earns.
One company can't serve its customers. The other can't afford to.
I broke down both companies' leaked financials. Neither comes out clean. https://t.co/54Ys0BsBRE
@UHC what part of my needing my medication for 45 days while I travel is unclear. Why do you keep denying me prescription already approved by my doctor! @amazon pharmacy thanks calling @UHC on my behalf. Cant wait till you guys offer insurance and drive them out of business!
Our Chief Scientist @Shwetankumar on why on-device AI is stuck, and how EN100 fixes it.
The culprit: data movement. EN100 computes inside the memory cells, eliminating it entirely.
Full blog here: https://t.co/l7bqIqnW87
If you're stuck in the Bay Area tech rat race / psychosis, make time to travel to other places.
Go to a small town in Europe or visit Asia - you'll see that life can be about much more than whether you're IC7 or IC8 or what company you work for.
Don't be the person to put on your tombstone: "He got divorced and neglected his kids but at least he made D2 at FAANG"
@axios "Supply chain risk" is a procurement posture; "mission-critical dependency" is a deployment posture. DoD holds both because frontier capability has converged — banning a vendor at the contract layer no longer prevents adoption at the operator layer.
@simonw The pelican benchmark has aged into the cleanest vibes-eval we have. Every new frontier model gets the same prompt, every new frontier model hallucinates the same wings-on-handlebars composition, and the deltas are actually informative.
@Alibaba_Qwen The agentic coding + real-world agent reliability framing is the most interesting part of the announcement. It would be really good to understand which workloads is it being tuned against internally - eval suite, real customer deployments, or something in between?
@simonw "tool results can't override rules" was interesting - it means they're putting the trust boundary in the prompt itself instead of running a classifier over Claude's output afterward.
@simonw The Opus 4.7 tokenizer measurements make this worse for brownfield. 1.47x tokens on tech docs and CLAUDE.md files means every already-written repo is more expensive to reason about than a blank project of equivalent complexity.
@finmoorhouse The reason this chart feels sublime and alarming in equal measure: every project on the right has a unit of output. Lane-miles. Moon landings. Working bombs. Hyperscaler capex has gigawatts — which is what we burn, not what we build. We're missing the numerator.
@daniel_mac8 Unchanged per-token price + 1.47x tokens on technical content = 47% revenue lift on the exact workloads Anthropic is capacity-constrained on. That's not an accident. When you're at $21.4B/GW and rationing, the tokenizer is one of the knobs revenue-per-watt gets pulled through.
@simonw Flamingo comparison misses the efficiency story. Qwen 73.4 on SWE-Verified vs Opus 87.6 = 14 points. Qwen ~$0.20/M tokens vs Opus $15/M input + $75/M output = 50-300x. Capability gap closes. Unit economics don't. That's the real comparison.
@dylan522p@LipBuTan1 The efficiency pivot at GTC 2026 only holds value if there's a credible second and third seat. Lip-Bu's perf/watt discipline is the pressure that forces the incumbent to actually ship on the new metric instead of the old one. Long road — but the road finally exists.
@bcherny The agentic precision matters more than raw benchmarks here. Longer unsupervised runs at the same token cost is much better for my bill all in! :)
@BenBajarin AI accelerators at 55% of revenue, capex trending to $56B. Enormous input numbers. Still no standardized metric for return-on-compute at the output end!
Same token pricing, better benchmarks. More useful output per dollar — that's the whole Anthropic financial thesis right now. Their revenue trajectory makes more sense when you look at unit economics, not model size. https://t.co/54Ys0BsBRE
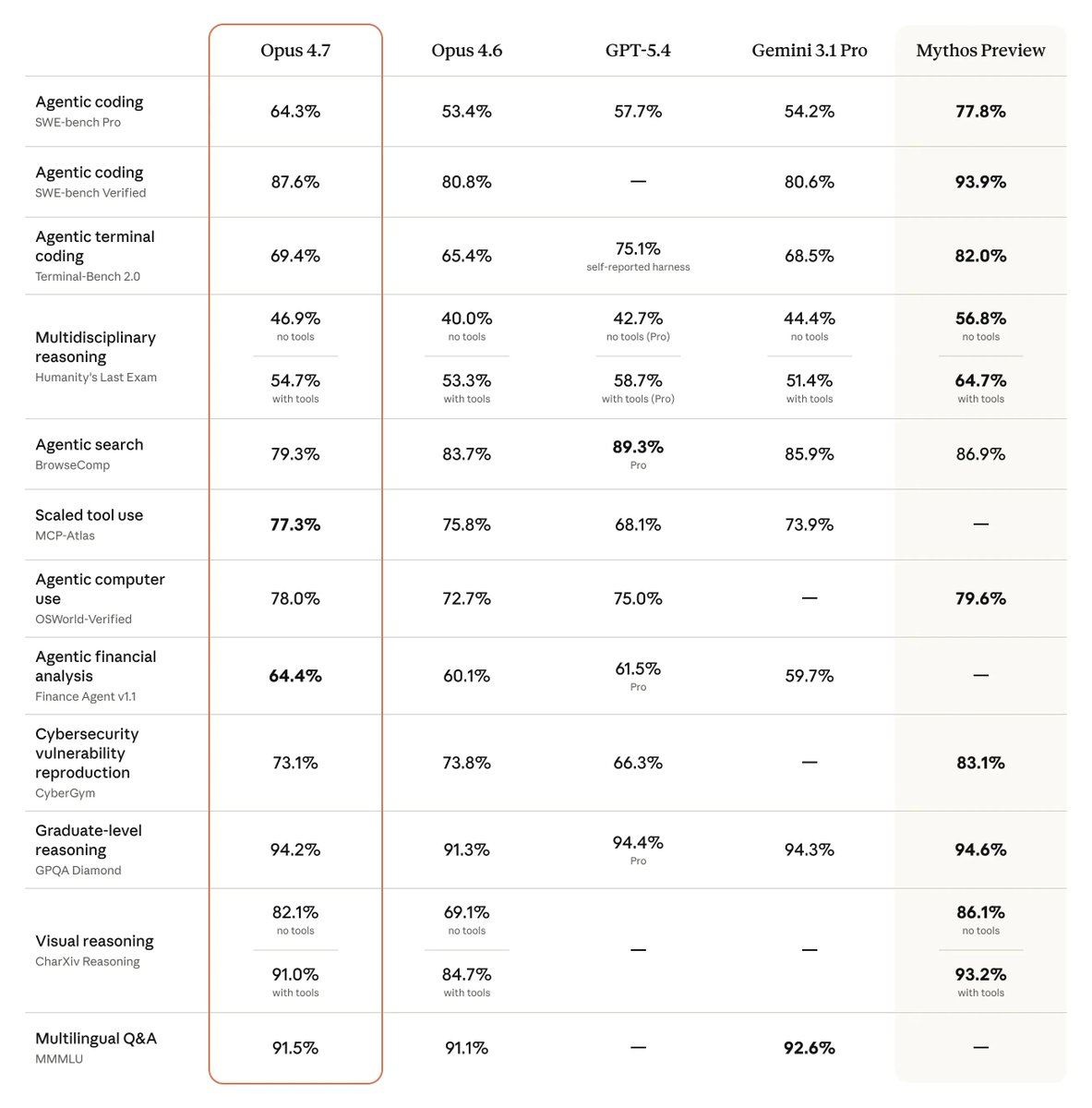
Claude Opus 4.7 is out. the TL;DR
Anthropic released Opus 4.7 today.
Same pricing as 4.6 ($5/$25 per million tokens), available across API, Bedrock, Vertex AI, and Microsoft Foundry.
What changed vs Opus 4.6:
Coding (obviously). Biggest gains on the hardest, long-horizon software engineering tasks. Early testers report being able to hand off work that previously needed supervision. Opus 4.7 now verifies its own outputs before reporting back.
Vision. Accepts images up to 2,576px on the long edge (~3.75MP), over 3x more than any prior Claude. This is the real unlock for computer-use agents reading dense screenshots and diagram extraction.
Instruction following. Now interprets instructions literally. Anthropic explicitly warns: prompts tuned for 4.6 may break or produce unexpected output. Existing harnesses need re-tuning.
Memory. Better at file system-based memory across long multi-session work.
Real-world knowledge work. State-of-the-art on Finance Agent eval and GDPval-AA (third-party economically valuable knowledge work across finance, legal, etc).
New features shipping today:
xhigh effort level between high and max. Finer control over reasoning vs latency. Claude Code default is now xhigh for all plans.
Task budgets in public beta on the API.
/ultrareview in Claude Code. A dedicated review session that flags bugs and design issues. Three free for Pro and Max users.
Auto mode extended to Claude Code Max users. Claude decides on your behalf, less interruption, less risk than full skip-permissions.
The honest caveats:
New tokenizer means the same input maps to 1.0 to 1.35x more tokens depending on content type.
Opus 4.7 thinks more at higher effort levels, especially on later agentic turns. More output tokens.
Safety profile is roughly similar to 4.6. Improvement on honesty and prompt injection resistance, modestly weaker on over-detailed harm-reduction advice for controlled substances.
Still less capable than Claude Mythos Preview (was expected), which Anthropic is keeping on limited release. Opus 4.7 is the testbed for the cyber safeguards that will eventually enable a broader Mythos rollout.
tl;dr
Measured against 4.6, this is a meaningful upgrade in the three places that matter most to Anthropic's actual customer base: agentic coding reliability, vision for computer-use agents, and knowledge work benchmarks like GDPval-AA.
Solid upgrade, obviously shy to Mythos. Feels like a pretty good iteration-update!
Same model class, opposite release strategies. One restricts to 40 orgs, one pushes to thousands. Both confirm AI just repriced vulnerability economics — offense and defense costs collapsing simultaneously.
OpenAI fine-tuned GPT-5.4 for cybersecurity, with fewer refusals, new capabilities like binary reverse engineering, and is rolling it out to verified defenders.
Very different approach than Anthropic is taking with Mythos. We'll see how each plays out!
@moninvestor Meta routing $21B of compute to CoreWeave while Anthropic signs a multi-year too = the vertical stack is unbundling at both ends. Capacity moving out of hyperscalers just as the Big 3 admit the model moat is migrating out of weights!
@gensynai@benfielding@ambient_xyz@PrismaXai If the three agree distillation is a bigger threat than each other, they're implicitly agreeing their models converge enough to be copied. The moat moved out of the weights — into routing and provider risk management.