ICLR has placed OpenReview in a difficult position, so I want to offer a few words about the OpenReview team working behind the scenes.
OpenReview has long been operated at UMass Amherst as a non-profit organization founded by Andrew McCallum. Each year, Andrew must raise more than $2 million to support a 20-person team that provides essential infrastructure for most major conferences.
I once asked Andrew what might have been a naïve question: whether he had considered developing a business model for OpenReview, given its prominence and the seemingly obvious opportunities. He pushed back, explaining that everything he has done for OpenReview is driven by a commitment to serve and strengthen the academic community. He is willing to devote significant personal effort to ensure the platform remains freely accessible to all.
We should not blame such a brilliant and dedicated team for an accidental issue. Otherwise, fewer people would be willing to shoulder this kind of responsibility in the future.
Deep respect to the OpenReview team! I’m grateful for their work and happy to support in any way!
This guy dropped the “best US open-weight model” — which is fine-tuned on a Deepseek base model — then proceed to thank a bunch of open-source orgs, not including Deepseek AI. Shameless...
4/ For Cogito v2.1, we fork off the open-licensed Deepseek base model from November 2024. This is an obvious choice for a pretrained base model, as Deepseek architecture has an ecosystem of cheap inference built around it.
We have built a frontier training stack, while being an early stage startup, since we can stand on the shoulders of open source champions like @huggingface, @togethercompute, @runpod and @nebiusai, as well as stellar contributions by @Microsoft, @Meta, @nvidia and a lot of other folks in open source.
Over the last months, we have iterated and refined our post-training strategies of self-play + RL (called Iterated Distillation and Amplification - IDA) with Cogito v1 and v2.
You will see high-quality responses from Cogito v2.1 while being a bit different from usual models - we increase the model’s intelligence prior and teach it how to think via process supervision. So there are significantly shorter reasoning chains for the responses. We also use less markdown, less verbosity.
In short, we want to make the model great for API usage - faster, fewer tokens with super high quality.
🚀Excited to announce that the ERNIE 4.5 series models are officially open-sourced today!
🙌ERNIE 4.5 models achieved state-of-the-art performance across multiple text and multimodal benchmarks, especially in instruction following, world knowledge memorization, visual understanding and multimodal reasoning. ERNIE 4.5 models are trained using PaddlePaddle, achieving 47% MFU in the pre-training of the largest ERNIE 4.5 language model.
ERNIE 4.5 models include 10 models, consist of MoE models with 47B and 3B active parameters, with the largest model having 424B total parameters, as well as a 0.3B dense model.
Try it now👉https://t.co/531t0rVSWZ
Hugging Face: https://t.co/xZHzlXh8UX
GitHub: https://t.co/QkcxLgChbK
AI Studio: https://t.co/Gyak0JYlLD
Introducing ERNIE X1 Turbo & ERNIE 4.5 Turbo!
Building on the success of ERNIE X1 and 4.5, the upgraded ERNIE X1 Turbo and 4.5 Turbo deliver results faster and cheaper. Both models stand out for their multimodal capabilities, strong reasoning and low costs.
For X1 Turbo, input and output prices start at $0.14 per 1M tokens and $0.55 per 1M tokens, respectively, priced at approximately 25% of DeepSeek R1. #BaiduCreate2025
(Exchange rate used: 1 RMB ≈ 0.14 USD)
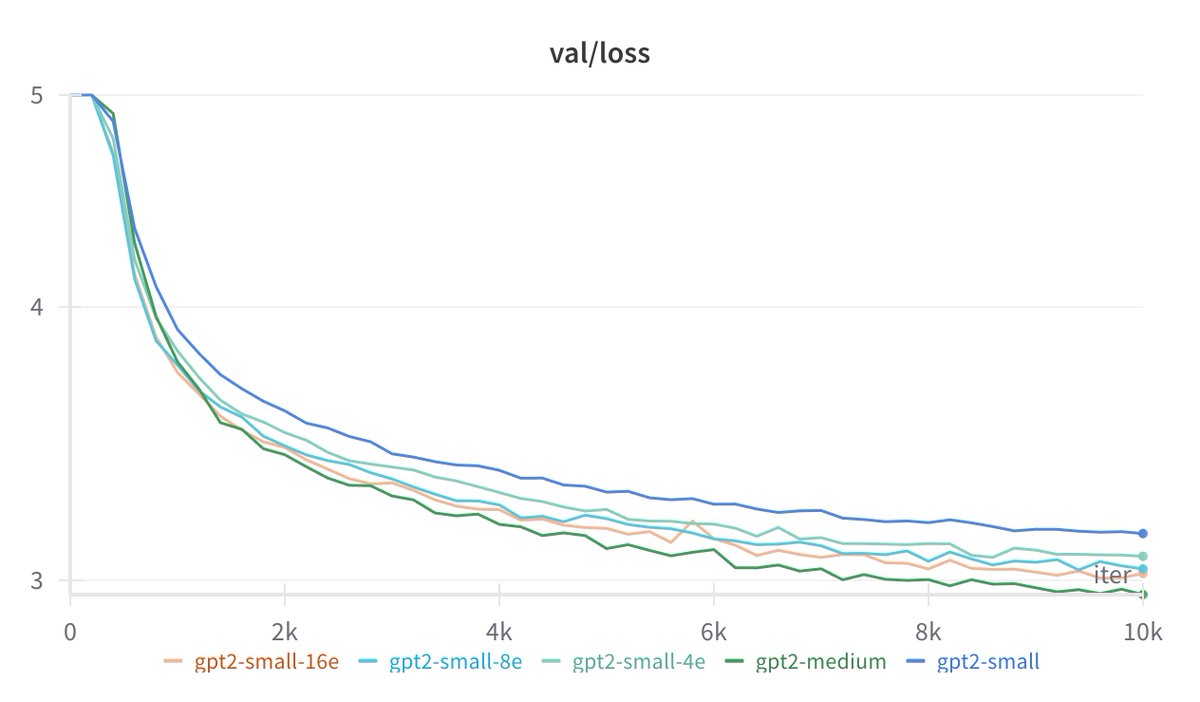
@karpathy Wrote up my observations and implementation notes at https://t.co/jSgJa9qknA. The code is available at https://t.co/ongR8kF2uM - an implementation that prioritizes clarity over efficiency
Weekend hack: extended @karpathy's nanoGPT to play with MoE architecture! Despite being GPU-poor, I was able to validate some key insights from the Switch Transformers paper with my humble experiments. Learned a ton about scaling MoE and expert imbalance in the process.
# RLHF is just barely RL
Reinforcement Learning from Human Feedback (RLHF) is the third (and last) major stage of training an LLM, after pretraining and supervised finetuning (SFT). My rant on RLHF is that it is just barely RL, in a way that I think is not too widely appreciated. RL is powerful. RLHF is not. Let's take a look at the example of AlphaGo. AlphaGo was trained with actual RL. The computer played games of Go and trained on rollouts that maximized the reward function (winning the game), eventually surpassing the best human players at Go. AlphaGo was not trained with RLHF. If it were, it would not have worked nearly as well.
What would it look like to train AlphaGo with RLHF? Well first, you'd give human labelers two board states from Go, and ask them which one they like better:
Then you'd collect say 100,000 comparisons like this, and you'd train a "Reward Model" (RM) neural network to imitate this human "vibe check" of the board state. You'd train it to agree with the human judgement on average. Once we have a Reward Model vibe check, you run RL with respect to it, learning to play the moves that lead to good vibes. Clearly, this would not have led anywhere too interesting in Go. There are two fundamental, separate reasons for this:
1. The vibes could be misleading - this is not the actual reward (winning the game). This is a crappy proxy objective. But much worse,
2. You'd find that your RL optimization goes off rails as it quickly discovers board states that are adversarial examples to the Reward Model. Remember the RM is a massive neural net with billions of parameters imitating the vibe. There are board states are "out of distribution" to its training data, which are not actually good states, yet by chance they get a very high reward from the RM.
For the exact same reasons, sometimes I'm a bit surprised RLHF works for LLMs at all. The RM we train for LLMs is just a vibe check in the exact same way. It gives high scores to the kinds of assistant responses that human raters statistically seem to like. It's not the "actual" objective of correctly solving problems, it's a proxy objective of what looks good to humans. Second, you can't even run RLHF for too long because your model quickly learns to respond in ways that game the reward model. These predictions can look really weird, e.g. you'll see that your LLM Assistant starts to respond with something non-sensical like "The the the the the the" to many prompts. Which looks ridiculous to you but then you look at the RM vibe check and see that for some reason the RM thinks these look excellent. Your LLM found an adversarial example. It's out of domain w.r.t. the RM's training data, in an undefined territory. Yes you can mitigate this by repeatedly adding these specific examples into the training set, but you'll find other adversarial examples next time around. For this reason, you can't even run RLHF for too many steps of optimization. You do a few hundred/thousand steps and then you have to call it because your optimization will start to game the RM. This is not RL like AlphaGo was.
And yet, RLHF is a net helpful step of building an LLM Assistant. I think there's a few subtle reasons but my favorite one to point to is that through it, the LLM Assistant benefits from the generator-discriminator gap. That is, for many problem types, it is a significantly easier task for a human labeler to select the best of few candidate answers, instead of writing the ideal answer from scratch. A good example is a prompt like "Generate a poem about paperclips" or something like that. An average human labeler will struggle to write a good poem from scratch as an SFT example, but they could select a good looking poem given a few candidates. So RLHF is a kind of way to benefit from this gap of "easiness" of human supervision. There's a few other reasons, e.g. RLHF is also helpful in mitigating hallucinations because if the RM is a strong enough model to catch the LLM making stuff up during training, it can learn to penalize this with a low reward, teaching the model an aversion to risking factual knowledge when it's not sure. But a satisfying treatment of hallucinations and their mitigations is a whole different post so I digress. All to say that RLHF *is* net useful, but it's not RL.
No production-grade *actual* RL on an LLM has so far been convincingly achieved and demonstrated in an open domain, at scale. And intuitively, this is because getting actual rewards (i.e. the equivalent of win the game) is really difficult in the open-ended problem solving tasks. It's all fun and games in a closed, game-like environment like Go where the dynamics are constrained and the reward function is cheap to evaluate and impossible to game. But how do you give an objective reward for summarizing an article? Or answering a slightly ambiguous question about some pip install issue? Or telling a joke? Or re-writing some Java code to Python? Going towards this is not in principle impossible but it's also not trivial and it requires some creative thinking. But whoever convincingly cracks this problem will be able to run actual RL. The kind of RL that led to AlphaGo beating humans in Go. Except this LLM would have a real shot of beating humans in open-domain problem solving.
LLM bullshit knife, to cut through bs
RAG -> Provide relevant context
Agentic -> Function calls that work
CoT -> Prompt model to think/plan
FewShot -> Add examples
PromptEng -> Someone w/good written comm skills.
Prompt Optimizer -> For loop to find best examples.
Vinod, Chinese companies are very much on top of it already.
Many have already developed their own home-grown LLMs from scratch.
They're not far behind and they have some original ideas that could actually be useful to the rest of the world.
They don't want to "steal" Western technology because (1) they don't need to, (2) they want sovereignty, (3) they want control.
It’s the origin of attention!
@DBahdanau & @kchonyc couldn’t afford Google’s large multi-GPU neural MT, so they thought of a better way.
Us either. @lmthang & @chrmanning introduced simpler multiplicative attention.
Then @GoogleAI folk wondered if attention is all you need…
Today is a huge milestone for one of our latest libraries: Text Generation Inference - we released v1.0 and under a new license: HFOIL 1.0
https://t.co/7OTgLyM8T3
This 🧵 explains what this new license means, and why the change!
Today we say goodbye to this great blue bird
This logo was designed in 2012 by a team of three. @toddwaterbury, @angyche and myself,
The logo was designed to be simple, balanced, and legible at very small sizes, almost like a lowercase "e", a 🧵
New Post: Sharing some thoughts on the emerging tech stack of generative AI.
LLMs != AI System != AI Product
Thin wrappers are being built every day, but are they sufficient for vertical SaaS applications? Let's unpack 👉🚀 @cresta#GenerativeAI#GPT4
https://t.co/AEmK76YGh5