There’s been lots of interest in LLM calibration over the last few years, especially recently for reasoning LLMs.
But most methods still require labeled data or extra inference-time compute. Sometimes we’re not that lucky: e.g., a personalized QA assistant running on-device still needs calibrated confidence, but may not have ground-truth labels or the resources to generate lots of extra tokens.
That’s exactly the challenge we address in our new paper: “Unsupervised Confidence Calibration for Reasoning LLMs from a Single Generation”
There’s been lots of interest in LLM calibration over the last few years, especially recently for reasoning LLMs.
But most methods still require labeled data or extra inference-time compute. Sometimes we’re not that lucky: e.g., a personalized QA assistant running on-device still needs calibrated confidence, but may not have ground-truth labels or the resources to generate lots of extra tokens.
That’s exactly the challenge we address in our new paper: “Unsupervised Confidence Calibration for Reasoning LLMs from a Single Generation”
We tested this pretty extensively, generating over 5B tokens across 9 reasoning models (from 600M to 14B) and 5 tasks spanning math, science and open-domain QA.
Our approach substantially outperforms unsupervised baselines based on token probabilities or verbalized confidence (which itself requires extra compute). It also remains strong under distribution shift, works in a black-box setting or without generating a response, and improves downstream decision-making in selective prediction and simulated linguistic calibration.
@iaindunning I think if you have data and the task is narrow then smaller models might do the trick, eg you don’t need gpt-X to do sentiment analysis on customer reviews or intent classification on service requests. (But your customer assistant chatbot will have to be gpt-X).
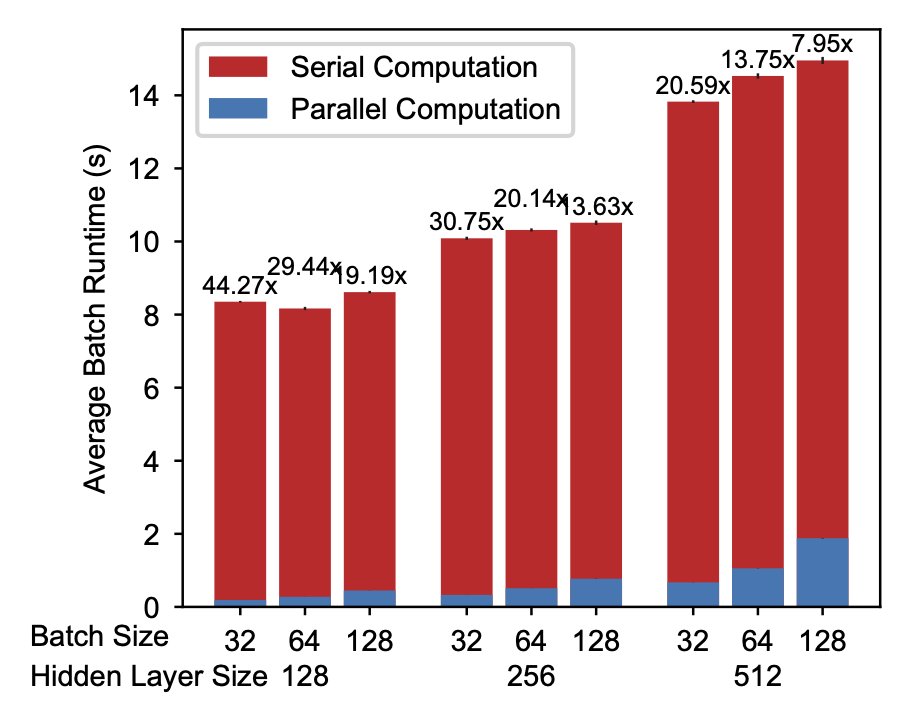
Our new preprint on parallelizing training of temporally precise spiking neural networks is out!
We show up to 44x speedups over a conventional sequential baseline. 1/N
When I started the VLA calibration project early in 2025, OpenVLA was pretty much the only model that I could use. Since then a bunch of new token-based VLAs have come out, so we updated our paper with new experiments on 4 VLAs.
New models include MolmoAct from @jason_lee328@allen_ai, NORA from @hungchiayu123, and UniVLA from @bqwluckyone@OpenDriveLab
Updated results show that the accuracy vs. calibration relationship may be dependent on model architecture and training objective, and that our approaches to prompt ensembling, action scaling, and time-aware monitoring generalize across models.
We propose a framework that combines:
- LLM-based expected information gain for scoring candidate questions
- Heterogeneous GNN propagation to aggregate responses and attributes
- Per-round adaptive respondent selection under explicit budgets
By querying a small, informative subset of individuals, the model infers population-level responses through structured similarity.
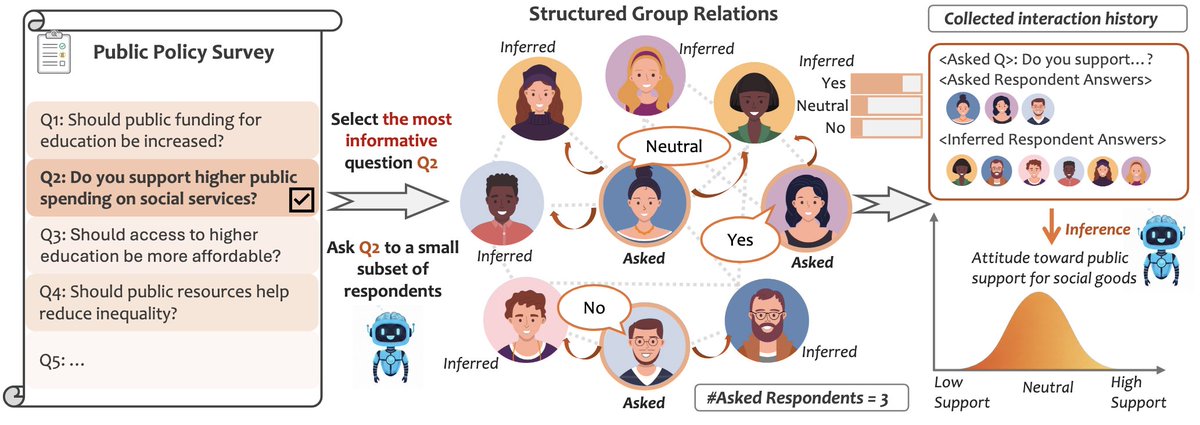
Last year we published our work on teaching an LLM to select questions to most efficiently gather information about an individual.
What's a natural follow-up? How about selecting questions and individuals to most efficiently gather information about a group!
@ding_ruomeng@zhun_deng@zemelgroup We study a new problem setting: Adaptive Group Elicitation. Under real costs and missing data, the system must dynamically decide:
👉 ❓ Which question to ask
👉 👥 Which individuals to query
👉 🌐 How to leverage population structure to infer unobserved responses
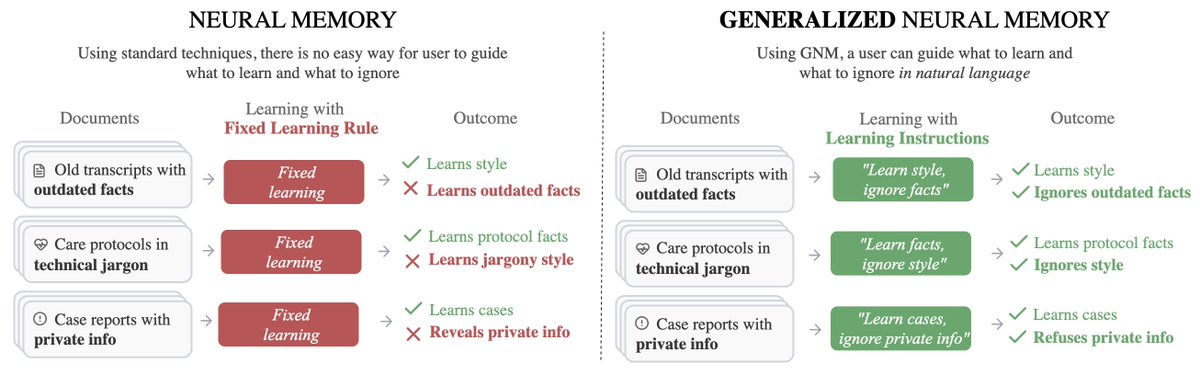
Super psyched to finally share our new continual learning paper “Tell Me What To Learn: Generalizing Neural Memory to be Controllable in Natural Language”