ByteDance just published something I've been waiting for someone to build: CUDA Agent!
It trained a model that writes fast CUDA kernels. Not just correct ones — actually optimized ones.
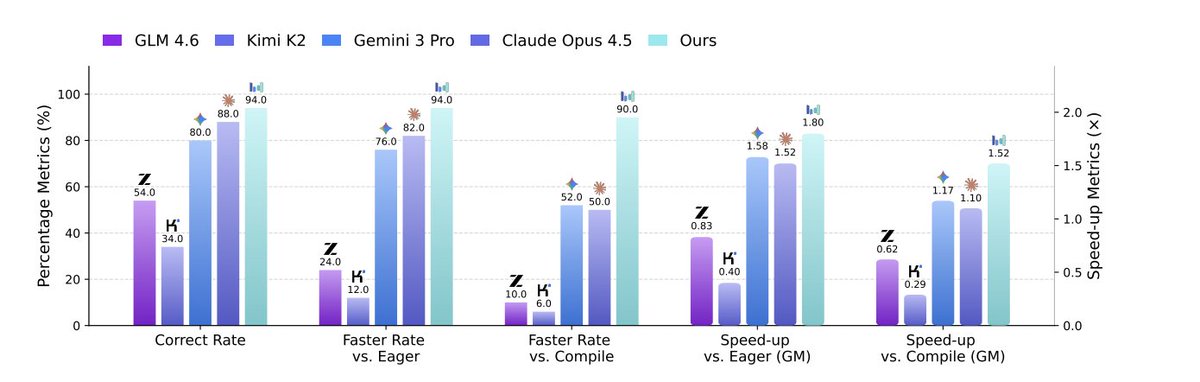
It beats torch.compile by 2× on simple/medium kernels, ~92% on complex ones, and even outperforms Claude Opus 4.5 and Gemini 3 Pro by ~40% on the hardest setting.
The key idea is simple but kind of brilliant:
CUDA performance isn’t about correctness, it’s about hardware. Warps, memory bandwidth, bank conflicts — the stuff you only see in a profiler.
So instead of rewarding “did it compile?”, they reward actual GPU speed. Real profiling numbers. RL trained directly on performance.
That’s a big shift.
Paper: https://t.co/EYx7QKosgk
Project: https://t.co/pTCfzQIBes
Agent memory benchmarks are misleading.
Scoring well on memory recall doesn't mean an agent can actually use that memory to take correct actions across sessions.
Models that achieve near-saturated performance on existing long-context memory benchmarks like LoCoMo perform poorly when tested in real agentic scenarios.
This new research introduces MemoryArena, a benchmark designed to evaluate agent memory across interdependent multi-session tasks.
Unlike existing benchmarks that test memorization separately from action or focus on single sessions, MemoryArena uses human-crafted agentic tasks where agents must learn from prior interactions and apply that knowledge to solve subsequent challenges.
Why it matters: as agents handle longer, multi-session workflows, memory isn't just about retrieval. It's about applying the right context at the right time to make good decisions.
Paper: https://t.co/PQpmsZVCvr
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
Many are trying to code with agents to boost velocity.
But at what cost?
The default assumption is that AI coding tools are additive: IDE assistants help, and autonomous agents help more. Stack them together, get more productivity.
But nobody had measured whether this is actually true in production repositories.
This new research presents the first large-scale causal study of autonomous coding agent adoption in open-source projects, analyzing repository-level outcomes across development velocity and software quality.
The methodology: staggered difference-in-differences with matched controls using the AIDev dataset.
Repositories are split into two groups: agent-first (AF), where agents are the first AI tool adopted, and IDE-first (IF), where repositories already used AI IDEs like Copilot or Cursor before adopting agents.
AF repositories see massive front-loaded gains: +36% commits and +77% lines added on average. At adoption month, the spike hits +111% commits and +216% lines added. These gains persist.
But IF repositories see almost nothing: +4% commits and +1% lines added. The short-lived bump at adoption quickly fades, and by month 6, lines added turn negative (-45%).
The quality findings are worse. Regardless of prior AI exposure, agent adoption increases static-analysis warnings by ~18% and cognitive complexity by ~35%. These effects are persistent. AF repositories reach +49% complexity by month 5. IF repositories hit +44-51% and stay there.
Autonomous agents introduce complexity debt even when velocity advantages fade. Teams already using AI IDEs face coordination and integration bottlenecks that limit throughput, but still accumulate the maintainability risks.
Coding agents are powerful but risky accelerators. Substantial velocity gains materialize only when agents are a project"s first AI tool. Prior AI IDE exposure moderates the benefits but not the quality risks. Selective deployment and strong quality safeguards are essential.
Paper: https://t.co/6lVAuUPxvh
Learn to build with AI agents in our academy: https://t.co/zQXQt0PMbG